NIPS 2019 | CC-FPSE 阅读笔记(翻译)
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
作者:Xihui Liu, Xiaogang Wang, Hongsheng Li{The Chinese University of Hong Kong}, Guojun Yin{University of Science and Technology of China}, Jing Shao{SenseTime Research}
会议:NIPS 2019
论文地址:https://arxiv.org/abs/1910.06809
代码地址:https://github.com/xh-liu/CC-FPSE
Abstract
语义图像合成旨在从语义布局中生成真实感图像。以前的条件生成对抗网络方法在这一任务上表现出了最先进的性能,它要么将语义标签映射作为输入提供给生成器,要么使用它们通过仿射变换来调制标准化层中的激活值。我们认为生成器中的卷积核在生成图像时应该知道不同位置的不同语义标签。为了更好地利用图像生成器的语义布局,我们提出以语义标签图为条件来预测卷积核,以从噪声图中生成中间特征图,并最终生成图像。此外,我们还提出了一种特征金字塔语义嵌入鉴别器(feature pyramid semantics-embedding discriminator),它比以前的多尺度鉴别器更能有效地增强生成的图像和输入语义布局之间的细节和语义对齐。在各种语义分割数据集上,我们在量化指标和主观评价上都取得了最先进的结果,证明了我们方法的有效性。
1 Introduction
语义图像合成的一个基本问题是如何利用生成器中的语义布局信息。大多数以前基于遗传神经网络的方法将标签图作为输入,并通过编码器-解码器网络生成图像[13,29,25]。尽管如此,由于语义标签图在输入层仅被馈入网络一次,因此布局信息不能很好地保存在生成器中。为了缓解这个问题,SPADE [25]使用标签映射来预测空间自适应仿射变换,以调制标准化层中的激活值。然而,通过简单仿射变换的这种特征调制在表征能力和灵活性方面受到限制。
另一方面,我们重新思考图像合成中卷积层的功能。在生成网络中,每个卷积层通过输入特征的局部邻域在每个位置生成精细特征来学习“如何绘制”。相同的平移不变卷积核被应用于所有样本和所有空间位置,而不管不同位置的不同语义标签,以及每个样本的唯一语义布局。我们的论点是,不同的卷积核应该用于生成不同的对象或东西(objects or stuff)。
受上述两个方面的启发,我们提出了基于输入语义布局来预测空间变化的条件卷积核,使得布局信息可以更明确和有效地控制图像生成过程。然而,天真地预测所有卷积核是不可行的,因为它需要大量可学习的参数,这导致过度拟合并需要太多的GPU内存。受轻量级卷积神经网络[4,11,23]最近工作的启发,我们提出预测深度方向可分离卷积,它将卷积运算分解为条件深度方向卷积(conditional depthwise convolution)和常规点方向卷积(conventional pointwise convolution)(即1×1卷积)。每个空间位置的条件核权重由全局上下文感知权重预测网络根据语义布局来预测。我们提出的条件卷积使语义布局能够更好地控制生成过程,而不会大幅增加网络参数和计算成本。
深度可分离卷积:
https://zhuanlan.zhihu.com/p/65377955
大多数现有的语义图像合成方法采用多尺度PatchGAN鉴别器[29,25],但是其有限的表示能力不能匹配生成器增加的容量。我们认为,一个健壮的鉴别器应该关注图像的两个不可或缺且互补的方面:高保真细节和与输入布局图的语义对齐。受这两个原则的启发,我们提出利用多尺度特征金字塔来提升纹理和边缘等高保真细节,并利用patch-based的semantic-embedding来增强生成的图像和输入语义布局之间的空间语义对齐。
本文的贡献总结如下。(1)提出了一种新的语义图像合成方法,即基于语义布局学习预测布局到图像的条件卷积核。这种条件卷积操作使得语义布局能够基于不同位置的不同语义标签自适应地控制生成过程。(2)我们提出了一种特征金字塔语义嵌入鉴别器,该鉴别器在鼓励高保真细节和与输入布局图的语义对齐方面更有效。(3)利用所提出的CC-FPSE方法,我们在CityScapes、COCO-Stuff和ADE20K数据集上获得了最先进的结果,证明了我们的方法在生成具有复杂场景的图像方面的有效性。
2 Related Work
GAN
Semantic image synthesis
Dynamic filter networks 动态滤波器网络[14]是基于输入生成动态滤波器的首次尝试。Ha等人[7]提出了HyperNetworks,其中一个hyper-network用于为另一个网络生成权重。这一思想已被应用于不同的应用,如神经风格转移[27],超分辨率[15,12],图像分割[8,30],运动预测[32]和跟踪[19]。然而,他们中的大多数只预测了有限数量的过滤器,如果我们在每一层使用动态预测的过滤器,将会消耗大量的计算和内存。苏等人[28]提出了像素自适应CNN,它将传统的卷积滤波器与空间变化的核相乘,以获得卷积核。赵等[35]采用共享滤波器组和预测自适应权值来线性组合基滤波器。这种操作仍然基于传统的卷积。因此,输入信息在控制或影响自适应卷积核方面的能力有限,生成网络的行为仍然由传统的卷积核控制。我们的方法在几个方面不同于以前的工作。首先,我们预测以布局信息为条件的卷积核,使得条件信息可以明确地控制生成过程。其次,我们通过引入深度可分离卷积来降低计算和存储成本,同时通过直接预测卷积核权重来使条件信息能够控制生成过程。
3 Method
我们提出了一种新的基于条件生成对抗网络的语义图像合成方法。提出的框架CC-FPSE由一个新的生成器G和一个特征金字塔语义嵌入鉴别器D组成,生成器G具有由权重预测网络预测的条件卷积,如图2(右)所示。**所提出的生成器G能够在有限的计算资源下,通过预测生成网络的多个层中的卷积核,充分利用语义布局信息来控制图像生成过程。**所提出的鉴别器D能够监督精细细节的生成,并通过将图像和标签映射都嵌入到联合特征空间来强制生成的图像和输入语义布局之间的空间对齐。

3.1 Learning to Predict Conditional Convolutions for Image Generator
我们提出的生成器G采用低分辨率噪声图作为输入。或者,它使用所提出的条件卷积块[9]和上采样层来逐渐细化中间特征图,并最终生成输出图像。在传统的卷积层中,相同的卷积核被应用于所有样本和所有空间位置,而不管它们不同的语义布局。我们认为这种卷积运算对于语义图像合成不够灵活和有效。在语义图像合成中,给定局部邻域中的粗糙特征,卷积层在每个位置逐渐生成精细特征。由于不同的对象或stuff应该以不同的方式生成,我们希望卷积层知道目标位置的唯一语义标签。
为了更好地将布局信息融入图像生成过程,我们提出基于语义布局预测卷积核权重。给定输入特征图 X ∈ R C × H × W X ∈ \R^{C×H×W} X∈RC×H×W,我们的目标是通过一个核大小为k × k的卷积层产生输出特征图 Y ∈ R D × H × W Y ∈ \R^{D×H×W} Y∈RD×H×W。我们采用一个权重预测网络,该网络以语义标签图为输入,输出每个条件卷积层的预测卷积核权重。然而,天真地预测所有内核权重会导致过度的计算成本和GPU内存使用。为了解决这个问题,我们将卷积层分解为深度方向卷积和点方向卷积,并且只预测轻量级深度方向卷积的权重。
个人理解:为每个语义图,动态生成卷积核的参数,并用深度可分离卷积来降低计算成本
3.1.1 Efficient Conditional Convolution Blocks for Image Generation
传统的卷积核具有 D × C × k × k D × C × k × k D×C×k×k的权重参数。生成空间变化卷积核的简单方法需要预测 D × C × k × k × H × W D×C ×k×k×H ×W D×C×k×k×H×W权重参数。这是不切实际的,因为卷积运算是生成器G的基本构造块,并且会在生成器中堆叠多次。这样的网络不仅计算量大、内存大,而且容易使训练数据过度。
为了解决这个问题,我们引入了深度可分卷积[4],并且只预测深度卷积核权重,这大大减少了要预测的参数数量。特别地,我们将卷积核分解为条件深度卷积和传统的点卷积(即1 × 1卷积)。条件深度卷积独立地对每个输入通道执行空间滤波,并且基于语义布局动态地预测其空间变化的核权重。条件卷积层的预测权重表示为 V ∈ R C × k × k × H × W V ∈ \R^{C×k×k×H×W} V∈RC×k×k×H×W,输出特征映射表示为 Y ∈ R C × H × W Y ∈ \R^{C×H×W} Y∈RC×H×W。

其中 i , j i,j i,j表示特征映射的空间坐标,k表示卷积核大小,c表示通道索引。核大小为k × k的V中的C × H × W卷积核独立地在X的每个通道和每个空间位置操作,以生成输出特征映射。然后,我们利用传统的逐点卷积(1 × 1卷积)将C输入通道映射到D输出通道,输出表示为 Y ′ ∈ R D × H × W Y'∈ \R^{D×H×W} Y′∈RD×H×W。
此外,我们还提出了一个条件注意操作来门控传递到下一层的信息流。条件注意权重以与条件卷积核相同的方式预测,这将在后面详细描述。预测的注意力权重 A ∈ R C × H × W A∈\R^{C×H×W} A∈RC×H×W和卷积输出 Y ′ Y' Y′之间元素等级的乘积产生门控特征图,
![]()
其中c是通道索引, i , j i,j i,j表示特征图中的空间位置。
条件卷积和条件注意中预测参数的大小分别为 C × k × k × H × W C × k × k × H × W C×k×k×H×W(在我们的实现中k = 3)和 C × H × W C × H × W C×H×W。与直接预测整个卷积核权重相比,参数大小减少了D倍。
通过预测每个空间位置的唯一卷积核权重,图像生成过程变得更加灵活,并且适应语义布局条件。同时,通过引入深度可分卷积,我们保持了可承受的参数大小和计算成本。我们用上面介绍的操作定义了一个类似于结果块的结构,叫做条件卷积块。如图2(左)所示,它包括一个常规的批量标准化层、一个k = 3的条件深度卷积、一个常规的逐点卷积,然后是一个条件注意层,最后是非线性激活层。对于每两个这样的块,也有相同的中间连接。
3.1.2 Conditional Weight Prediction and Overall Generator Structure
给定输入语义布局,条件权重预测网络预测条件权重。权重预测网络的简单设计是简单地堆叠多个卷积层。在SPADE [25]中,内核大小为3 × 3的两个卷积层被应用于下采样语义标签映射,以生成它们所提出的自适应标准化层的自适应比例和偏差。但是通过最近邻插值将语义标签映射下采样到非常小的尺寸,例如8×8,将不可避免地丢失许多有用的信息。此外,这样的结构只有5 × 5的感受野,这限制了权重预测结合长期上下文信息。如果有一个大面积的相同语义标签,这个区域内的像素只能访问一个5 × 5的具有相同语义标签的局部邻域。因此,它们将由相同的预测权重进行处理,而不管它们在对象或stuff内部的相对位置如何。
因此,我们设计了一个具有特征金字塔结构的全局上下文感知权重预测网络(weight prediction network)[20]。我们的权重预测网络的架构如图2(右)所示。标签图首先通过布局编码器进行下采样,然后由解码器利用来自编码器的横向连接进行上采样。将特征金字塔不同层次的特征与原始语义图连接,得到全局上下文感知的语义特征图,分别用于预测条件卷积权重和条件注意权重。我们使用两个卷积层来预测条件卷积权重。为了预测条件注意权重,我们采用了两个卷积层和一个Sigmoid激活层。
利用权重预测网络的编码器-解码器结构,我们的预测权重不仅知道局部邻域,还知道长期上下文和相对位置。
整个生成器网络由一系列条件卷积块和上采样层组成,条件权重由权重预测网络预测。
3.2 Feature Pyramid Semantics-Embedding Discriminator
我们认为,一个好的鉴别器应该关注两个不可或缺且互补的方面:高保真的细节,如纹理和边缘,以及与输入语义图的语义对齐。现有的语义图像合成方法采用多尺度拼接鉴别器[29,25],其中与语义标签图连接的图像被缩放到多个分辨率,并被馈送到具有相同结构的不同鉴别器中。但是它仍然难以辨别细微的细节,并且不会对生成的图像和输入标签地图之间的空间语义对齐造成强约束。
在上述两个鉴别器设计原则的激励下,我们提出了一种更有效的鉴别器设计。我们创建了多尺度特征金字塔来促进高保真细节,如纹理和边缘,并利用语义嵌入鉴别器来强制生成的图像和输入语义布局之间的空间语义对齐。
3.2.1 Feature Pyramid Discriminator
当前的图像生成方法倾向于生成具有模糊边缘、纹理和明显伪像的图像。这个问题表明,在设计鉴别器架构时,我们应该更多地关注底层细节。另一方面,鉴别器还应该具有高级语义的全局视图。先前引入的多尺度PatchGAN鉴别器[29]试图通过不同尺度的多个鉴别器来平衡大的感受野和精细的细节。不同尺度的相同图像被独立地馈送到不同的鉴别器中,导致网络参数、内存占用和计算成本增加。
受从图像金字塔到特征金字塔的演化的启发[20],我们提出了一种单特征金字塔鉴别器来产生具有全局语义和低级纹理和边缘信息的多尺度特征表示。如图2(右)所示,我们的特征金字塔鉴别器以单一比例获取输入图像。自底向上路径产生由多尺度特征图组成的特征层次,自顶向下路径逐渐向上采样空间粗糙但语义丰富的特征图。在横向上结合了来自自顶向下途径的高级语义特征图和来自自底向上途径的低级特征图。结果,组合的多尺度特征在语义上很强,并且包含更精细的低级细节,例如边缘和纹理。因此,鉴别器将对语义信息和细节提出更强的约束。
3.2.2 Semantic Embeddings for Discriminator
在用于语义图像合成的传统鉴别器中,图像及其对应的语义图被连接并作为其输入被馈送到鉴别器。然而,不能保证鉴别器利用语义图来区分真实/虚假图像。换句话说,鉴别器可以通过仅鉴别图像是否真实来满足训练约束,而不考虑它是否与标签图匹配良好。受投影鉴别器(projection discriminator)[24]的启发,它计算类标签和图像特征向量之间的点积,作为输出鉴别器分数的一部分,我们将这一思想应用于我们的场景,其中条件是空间标签映射。为了鼓励生成的图像和条件语义布局之间的语义对齐,我们提出了一种patch-based的语义嵌入鉴别器。
我们的鉴别器仅将真实或生成的图像作为输入,并以不同的比例产生一组特征金字塔 { F 1 , F 2 , F 3 } \{F_1,F_2,F_3\} {F1,F2,F3}。 F i ∈ R C × N i × N i ( i ∈ { 1 , 2 , 3 } ) F_i∈ \R^{C×N_i×N_i}(i ∈ \{1,2,3\}) Fi∈RC×Ni×Ni(i∈{1,2,3})表示空间分辨率为C通道的 N i × N i N_i× N_i Ni×Ni特征图。 F i F_i Fi中每个空间位置的特征向量代表原始图像中的一个patch。传统的PatchGAN鉴别器试图通过预测特征图 F i F_i Fi中每个空间位置的分数来分类每个patch是否真实。我们不仅强制鉴别器不仅要对真实或虚假的图像进行分类,还要对在一个联合embedding空间内的patch特征是否与该patch中的语义标签相匹配进行分类。
我们将语义图下采样到与 F i F_i Fi相同的空间分辨率,并将每个空间位置的one-hot标签嵌入到一个C维向量中。嵌入语义布局表示为 S i ∈ R C × N i × N i S_i∈ \R^{C×N_i×N_i} Si∈RC×Ni×Ni。我们计算每个空间位置之间的内积,以获得语义匹配分数图,其中每个值表示原始图像中相应patch的语义对齐分数。语义匹配分数与传统的真/假分数相加作为最终的鉴别分数。这样,鉴别器不仅引导生成器生成高保真图像,还驱动生成的图像更好地与条件语义布局进行语义对齐。
3.3 Loss Functions and Training Scheme
我们的网络的生成器和鉴别器是交替训练的,其中鉴别器采用hinge损失来区分真/假图像,而生成器是用多重损失优化的,包括基于hinge的对抗损失、鉴别器特征匹配损失和感知损失,遵循以前的工作[29,25],

其中x是真实图像,y是语义标签图,z是输入噪声图。 L P ( G ( z , y ) , x ) L_P(G(z,y),x) LP(G(z,y),x)表示感知损失,它匹配生成的图像和原始图像之间的VGG提取的特征。 L F M ( G ( z , y ) , x ) L_{FM}(G(z,y),x) LFM(G(z,y),x)表示鉴别器特征匹配损失,它匹配生成图像和原始图像之间的鉴别器中间特征。 λ P λ_P λP和 λ F M λ_{FM} λFM分别表示感知损失和特征匹配损失的权重。
4 Experiments
4.1 Datasets and Evaluation Metrics
我们在Cityscapes[5],COCO-Stuff[2]和ADE20K [36]数据集上进行了实验。城市景观数据集有3000个训练图像和500个城市街道场景的验证图像。COCO-Stuff是最具挑战性的数据集,包含来自复杂场景的118,000个训练图像和5,000个验证图像。ADE20K数据集提供了20,000幅训练图像和2,000幅来自室外和室内场景的验证图像。所有图像都用语义分割掩码标注。
我们从三个方面评估我们的方法。我们首先通过我们的方法和以前的方法比较合成图像,并进行人类感知评估以比较生成图像的视觉质量。然后,我们使用在原始数据集上预处理的分割模型来评估生成的图像的分割性能。我们使用与[25]中相同的分割模型进行测试。分割性能通过平均交-并和像素精度来衡量。最后,我们通过FID计算生成的图像和真实图像之间的分布距离[10]。
4.2 Implementation Details
对于COCO-Stuff和ADE20K数据集,训练和生成的图像分辨率为256 × 256,对于Cityscapes数据集,为256 × 512。对于生成器,采用不同GPUs之间的同步批处理规范化,以更好地估计批处理统计。对于鉴别器,我们使用instance normalization。我们使用Leaky ReLU激活,以避免ReLU激活引起的稀疏梯度。我们采用ADAM[18]优化器,生成器的学习率为0.0001,鉴别器的学习率为0.0004。感知损失 λ P λ_P λP 为10,权重鉴别器特征匹配损失 λ F M = 20 λ_{FM}=20 λFM=20。根据[25],为了实现多模态合成和风格导向合成,我们应用了风格编码器和损失权重为0.05的KL-散度损失。我们的模型在16个TITANX GPUs上训练,batch size为32。我们为Cityscapes和ADE20K数据集训练了200个epoch,为COCO-Stuff数据集训练了100个epoch。代码在https://github.com/xh-liu/CC-FPSE。
4.3 Qualitative Results and Human Perceptual Evaluation
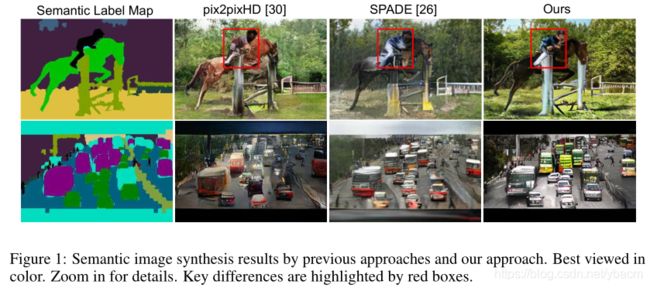
我们将我们的结果与之前的方法pix2pixHD [29]和SPADE [25]进行了比较,如图3所示。由我们的方法生成的图像显示出对以前的具有挑战性的场景的方法的显著改进(我真看不出来有多明显的改进。。)。它们有更精细的细节,如边缘和纹理,更少的人工制品,并且与输入语义布局更好地匹配。图4显示了由我们提出的方法生成的更多图像。补充材料中提供了更多的结果和比较。

我们还进行了一项人类感知评估,以比较我们的方法和以前的先进方法SPADE [25]生成的图像质量。特别是,我们从每个数据集的验证集中随机抽取500个语义标签图。在每个实验中,工作人员会看到一个语义标签图,其中有两个分别由我们的方法和SPADE生成的图像。要求工作人员选择与语义布局更好匹配的更高质量的图像。我们发现,在Cityscapes、COCO-Stuff和ADE20K数据集上,分别有55%、76%和61%的图像是首选的。人类感知评估验证了我们的方法能够生成更高保真的图像,这些图像在空间上更好地与语义布局对齐。
4.4 Quantitative Results

4.5 Ablation Studies
我们进行控制实验,以验证我们方法中每个组件的有效性。我们使用SPADE [25]模型作为我们的基线,并逐渐在框架中添加或删除每个组件。我们的模型在最后一栏中表示为CC-FPSE。由每个实验生成的图像的分割分数如表2所示。

Conditional convolutions for generator . 我们首先用我们的条件卷积层替换SPADE层,以将语义布局信息包含在被称为“CC”的实验中。通过将基线与(1) (CC发生器与SPADE发生器,均带有MsPatch鉴别器)、(5)与CC-FPSE(我们的)(CC发生器与SPADE发生器,均带有FPSE鉴别器)和(4)与(6) (CC发生器与SPADE发生器,均带有MsPatch+SE鉴别器)进行比较,结果表明我们的条件卷积能够更好地利用语义布局信息自适应地生成高质量图像。
Feature pyramid weight prediction network. 接下来,我们用权重预测网络中的两个卷积层的堆叠来替换特征金字塔结构,并且这个实验被表示为“w/ FP”和“w/o FP”。将(1)与(2)进行比较,将(3)与CC-FPSE(我们的)进行比较,我们发现去除权重预测网络的特征金字塔结构会导致较差的性能,这表明全局和远程(long-range)信息对于预测卷积权重是必要的。
FPSE Discriminator . 我们修复了我们提出的生成器(“CC w/ FP”或“SPADE w/ FP”),并测试了鉴别器的不同设计,以证明我们的FPSE鉴别器的有效性。通过为鉴别器引入语义嵌入约束,我们强制空间语义与语义布局对齐。将(2)与(6)进行比较表明了语义嵌入鉴别器的有效性。在语义嵌入约束下,驱动鉴别器对图像块和语义布局之间的对应关系进行分类。因此,鼓励生成器生成更符合语义布局的图像。此外,我们将多尺度鉴别器替换为特征金字塔结构,表示为“FP+SE”,这是我们提出的鉴别器设计。(6)与最后一列CC-FPSE (Ours)的比较表明,特征金字塔鉴别器结构结合了不同尺度的低层特征和语义特征,进一步提高了性能。
5 Conclusion
我们提出了一种新的方法(CC-FPSE),通过更好地利用语义布局信息,从给定的语义布局中生成具有高质量细节和良好对齐的语义的图像。通过预测条件卷积层的空间变化权重,我们的生成器能够更好地利用语义布局来控制生成过程。我们的特征金字塔语义嵌入鉴别器引导生成器生成包含高保真细节并与条件语义布局良好对齐的图像。我们的方法实现了最先进的性能,并能够在Cityscapes,、COCO-Stuff和ADE20K数据集上生成逼真的图像。
个人总结:1.输入不是直接的语义图,而是噪声map;2.针对每个语义图生成动态的卷积滤波器,用特征金字塔来做的;3.生成器中使用深度可分离卷积,降低计算成本,并使用条件卷积;4.不使用多个尺度的鉴别器,而是使用单个特征金字塔判别器;5.判别器中不仅判断生成的整张图片是否真实,还要判断其中的每个语义标签是否真实。