(1)预编译
主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下:
删除所有的#define,展开所有的宏定义。处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其
他文件。删除所有的注释,“//”和“/**/”。保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件
被重复引用。添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是
能够显示行号。
(2)编译
把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应
的汇编代码文件。
词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分
割成一系列的记号。语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的
语法树是一种以表达式为节点的树。语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进
行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能
确定的语义。优化:源代码级别的一个优化过程。目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语
言表示。目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移
来替代乘法运算、删除多余的指令等。
(3)汇编
将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没
有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过
来,汇编过程有汇编器as完成。经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Windows 下)、xxx.obj(Linux下)。
(4)链接
将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链
接:
静态链接
函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库
中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。
以下面这个图来简单说明一下从静态链接到可执行文件的过程,根据在源文件中包含的头文件和程序中使用到的库函数,如stdio.h中定义的printf()函数,在libc.a中找到目标文件printf.o(这里暂且不考虑printf()函数的依赖关系),然后将这个目标文件和我们hello.o这个文件进行链接形成我们的可执行文件。
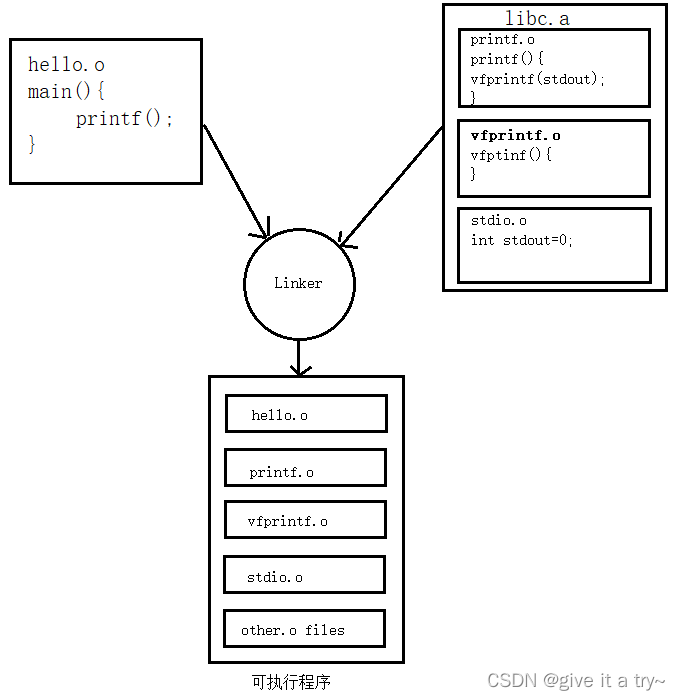
这里有一个小问题,就是从上面的图中可以看到静态运行库里面的一个目标文件只包含一个函数,如libc.a里面的printf.o只有printf()函数,strlen.o里面只有strlen()函数。
我们知道,链接器在链接静态链接库的时候是以目标文件为单位的。比如我们引用了静态库中的printf()函数,那么链接器就会把库中包含printf()函数的那个目标文件链接进来,如果很多函数都放在一个目标文件中,很可能很多没用的函数都被一起链接进了输出结果中。由于运行库有成百上千个函数,数量非常庞大,每个函数独立地放在一个目标文件中可以尽量减少空间的浪费,那些没有被用到的目标文件就不要链接到最终的输出文件中。
缺点:
空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个
目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本;
更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,
在执行的时候运行速度快。
动态链接
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
假设现在有两个程序program1.o和program2.o,这两者共用同一个库lib.o,假设首先运行程序program1,系统首先加载program1.o,当系统发现program1.o中用到了lib.o,即program1.o依赖于lib.o,那么系统接着加载lib.o,如果program1.o和lib.o还依赖于其他目标文件,则依次全部加载到内存中。当program2运行时,同样的加载program2.o,然后发现program2.o依赖于lib.o,但是此时lib.o已经存在于内存中,这个时候就不再进行重新加载,而是将内存中已经存在的lib.o映射到program2的虚拟地址空间中,从而进行链接(这个链接过程和静态链接类似)形成可执行程序。
优点:
共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副
本,而是这多个程序在执行时共享同一份副本;更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
生成可执行文件
什么情况会编译成功但链接失败
(1)说明并使用了类型、函数、变量,但没给出相应类型、函数或变量的定义。关于说明和定义的区别见上述教程,说明可以通过#include头文件进行,也可以直接进行说明如int f( )或extern int f( )。若同时给出函数f的函数体则称为定义。对于变量若有初始值就算定义,例如"extern int x=3; "便是定义,这种语法有其独特应用背景。
(2)对标准库的连接失败,例如调用了sin(double x),却找不到数学运算标准库进行连接了,可能是安装后因各种可能原因被删除了。
(3)全局变量和静态变量存放在数据段,而固定大小的数据段不够用了,例如定义太多的全局变量和静态变量,甚至巨型数组全局或静态变量。
(4)数据段被偷用后无法容纳较多的全局变量和静态变量,这种错误最难发现且最难改正。主要是一些常量在偷用数据段,例如字符串常量"abc"等等,其它诸多情形参见上述教程。另外虚函数入口地址表等也会偷用。
到此这篇关于C/C++ - 从代码到可执行程序的过程的文章就介绍到这了,更多相关C++ 从代码到可执行程序的过程内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!