用7000字长文带你分析深圳二手房市场现况!
大家好,我是小一
今天的文章是一篇7000+字的数据分析实战,阅读全文大概需要10分钟,建议收藏!
今天的数据集来自于之前的爬虫项目:爬取城市二手房数据,今天的文章亦是对深圳存量二手房的一个分析实战。
文章会对深圳整体、各区域的二手房价格、二手房属性等多个维度进行探索,相信你会从中发现影响房屋价格的主要因素。如果你需要对某个二手房总价进行预测,文中也有一些数据处理的小技巧供你参考
今天的内容主要分为三部分,分别是:
数据预处理
可视化分析与探索
总结与延申
对了,如果你是早期就关注的读者,那你应该还记得公众号的第一篇数据分析实战文章:实战—我要租个好房
那篇文章是通过对深圳市的租房数据进行分析,最终找出了几个价格实惠、性价比又高的租房价值洼区,和今天的文章可以对照着看,很具有参考价值。
以下是正文:
数据预处理
本次房屋数据一共 29 个字段,38762 条数据。其中:
小区名称、行政区、区域、总价、单价等都是最常见的基本信息
户型、楼层、面积、建筑类型、房屋朝向、建筑结构等都是房屋的具体属性信息
挂牌时间、交易权属、上次交易时间、抵押信息等都是房屋的交易信息
经纬度是房屋所在的百度经纬度数据;
城市是额外新增的一个字段,本次均为:深圳
数据详情
先来看一下数据的分布情况

其中,区域数据有1条缺失,房协编码有32条缺失
缺失一条记录的可以直接补充,毕竟这个小区的具体地理区域还是很容易就能确定的。房协编码本次我们用不到,不考虑它的缺失情况
再来认识下数据的具体字段:

其中,参考总价、参考单价、建筑面积、套内面积 等都属于数值类型。因为在爬取数据的数据没有进行数据清洗,网站上是什么就存储成什么,这也是为了保护数据的真实性
但是在实际分析过程中,特别是建模中,这类数据通常都是存储成数值型,方便可视化的同时也能保证模型快速收敛。
所以在下一步处理的时候需要优先考虑处理数据类型
缺失数据清洗
先来查看区域缺失的那1条数据

通过查询,最近的小区分别是安鸿峰景苑和万科公园里,它两所在的区域标识是龙岗区的布吉南岭(如图所示),所以可以直接使用布吉南岭进行该字段缺失值的填充

注:上述打点的位置存在偏移,但能反映真实距离,所以未做经纬度偏移转换
补充一下,这个方法可以用于区域数据中大多数的缺失值填充。例如:房屋价格存在缺失,可以使用同一区域内的均价进行填充;房屋类型存在缺失,可以使用同一小区的其他房屋该字段的众数进行填充;多个房屋区域存在缺失,可以通过自定义距离函数计算最近的小区进行填充。
具体的内容可以多变,但是万变不离其宗,大家可以参考上述填充方法。
对应的填充代码如下:
# 区域缺失填充
df_data_2.loc[df_data_2.index == 28060, '区域'] = '布吉南岭'
异常数据清洗
在本次数据集中,存在很多不标准的数据格式,例如:房屋总价的单位、房屋面积等,我们暂且称之为异常数据
参考总价/单价处理
通过简单的汇总查看总价和单价分布情况

可以看到参考总价有两种形式,带单位的和不带单位的,一般处理都是直接确定成数值(方便在回归模型中应用)
同理,参考单价字段可以采用同样的处理方式。但是单价的单位是具体到元的,需要注意应该和总价的单位保持一致
ok,一行代码可以搞定:
# 统一单位
df_data_2['参考总价'] = df_data_2['参考总价'].apply(lambda x: x.replace("万", ""))
df_data_2['参考单价'] = df_data_2['参考单价'].apply(lambda x: int(x.replace("元/平米", ""))/10000)
df_data_2['参考总价'] = df_data_2['参考总价'].astype(dtype='float')
df_data_2['参考单价'] = df_data_2['参考单价'].astype(dtype='float')
需要注意原始数据类型默认是 Object,也就是字符类型,但是在我们处理之后已经变成了数值类型,所以在后续的处理中为了避免计算出错,直接将其格式进行转换。
更需要注意的是:总价的单位。因为发现有部分房屋的总价小于10w,谨慎起见把小于10w的房屋单独列出来观察一下
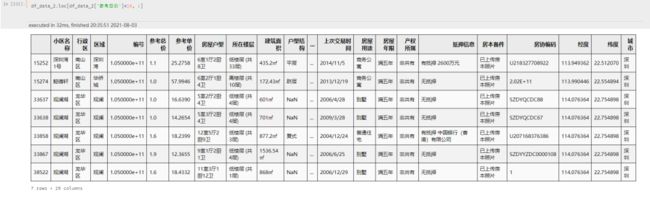
可以看到,并不是总价标错了,而是这些房屋总价的单位是亿,并不是w,所以需要对这部分房屋的总价进行处理
df_data_2.loc[df_data_2['参考总价']<10, '参考总价'] = df_data_2.loc[df_data_2['参考总价']<10, '参考总价']*10000
房屋户型处理
同样通过汇总的方式查看户型分布:
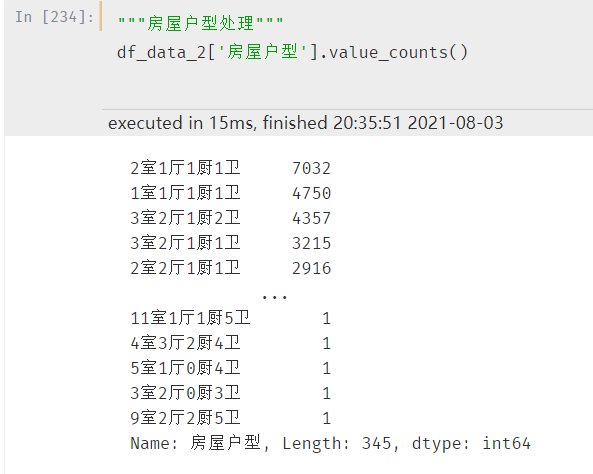
房屋户型的格式是:xx室xx厅xx厨xx卫,一共有345种户型布局。但是实际上并没有这么多,需要注意
一般我们在说户型的时候,都只是说 xx室xx厅,很少去关注后面的厨房和卫生间个数。
所以一种思路是只取前两个属性,另一种思路是把每一个属性的个数当做一个单独的字段(拆分下来也就是4个字段)
当然了上面所有属性的个数加在一起可以组成一个新的字段,至于这个字段对于模型具体有没有用最终可以通过贡献度来决定。
这里,我直接采用第一种思路
# 因为不确定xx室xx厅中的数字具体是几位数,所以采用正则匹配的方式
import re
df_data_2['房屋户型'] = df_data_2['房屋户型'].apply(lambda x: re.findall(r"\d+室\d+厅", x)[0])
房屋楼层处理
同样采用汇总的方式查看分布:

同样的可以用两种处理方式:一种是直接取描述性数据,例如中楼层、高楼层。一种是将通过总楼层,将对应的中楼层进行计算。
例如:总楼层是7层,1-2是低楼层、3-5是中楼层、6-7是高楼层
这样做的好处是将楼层的高度统一到一个层级,但是也会相对的失真,毕竟不同总高的楼总体价格都是差别很大的
这里,为了方便计算,直接采用第一种思路
# 注意分隔符,是:空格+左括号。细节!!!
df_data_2['所在楼层'] = df_data_2['所在楼层'].apply(lambda x: x.split(" (")[0])
房屋面积处理
同样采用汇总的方式查看分布:

将对应的 ㎡ 剔除掉,保证字段为数值类型
需要注意的是有部分数据为空的,官方标记的是“暂无数据”,这部分我们需要进行缺失值填充。填充的方式上面也有提到过,通过该房屋对应的户型,最好是同小区下对应的户型的建筑面积进行填充
另外,“套内面积”字段也是同样的情况,在此一并进行处理
主要代码如下:
# 统一单位
df_data_2['建筑面积'] = df_data_2['建筑面积'].apply(lambda x: x.replace("㎡", ""))
df_data_2['套内面积'] = df_data_2['套内面积'].apply(lambda x: x.replace("㎡", ""))
# 缺失值填充
df_data_2.loc[df_data_2['建筑面积']=='暂无数据', '建筑面积'] = df_data_2.loc[df_data_2['建筑面积']=='暂无数据', ['小区名称', '房屋户型', '建筑面积']].apply(lambda x: get_nan_info("小区名称", "房屋户型", x[0], x[1], df_data_2, target_col="建筑面积", target_value=x[2]), axis=1)
df_data_2.loc[df_data_2['套内面积']=='暂无数据', '套内面积'] = df_data_2.loc[df_data_2['套内面积']=='暂无数据', ['小区名称', '房屋户型', '套内面积']].apply(lambda x: get_nan_info("小区名称", "房屋户型", x[0], x[1], df_data_2, target_col="套内面积", target_value=x[2]), axis=1)
但是套内面积的缺失较多,有 15684 条数据,在进行上一步的准确填充之后,当前仍有 8746 条缺失数据
可以进一步扩大,采用深圳市同户型房屋的平均面积进行填充,更进一步的,可使用处理后的房屋户型的平均面积进行填充
但是由于部分户型只有个位数的数据记录,如下图:
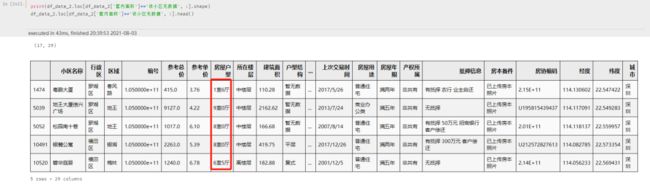
仍旧存在 17 条数据存在缺失,都是属于户型超出正常范围的房屋,例如:1室6厅、9室0厅、8室0厅 这种
为了方便起见,直接用建筑面积填充套内面积即可
df_data_2.loc[df_data_2['套内面积']=='该小区无数据', "套内面积"] = df_data_2.loc[df_data_2['套内面积']=='该小区无数据', "建筑面积"]
# 手动更改数据类型
df_data_2['建筑面积'] = df_data_2['建筑面积'].astype(dtype='float')
df_data_2['套内面积'] = df_data_2['套内面积'].astype(dtype='float')
房屋其他属性处理
同样采用汇总的方式查看分布:
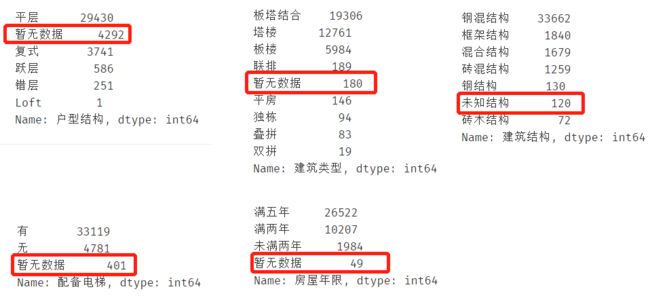
其中:
建筑类型、房屋年限字段存在标记为“暂无数据”的缺失值,
建筑结构存在标记为“未知结构”的缺失值
梯户比例存在NAN缺失(需要NAN检测)
户型结构、配备电梯字段存在以上两种类型的缺失值,需要进行处理
处理方式参考上面房屋面积的处理,只需要改动部分代码即可
房屋抵押信息处理
同样采用汇总的方式查看分布:
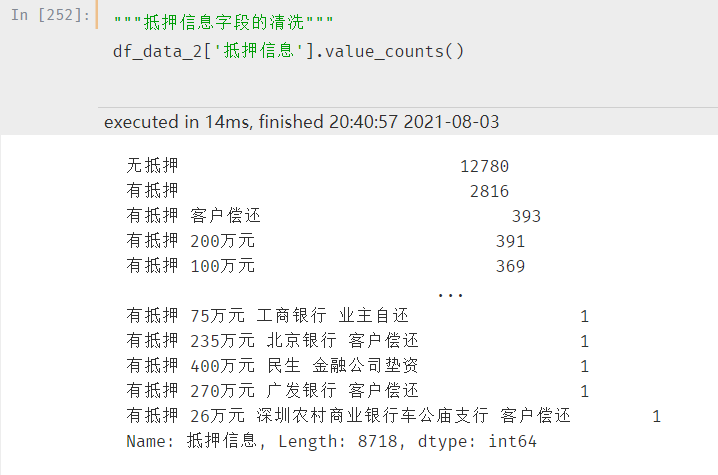
抵押信息看似很多,但是其实说白了就两种,有抵押和无抵押,直接进行处理即可
具体代码如下:
df_data_2.loc[df_data_2['抵押信息']=='暂无数据', '抵押信息'] = "未知"
df_data_2['抵押信息'] = df_data_2['抵押信息'].apply(lambda x: x[0:3])
可视化分析与探索
可视化部分属于非必要内容,它的作用主要是通过绘图的方式发现数据中存在的隐形问题。
比如说:通过可视化发现数值中的极大极小值;通过可视化发现特征和结果之间的规律;通过可视化发现特征之间的相关性等。
但是切记不要为了可视化而可视化,可视化探索的目的是为了发现问题,进而方便在特征工程中进行深层的特征挖掘,而不是为了绘图的美观!
如果你数据量不大,能用 Excel 绘图就没必要用 matplotlib,代码绘图推荐用 seaborn 包,方便高效
可视化探索部分因为篇幅原因,具体的绘图代码就不贴出来了,感兴趣的可以加小一好友获取
区域存量分布
绘图如下:

其中,龙岗区以 11274套 二手房的存量遥遥领先,接下来是福田区、罗湖区、南山区等关内区域
从二手房的存量来看,龙岗区是目前最为火热的区域,虽然地处深圳市的关外区域,但是由于区域面积大,且4号线延长线、10号线等地铁线路的开通,交通便利的同时带动了整个区域的发展
如此看来,宝安、龙华、坪山、光明等关外区域的发展似乎也会慢慢加速
片区存量分布
绘图如下:
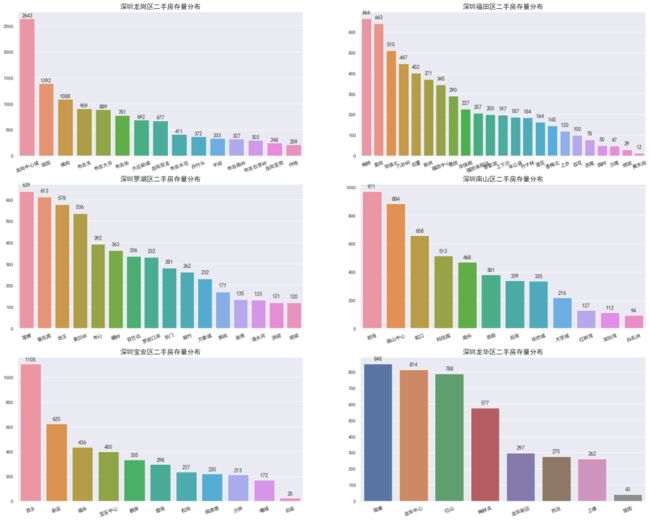
其中,龙岗区以龙岗中心城为主要二手房存量区域,达到2643套,较第二名坂田区域的存量多了近一倍
福田区域二手房存量排行前三则分别是:梅林(666)皇岗(643)和华强北(510)
罗湖区域二手房存量排行前三分别是:莲塘(639)春风路(613)和地王(578),和福田区域的数量比较相近,毕竟是两个不相上下的中心区域
南山区二手房存量排行前三分别是:前海(971)南山中心(884)和蛇口(658),前三的存量差异较大
宝安区和龙华区做为出龙岗以外的两个关外区域,整体存量分布相近的情况下,区域差异较明显
其中,宝安区二手房存量排名前三分别是:西乡(1105)新安(625)福永(436);龙华区二手房存量排名前三分别是:观澜(848)龙华中心(814)红山(788)
小总结 :龙岗区和宝安区的整体分布差异比较相似,而关内三大区域(福田、南山、罗湖)的整体分布差异比较相似
户型分布
绘图如下:
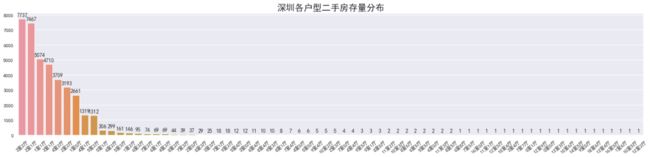
从户型来看,3室2厅(7737)、2室1厅(7467)、1室1厅(5074)分别位居户型存量榜的前三
再往后看7、8、9室的户型也有,但房屋存量只有个位数,如果你需要这份数据去建模预测房价,那么后面的这部分数据可以做一个分箱。举个最简单的例子:7室及7室以上可以统一归为:多室户型
户型结构分布
绘图如下:
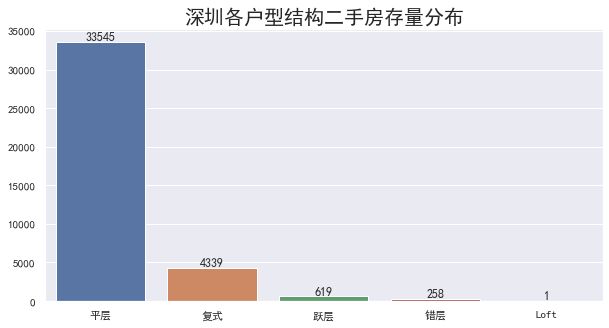
平层结构的存量居多,和第二名复式结构的比例大概是8:1,而Loft户型结构的房屋只有一个
这个数据也和现有普通开发商楼盘对应的户型结构比例相近
楼层结构分布
绘图如下:
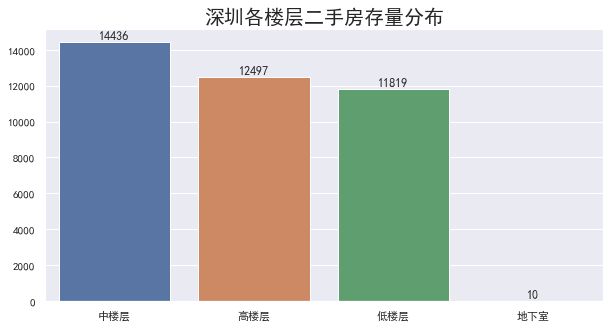
虽然房屋的高中低楼层和整栋楼的楼层高度有关,但是由于深圳的高楼比较多,对应的中、高的比例会略高于低楼层
举个最简单的例子:一栋30层高的小区,按照数据源头的标准,低于10层的会被定义为低层,但是如果你在不知道这栋楼高度的情况下,5层及以上极有可能会被认为是中层
另外,还有10套地下室出售的,如果你的数据只是针对非地下室的正常住宅进行分析建模,那这部分数据建议你直接剔除掉。
价格与面积分布
绘图如下:
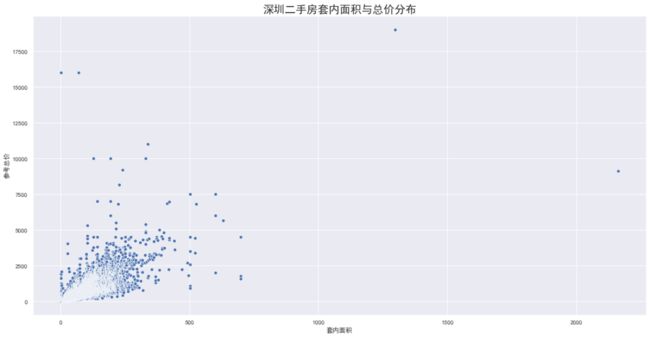
上面这个图是建筑面积和参考总价的分布图,其中,横轴是建筑面积,纵轴是参考总价(单位是:w)
可以看到,有部分二手房的总价是大大超过整体平均值,也有部分二手房的套内面积高于整体平均值
严格来说,当你已经核查过这部分数据的具体信息,这部分数据是可以作为正常数据的。但是考虑到这种离群点会对回归模型的预测精度造成极大的影响,这部分数据也可以作为异常点处理
最简单的处理方式如下:
# 剔除异常数据
df_temp = df_data_3.loc[(df_data_3['参考总价']<=7500) & (df_data_3['套内面积']<=500), :]
用处理后的数据再次绘图

这样一处理,虽然数据的真实性有所下降,但是模型对于正常数据的预测能力会有所提升。
而且,对于超过普通标准(价格/面积)的房屋,可以制定相应的规则去预测,规则的准确率有时候会比模型更高一些。
另外,对于房屋建筑类型、结构、装修情况、梯户比例、配备电梯等等字段的可视化可以参考上面的形式展开
装修情况分布
绘图如下:
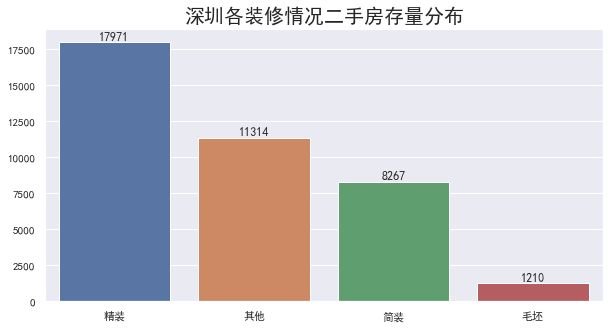
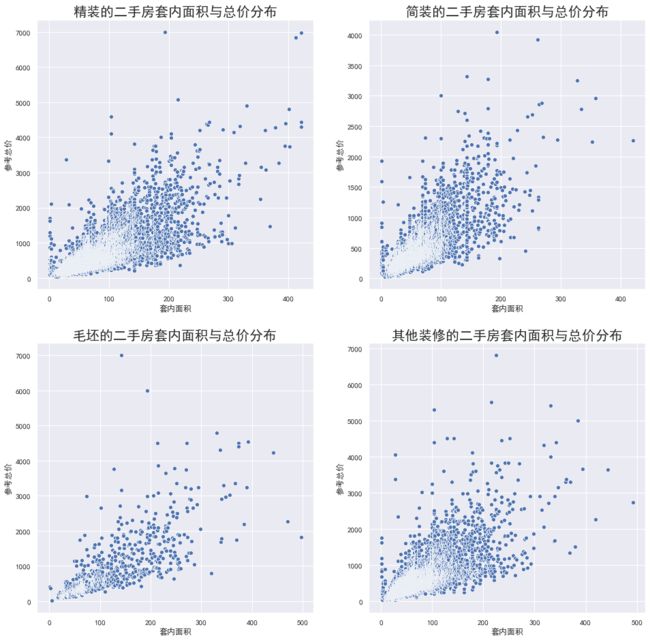
一个是不同装修情况对应的二手房存量不同,一个是对应的回归曲线的权重大小不同(图1和图2的斜率)
映射到整个模型的其他字段(上述提到的字段),可以采用同样的方式去观察模型在不同字段下的分布情况
较为理想的结果是在某个特征的不同取值下,模型结果的分布存在较大差异,这个时候就可以将这个特征作为一个有效特征留下,在后续的分析中可以用于特征衍生、特征交叉等方式进一步提分。
不理想的结果是某个特征的不同取值下,模型结果的分布没有差异或者差异不大,那么通过上述可视化的方式就可以直接把这个特征过滤掉。当然了,针对特征过滤有另外的方法,相比更高效、更准确,但是可视化探索的形式会让你对数据特征更加了解,在后面的特征组合、建模调参中也会比别人更胜一筹。
房屋用途分布
绘图如下:


可以看到,不同用途的二手房套内面积和总价略有差异,具体可以从图中的回归曲线就能看出。对于这类特征后续处理的时候,需要差异化对待
其实这部分有一个小技巧,因为我们最终的模型是对总价进行预测,而当前特征(房屋用途)下商务公寓和公寓对应的总价与面积的分布差异不大。在后续处理的时候,虽然这部分特征在定义上存在较大区别、不能合并,但是由于其对于模型的结果影响一致,所以从结果出发,是可以直接合并的。
同样的道理也适用于其他特征,但是具体内容还需要根据可视化的结果去确定。
另外,有部分特征在定义上可以合并,但是从模型结果角度却存在差异,这部分特征在实际操作中就不建议合并
抵押情况分布
绘图如下:
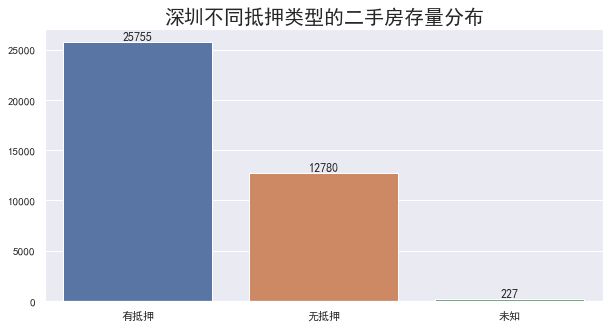

从图中可以看到,在套内面积相近的情况下,有抵押和无抵押的二手房总价差异并不明显,对应上面提到的无差异的情况
这个时候应该考虑两点:
该特征在上一步数据清洗的时候是否忽略了重要信息?
该特征是否可以剔除?
在数据清洗的时候是直接将有抵押信息的全部更新为有抵押,但是具体是抵押给了谁,是银行还是个人?抵押的部分是由客户偿还还是业务偿还?这些信息其实可以进一步的细分,观察它们对于房屋总价的影响
如果在细分之后仍旧没有明显的区别,在后续处理的时候可以考虑直接剔除该字段
地图可视化
通过 pyecharts 的地图包绘制出二手房存量的分布情况,并以房屋总价作为数值标准绘制出二手房的分布图

可以很清楚的看到,二手房存量区域的主要集中区域
其中,800w+的存量二手房则多是集中在福田、南山、等关内区域
总结
目前深圳市各区域二手房存量分布差异较大,主要分为关内和关外的差异。关内各区域的TOP3片区二手房存量差异较小,呈现多点发散,而关外各区域则呈现单点聚集效应,头部区域明显。
在二手房属性上,装修方式、结构、房屋用途等均会对总价产生影响,其中装修方式为简装和毛胚的二手房占整体存量的 30% 左右。
在二手房价格方面,需要注意个别极大值对整体数据的影响,避免数据被平均化。而对价格影响最明显的则是区域,从数据来看,关内关外的两极化分布较明显,平均差异在35%左右,在后续处理(建模)的时候可以考虑进行区域的特征衍生等。
市场相关
需要注意的是,本文的数据集是 2021年6月 采集的,而深圳在 2021年2月 的时候出台了二手房指导价政策,对于市场而言,新政策之后的二手房明显没有新房更香
在新政策出台之后,深圳二手房成交量接连下滑,2月成交量直接接近腰斩,5月跌破了4000套,6月跌破了3000套,在2月的基础上再次接近腰斩。
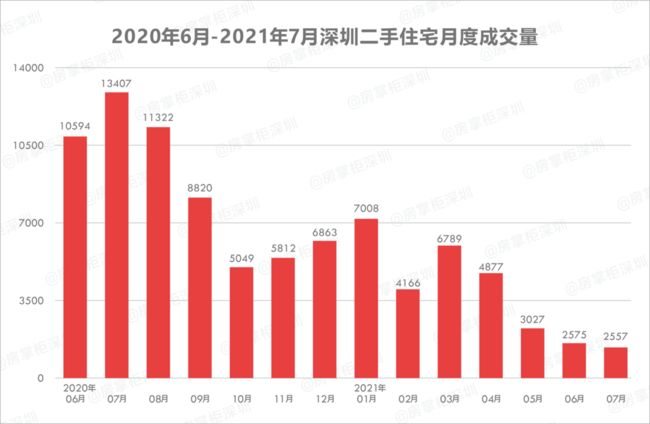
图片源于网络,侵删
从数据角度来看,成交量的下降必然会引起房屋价格的调整,虽然我这里没有在2月份以前的二手房价格,但是这个结论应该不会有错
至于政策的影响、市场的波动我们不必多说,但单纯从数据侧出发,当我们以模型为目标去看待数据的时候,不但需要从数据内部去探索不同特征对模型的影响,还需要从时间维度去总结变化规律,毕竟在数据分析的时候我们不光要看环比,还需要重视同比。
尽可能多的考虑数据内外在的变化,分析不同因素造成的影响大小,这样的数据结论才会更全面、更精确。
以上就是本次实战数据分析部分的内容,希望能够对大家的数据分析所有帮助!
我是小一,下节见!


扫码加好友,加入海归Python编程和人工智能群
往期文章:
爬虫—最详细的城市二手房数据爬取
办公—Python实现PDF的操作(全)
理财—1季度15646只基金数据分析
实战—真实运营商5G套餐用户分析