YOLOv5实现目标识别全流程【超级详细!】
1. 问题背景
在深度学习中,目标识别问题是我们所熟知的最经典最重要的问题之一。目标识别需要在一幅大图片中定位到多个目标的位置和类别。目标检测的应用范围很广,比如在超市通过视频检测消费者的进出、工业制造业领域中的异常行为检测等。另一个典型的场景是,在自动驾驶时车辆需要定位视线范围内的所有物体,并识别其类别以判断危险程度。这都给目标检测这一领域提供了丰富的应用空间。
2. 模型介绍
2.1 YOLO简介
YOLO的名字来历颇有意思,他的本意是流行语You Only Live Once的缩写,而模型的作者Joseph Redmon改了一个词将You Only Look One作为模型的名字。这是由于,相对于R-CNN系列算法将检测问题分解为划定位置和判定类别分两步做,YOLO系列算法没有显式寻找区域的过程,可以实现端到端的快速预测,即输入一幅图片,在输出中给出若干目标的位置、类别和置信度。
而相对于同样是一步到位的SSD算法,YOLO系列的特点在于算法一经发出,便有各种各样的人和团队对他进行更新迭代。通过不断地更新迭代模型版本,YOLO也得到了效果上持续的提升和更广泛的关注。但值得注意的是,YOLO模型的原作者Joseph Redmon更新到v3版本后就退出了相关的研究,而后续的版本都是其他研究人员的工作。今天介绍的YOLOv5就是由ultralytics团队进行研发和维护。(相关资料可以登录其官方网站https://ultralytics.com/进行了解,也可以下载ultralytics APP体验目标识别效果)

2.2 YOLO模型介绍
我们首先介绍一下最原始的YOLO模型,然后简要介绍一下YOLOv5版本的改进,主要通过具体的例子一起看看怎么把YOLOv5模型用好。
YOLOv1的网络结构并没有什么特别,和我们熟悉的图像分类一样都是卷积神经网络,但它的输出向量却不太一样。如果把神经网络看作我们熟悉的回归分析问题,那YOLO做的事情就是改变了模型响应Y的结构,而这也奠定了YOLO目标检测的基础。YOLO的输出向量不仅包括目标的类别,还有边界框的坐标和预测的置信度。它的核心思想在于把图像分割成S*S的若干个小块,在每个格子中预先放置两个边界框,通过卷积神经网络预测得到每个边界框的坐标、类别和置信度,然后通过非极大值抑制获得局部唯一的预测框。
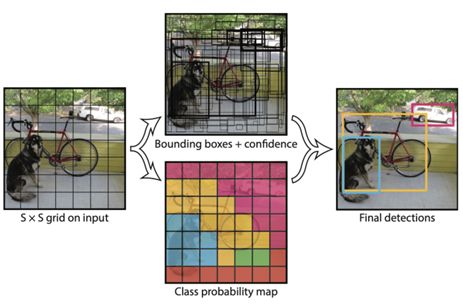
经过若干年的版本迭代,YOLOv5的网络结构博采众长,已经变得格外复杂,主要包括在Backbone中通过卷积和池化网络结构提取特征,在Neck部分不断地和之前提取的特征进行融合,Head部分则是用来进行最终的检测和输出,如下图所示。

我们今天选取YOLOv5作为介绍,一方面是因为从最终效果来看YOLOv5已经相当优秀,是发展的比较完备、使用比较广泛的一个版本;而更重要的是YOLOv5的调用、训练和预测都十分方便,为初学者提供了良好的练手工具。YOLOv5的另一个特点就是它为不同的设备需求和不同的应用场景提供了大小和参数数量不同的网络。

如图所示,大一点的模型比如YOLOv5l和YOLOv5x参数更多,在大规模的COCO数据集上有更高的预测准确率;而小模型比如YOLOv5n或YOLOv5s占空间更小,适合部署在移动设备上,且推理速度更快,适合于高帧率视频的实时检测。
3. 数据介绍
3.1 数据标注格式转换
我们采用真实公开的人脸识别数据集WIDER FACE进行YOLOv5模型的训练和测试,数据开源于http://shuoyang1213.me/WIDERFACE/ 。数据集相关信息可以访问网站主页。
为了进行目标检测,一个重要的步骤是进行数据标注。如果数据集已经完成标注的,则可以考虑是否需要格式转换。
下面以WIDER人脸数据集为例
1.下载下面的四个压缩包,并放在同一个文件夹内
WIDER Face Training Images
WIDER Face Validation Images
WIDER Face Testing Images
Face annotations
2. 在同一目录下解压4个压缩包,在当前目录下运行convert.py 转化为VOC格式数据集,完整代码如下:
(转化好的完整的voc格式的人脸数据集,https://pan.baidu.com/s/19w9vLbqovjL6-apH-RmwFQ,提取码:2cv4)
# -*- coding: utf-8 -*-
import shutil
import random
import os
import string
from skimage import io
headstr = """\
VOC2012
%06d.jpg
My Database
PASCAL VOC2012
flickr
NULL
NULL
company
%d
%d
%d
0
"""
objstr = """\
"""
tailstr = '''\
'''
def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % ('face', bbx[0], bbx[1], bbx[0] + bbx[2], bbx[1] + bbx[3]))
f.write(tail)
f.close()
def clear_dir():
if shutil.os.path.exists(('Annotations')):
shutil.rmtree(('Annotations'))
if shutil.os.path.exists(('ImageSets')):
shutil.rmtree(('ImageSets'))
if shutil.os.path.exists(('JPEGImages')):
shutil.rmtree(('JPEGImages'))
shutil.os.mkdir(('Annotations'))
shutil.os.makedirs(('ImageSets/Main'))
shutil.os.mkdir(('JPEGImages'))
def excute_datasets(idx, datatype):
f = open(('ImageSets/Main/' + datatype + '.txt'), 'a')
f_bbx = open(('wider_face_split/wider_face_' + datatype + '_bbx_gt.txt'), 'r')
while True:
filename = f_bbx.readline().strip('\n')
if not filename:
break
im = io.imread(('WIDER_' + datatype + '/images/' + filename))
head = headstr % (idx, im.shape[1], im.shape[0], im.shape[2])
nums = f_bbx.readline().strip('\n')
bbxes = []
if nums=='0':
bbx_info= f_bbx.readline()
continue
for ind in range(int(nums)):
bbx_info = f_bbx.readline().strip(' \n').split(' ')
bbx = [int(bbx_info[i]) for i in range(len(bbx_info))]
# x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
if bbx[7] == 0:
bbxes.append(bbx)
writexml(idx, head, bbxes, tailstr)
shutil.copyfile(('WIDER_' + datatype + '/images/' + filename), ('JPEGImages/%06d.jpg' % (idx)))
f.write('%06d\n' % (idx))
idx += 1
f.close()
f_bbx.close()
return idx
if __name__ == '__main__':
clear_dir()
idx = 1
idx = excute_datasets(idx, 'train')
idx = excute_datasets(idx, 'val')
print('Complete...')
#原文链接:https://blog.csdn.net/sunqiande88/article/details/1024148833. 耐心等待运行完,数据量比较大,运行时间较长。结束后会生成3个文件夹,分别为:
Annotations 【存放xml标签】
ImageSets 【用txt文本存放图片的名称】
JPEGImages 【存放所有JPG原图】
4. 模仿VOC数据集的目录格式,将上面三个文件夹放在如下的层级目录下:
--VOCdevkit
--VOC2012
--Annotations //存放xml标签
--ImageSets
--Main //用txt文本存放图片的名称
--JPEGImages //存放所有JPG原图
--labels //存放yolo用的txt格式的标签
5. 将VOC的xml标签转化为YOLO要用的txt格式的标签,在VOCdevkit同级目录下运行voc_label.py:
"""
@Usage: generate custom voc-format-dataset labels, convert .xml to .txt for each image
@author: sun qian
@date: 2019/9/25
@note: dataset file structure must be modified as:
--VOCdevkit
--VOC2012
--Annotations
--ImageSets
--Main (include train.txt, test.txt, val.txt)
--JPEGImages
--labels
@ merge val and test: Run command: type 2012_test.txt 2012_val.txt > test.txt
"""
import xml.etree.ElementTree as ET
import os
from os import getcwd
# file list - train.txt, test.txt, val.txt
sets = [('2012', 'train'), ('2012', 'val')]
# class name
classes = ["face"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)):
os.makedirs('VOCdevkit/VOC%s/labels/' % (year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
line = '%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id)
list_file.write(line.replace("\\", '/'))
convert_annotation(year, image_id)
list_file.close()
#原文链接:https://blog.csdn.net/sunqiande88/article/details/1024148836. 结束后会在VOCdevkit -> VOC2012下生成labels和下面的2个txt文件(存放训练图片的绝对路径):

3.2 手动数据标注介绍
当然如果数据集是未完成标注的,则需要进行手动标注,即在图像上手动用矩形框来框出目标的位置并说明类别,以下面这张随意从训练集中抽出的图片为例。

支持标记的软件或网站有很多,比较常用的人工标注工具如labelImg软件和roboflow网站等。标注结果一般有VOC格式的xml文件或支持YOLO训练的txt文件,一般可以选择或通过脚本转换为需要的txt文件即可。UA-DETRAC数据集已经做好了xml类型的标注,而YOLOv5的输入格式要求txt文件,因此我们需要做一下格式的转换。
xml格式的标记文件中记录了物体的类别、标记框在像素图片上的左上角坐标 (left,top) 和标记框的像素长度 (width, height),而YOLO txt文件要求记录的是标记框中心相对图片长宽的比例,以及标记框长宽相对图片长宽的比例。由于我们已经知道图片像素大小,因此可以轻易的在实际的像素位置和YOLO txt格式之间进行换算,这里img_w、img_h指的是图片的宽和高,而(x, y)最终指的是标记框中心的相对位置:
x = left + width / 2 # 标记框中心x轴坐标
y = top + height / 2 # 标记框中心y轴
x = x / img_w # 标记框中心x轴坐标归一化
y = y / img_h # 标记框中心y轴坐标归一化
width = width / img_w # 标记框宽度归一化
height = height / img_h # 标记框高度归一化通过上述公式换算过后,我们来看看刚才这张标记好的训练集图片的txt格式标记数据:
1 0.608021 0.277056 0.053854 0.089556
1 0.58651 0.196116 0.038958 0.060509
1 0.543646 0.15381 0.030104 0.052806
1 0.593672 0.150444 0.031719 0.039667
1 0.78026 0.2345 0.050104 0.069963
1 0.951562 0.481509 0.098958 0.170537以这个标记文件的第一行为例,1表示类别car,0.608021是标记框中心横坐标与图像宽度比值,0.277056表示标记框中心纵坐标与图像高度比值,0.053854是标记框宽度与图像宽度比值,0.089556表示标记框高度与图像高度比值。
3.3 安装labelimg
pip install labelimg
3.4 打开labelimg
# 在命令行中输入labelimg即可打开
labelimg
3.5 打开你所需要进行标注的文件夹
点击Open Dir -> 选择需要标注的文件夹 -> ok

3.6 选择yolo标注格式
点击红色框区域进行标注格式切换,我们需要yolo格式,因此切换到yolo。

3.7 打标签
点击Create RectBo -> 拖拽鼠标框选目标 -> 给上标签 -> 点击ok。
注:若要删除目标,右键目标区域,delete即可

3.8 保存
点击save,保存txt。
4. 环境搭建
4.1确认硬软件配置
硬件:
显卡(GPU),显存4G以上。(无GPU训练慢)
内存(4G以上)
软件:
windows / linux
cuda / cudnn:(模型训练加速工具)
pycharm(python IDE): https://www.jetbrains.com/pycharm/
4.2 新建虚拟环境:
检查是否正确安装好anaconda。
anaconda (python package管理工具):https://www.anaconda.com/
windows+r打开cmd,输入 conda -V。若出现版本号,则安装成功。
接下来新建虚拟环境
conda create -n your_env_name python=x.x
# 例如
conda create -n yolov5 python=3.7虚拟环境新建成功后,会显示

激活虚拟环境(激活后,第三库将会安装在该虚拟环境下,方便管理)
conda activate your_env_name
# 例如
conda activate yolov5 激活成功后,如下图所示
4.3 下载yolov5代码
如果你有git,则使用git clone
git clone https://github.com/ultralytics/yolov5如果你没有git,在windows,你可以使用Dwonload ZIP下载代码项目。
yolov5代码地址:https://github.com/ultralytics/yolov5
4.4 安装yolov5所需的第三方库:
进入yolov5文件夹目录
cd [path_to_yolov5] 如下图所示

安装第三方库
pip install -r requirement.txt 如下图所示,等待安装完成

5. 直接使用训练好的yolov5模型
5.1 使用pycharm打开yolov5项目

5.2 选择虚拟环境
File -> Settings -> Project:yolov5 -> Python Interpreter -> add -> Conda Enviroment -> Existing Enviroment -> 选择你的虚拟环境路径 -> ok



设置成功后,在pycharm的右下角,会出现你的虚拟环境名字
5.3 测试代码是否能够正常运行
运行左侧的detect.py文件

如果运行结束后没有报错,而且在左侧的runs\detect\exp目录下出现了下面这两张被处理过的图片,就说明前面的操作都木有问题,恭喜!准备工作结束
当然大家也可以在上面显示的路径中,放入自己的图片或视频进行测试
6. 迁移学习模型训练
6.1 数据准备
很多同学为了做自己的项目,要识别特定目标物(比如火焰),因此这里选择火焰数据集作为演示。
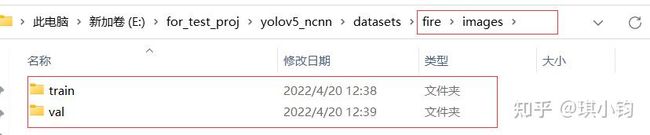
数据集格式介绍:
dataset #(数据集名字:例如fire)
├── images
├── train
├── xx.jpg
├── val
├── xx.jpg
├── labels
├── train
├── xx.txt
├── val
├── xx.txt 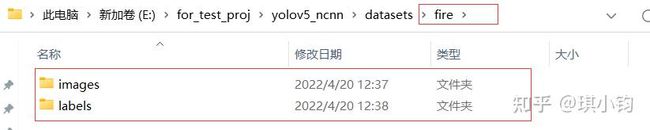
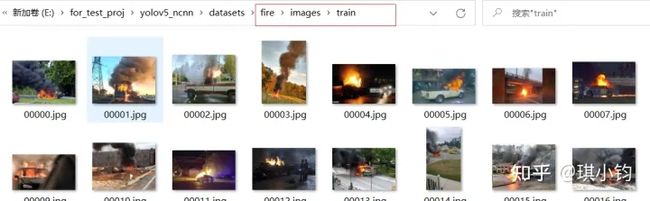
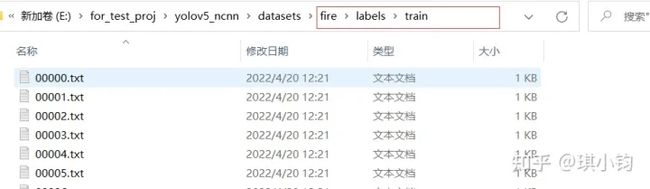
注意:一张图片(xxx.jpg)对应一个标签(xxx.txt)。
如00000.jpg对应标签00000.txt。
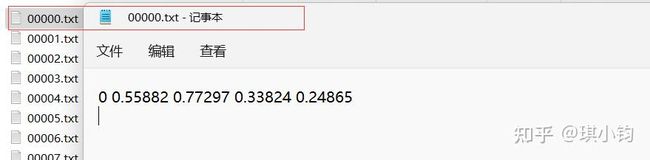
txt中存放标签数据,每一行数字分别表示:目标类别,x,y,w,h
例如:
0 0.55882 0.77297 0.33824 0.24865 其中
-
- x,y是目标的中心坐标,width,height是目标的宽和高。这些坐标是通过归一化的,其中x,width是使用原图的width进行归一化;而y,height是使用原图的height进行归一化。
6.2 添加数据配置文件
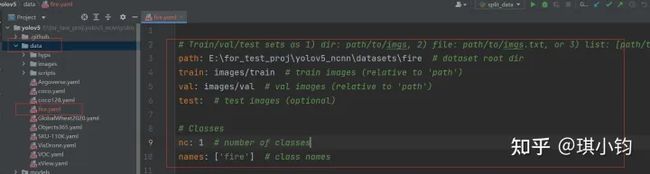
在yolov5/data文件夹下新建fire.yaml。
内容如下所示:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: E:\for_test_proj\yolov5_ncnn\datasets\fire # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
nc: 1 # number of classes
names: ['fire'] # class names其中:
path:数据集的根目录
train:训练集与path的相对路径
val:验证集与path的相对路径
nc:类别数量,因为这个数据集只有一个类别(fire),nc即为1。
names:类别名字。
注意:
train和val 可以是直接读取文件夹,也可以是读取.txt文件建立索引。
你这里用的.txt文件索引,那么就需要把路径填到.txt文件这一级,就像现在。
这里的三个路径用相对路径我踩过坑,还是绝对路径比较稳
参考:
Exception: Dataset not found.解决办法_知道的都知道 不知道的慢慢了解的博客-CSDN博客
https://blog.csdn.net/weixin_45768644/article/details/126119167
6.3 下载预训练模型
现在,我们准备好了数据,接下来,下载好预训练模型,即可开始训练了!当然有可能项目文件里已经下载好了模型数据,比如yolov5s.pt
预训练模型地址:https://github.com/ultralytics/yolov5/releases
选择你所需要的模型下载即可,这里我选择yolov5s.pt下载。
模型下载完成后,将xx.pt复制在yolov5文件夹下。如下图所示:

6.4 开始训练
打开命令行,点击train -> Edit Configurations:

在Parameters,输入对应参数命令
--weights yolov5s.pt --data data/fire.yaml --workers 1 --batch-size 8 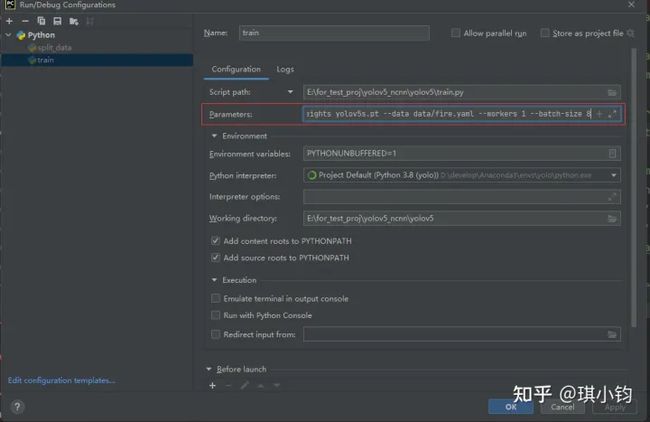
关于参数的说明:
训练模型通过调用模型文件夹下的train.py进行,可以通过--batch参数和--epochs参数调整训练批次大小和训练轮数。YOLOv5提供了在COCO数据集上预训练后的参数,我们可以通过参数--weights yolov5s.pt加载预训练参数进行迁移学习,或在训练大数据集(比如COCO)时用一个空的--weights ''参数从零开始训练。
YOLOv5默认的约30个超参数如随机梯度下降的学习率等默认存储在data/hyps/hyp.scratch-low.yaml文件内,我们可以根据自己的需要进行调参,或者通过选取med或high的超参数版本调节自己需要的数据增强水平。往往提高数据增强水平可以增强模型的泛化性,但有时也不尽然。比如我们这个问题里左右翻转是很有效的,但上下翻转很可能让模型学到错的东西,因为不会有车是翻着行驶的。训练开始后,我们可以在runs/train/exp目录下找到每一个批次训练样本的数据增强结果。
YOLOv5默认的设置在迁移学习时优化了每一层网络的参数,这可能导致过大的计算量和缓慢的计算速度,因此我们也可以通过--freeze参数冻结若干层网络,比如使用--freeze 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14表示冻结了YOLO25个块中的前15个,包括卷积和batch normalization的部分。保持其他设定不变仅仅在fine-tune的时候优化模型头部的参数。超参数和冻结模型参数可以自定义设置,这里我们采用默认的超参数来优化模型参数,且不冻结网络参数,这是由于我们这里有足够多的样本量。
至此,模型则开始训练
部分训练过程如图所示:

中间的可视化结果以及训练好的模型保存在runs文件夹下


6.5 训练结果
在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在runs/train目录下找到生成对若干训练过程统计图。
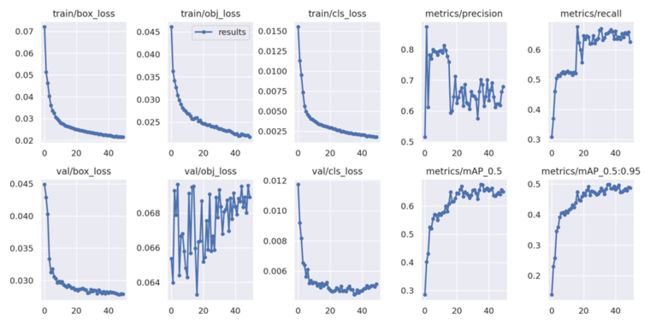
我们可以发现,除了验证集的置信度损失外,训练集和验证集的损失函数都在不断下降。而通过观察验证集的混淆矩阵,发现类别others和van的预测结果相对较差,这可能是由于抽样后样本量减少导致的标签不平衡影响的,因此使用全样本训练模型可能会有所提升。此外,在三四十轮过后模型的损失函数基本稳定,可以考虑减少训练轮数避免过拟合。
针对目标检测模型的评价,一个常用的指标是IoU(Intersection over Union),它描述了我们模型预测的边界框和真实的物体定位框之间的差距。字如其名,IoU函数通过计算这两个边界框的交集区域面积和并集区域面积之比来反映这一差距。一般来说,通常约定如果IoU>0.5就说明这个预测是靠谱的。如果预测的边界框和真实边界框完全重合,那IoU就是1,因此IoU是一个0~1之间的评估变量。
当然,IoU并不能直接用来衡量多目标检测问题的算法精度,因此我们需要引入mAP(mean Average Precision),它指的是在特定的IoU阈值下计算每一类的所有图片的平均准确率。比如这里的[email protected](或者记作mAP@50),就是描述了把IoU阈值设为0.5时计算每一类的所有图片的AP,再对所有类别求平均。
我们发现也对每一轮训练后的模型给出了mAP@50指标,但往往很快就达到了很高的水平,这说明仅仅考虑IoU阈值为0.5可能有些粗糙,因此YOLOv5的另一个评价指标用的是[email protected]:0.95,指的就是考虑把从0.5到0.95之间步长0.05的一串数(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)分别作为IoU阈值计算出的mAP再进行平均。
在我们的训练过程中,mAP50作为一种常用的目标检测评估指标很快达到了较高的0.6以上,而mAP50:95也在训练的过程中不断提升,说明我们模型从训练-验证的角度表现良好。
7. 模型应用
模型训练完成后,将runs/exp/weights下的模型(best.pt)复制在yolov5文件夹下。如下图所示:
开始测试,我们读入一个测试集文件夹进行预测,通过--weight runs/train/exp/weights/best.pt选取验证集上效果最好的权重best.pt进行实验
python detect.py --weights best.pt --source ../datasets/fire/images/val 其中参数:
weights:是你训练好的模型的路径,并且weights支持以下几种格式。
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU--source:是你测试的数据路径,它支持以下几种输入
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream--conf 0.5表示只显示推理置信度大于0.5的目标。
测试结果保存在runs/detect下

8. 参考文献
【狗熊会:用YOLOv5实现目标检测】
https://mp.weixin.qq.com/s?__biz=MzA5MjEyMTYwMg==&mid=2650274455&idx=2&sn=f260c12df854e0ddfe0ad57fdd44a4c5&chksm=8872a5fabf052cec62d55705ae3a37693ad245b2ca78d99247639aa2f92b3df81e8f273636aa&mpshare=1&scene=1&srcid=0110OPYjicKceg9SX97MFXjp&sharer_sharetime=1673423402446&sharer_shareid=4cc1c52116e15fcf66bd7e4ffe6aff7f&version=4.1.0.6007&platform=win#rd
【知乎:保姆式yolov5教程,训练你自己的数据集】
https://zhuanlan.zhihu.com/p/501798155
【CSDN:在CPU上跑yolov5(详细步骤+适合入门)】
https://blog.csdn.net/weixin_54721509/article/details/122983561
【CSDN:YOLOv3训练WiderFace数据集来实现人脸检测】
原文链接:https://blog.csdn.net/sunqiande88/article/details/102414883