【机器学习】(西瓜书)第1章 绪论 & 第2章 模型评估与选择
一、 绪论
1. 什么是机器学习(Machine Learning)?
致力于研究如何通过计算的手段,利用数据(经验)来改善系统自身的性能。
主要研究内容:是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)——将经验数据提供给学习算法,学习算法就能基于数据产生模型;在面对新的情况时,模型会给我们提供相应的判断。(模型泛指数据中学到的结果。)
2. 基本术语
data set: 数据集,数据记录的集合。

sample(or instance): 样本,每条数据记录(关于对象或事件的描述)。
feature(or attribute): 特征,事件或对象的性质。
attribute value: 属性值。
sample space(or attribute space): 属性空间,样本空间,或者为输入空间。
feature vector: 特征向量。将对象或事件的性质features作为坐标轴,假设西瓜的三个属性为三个坐标轴,生成三维空间,则每个西瓜都能在这个空间中找到一个坐标点。而在该空间中,每个点就是一个特征向量。
从数据中执行某个学习算法学得模型的过程称为“学习(learning)”或“训练(training)”。
training data: 训练数据,即训练过程中使用的数据。
training sample: 训练样本,即训练数据中的每个样本。
training set: 训练集,即训练样本组成的集合。
hypothesis: 假设,学得模型对应了关于数据的某种潜在的规律。
为了使得模型具有判断预测(prediction)的好坏,还需要标记(或标签,label),看预测的结果是否符合标记,这样就能知道对样本(sample)预测结果的好坏了。
example: 样例,即拥有了标记的样本。![]() 表示第
表示第 个样例,其中
个样例,其中![]() 是样本
是样本![]() 的标记,
的标记, 是所有标记的集合,称为标记空间“label space”或输出空间。
是所有标记的集合,称为标记空间“label space”或输出空间。
classification: 分类,要预测的是离散值,则学习任务称为分类。
regression: 回归,要预测的是连续值。
binary classification: 二分类,只涉及两个类别的分类学习任务。其中一个类称为正类(positive class),另一个类为反类(negative class)。涉及多个类别,则为多分类(multi-class classification)。
一般地,预测任务是希望通过对训练集![]() 进行学习,建立一个从输入空间
进行学习,建立一个从输入空间 到输出空间的映射
到输出空间的映射![]()
testing: 测试,学得模型后的预测过程。
testing sample: 测试样本,被预测的样本。
clustering: 聚类,将训练集中的西瓜分成若干组,每个称为一个簇(cluster)。课件之前的小专题:【聚类】专题总结——概览 + 划分聚类_bit_100的博客-CSDN博客
supervised learning: 监督学习,训练数据拥有标记信息,代表学习任务有分类和回归。
unsupervised learning: 无监督学习,训练数据无标记信息,代表学习任务为聚类。
generalization: 泛化,学得模型适用于新样本的能力。具有强泛化能力的模型能很好地适用于整个样本空间。
independent and identically distributed, iid: 独立同分布,样本空间中全体样本服从一个未知分布(distribution),获得的每一个样本都是独立地从这个分布上采样得到的。
induction: 归纳,从特殊到一般的泛化(generalization)过程,即从具体的事实归结出一般性规律。
deduction: 演绎,从一般到特殊的特化(specialization)过程,即从基础原理推演出具体状况。
hypothesis space: 假设空间。我们把学习过程看作一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集匹配(fit)的假设,即能够将训练集中的瓜判断正确的假设。

version space: 版本空间,学习过程基于有限训练集进行,在很大的假设空间中,可能存在多个假设与训练集一致,即存在这一个与训练集一致的“假设集合”,则为版本空间。
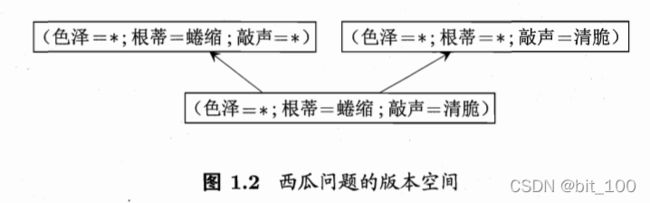
inductive bias: 归纳偏好。通过学习得到的模型对应假设空间中的一个假设。现在有三个与训练集一致的假设,但是它们对应的模型在面临同样的新样本时,会产生不同的输出。但对于一个具体的学习算法而言,必须要产生一个模型,这时学习算法就必须有其归纳偏好。
(归纳偏好可选择奥卡姆剃刀原则(Occam's razor),也可选择多释原则(principle of multiple exlanations))
例如:(黑点:训练样本;白点:测试样本。)
如下图存在多条曲线与有限样本训练集一致,在图(a)中若归纳偏好选择模型A,模型A在测试集上效果也比模型B好,则该算法的归纳偏好与这个预测问题匹配较好。但在图(b)中,若用同样的算法偏好选择模型A,但是B的泛化能力优于A,则该算法的归纳偏好与这个问题本身不匹配。

No Free Lunch Theorem, NFL: 没有免费的午餐定理,该定理表明无论学习算法多聪明或者多笨拙它们的期望性能是相同。关键在于谈论算法性能的优劣,必须要针对具体的学习问题。如上所述,学习算法的归纳偏好与问题是否相配,往往会起到决定性的作用。
3. 发展历程
基于神经网络的连接主义(connectionism):代表工作——感知机(Perceptron),Adaline,BP,深度学习等。性能优越,但学习算法产生的是黑盒模型。
基于统计学习的机器学习:支持向量机(support vector machine,SVM)
基于逻辑表示的符号主义(symbolism):结构学习系统,归纳逻辑程序设计(Inductive Logic programming, ILP),概念学习系统,决策树(decision tree)。逻辑表达式明确,但假设空间太大,复杂度极高。
二、模型评估与选择
明天补上
参考文献:
[1]周志华.机器学习 [M].清华大学出版社, 2016.