ANSOR:一种Auto-Scheduler方法
ANSOR:一种Auto-Scheduler方法
- 背景
- Ansor 方案
-
- Task Scheduler
- Sketch
- Annotation
- Performance fine-tuning
- 评估数据
- 不足
- 参考
本文主要是对论文Ansor: Generating High-Performance Tensor Programs for Deep Learning的学习总结
背景
随着深度学习和各种加算器(也即DSA)的兴起,AI编译器也迎来了发展机遇。当前手工调优的算子库还是主流技术路线,这种技术的路线的缺点是不言而喻的。
TVM提出autoTVM来解决手工写算子的问题,autoTVM是基于模板搜索的算法来找到给定计算的高效实现。然后,由于autoTVM是基于模板搜索,这个模板还是需要对加速器和深度学习比较精通的工程师开发,并且模板搜索本身也限制了搜索空间,这使得产生高效的算子依然十分困难。
为了解决autoTVM的问题,论文ANSOR提出了一种auto scheduler完全自动化生成算子的方法。Ansor构建分层的搜索空间,该空间将high-level结构和low-level的细节解耦,Ansor自动构建计算图的搜索空间,不需要手动开发模板,并且Ansor采用了进化搜索的方法提升了搜索性能,根据论文中给的数据,Ansor能够产生非常高效的代码实现。

此外MLIR的linalg dialect也尝试采用auto schedule的方法生成高效的代码。
Ansor 方案
Ansor通过递归地应用一组灵活的推导规则来自动扩展搜索空间,并在搜索空间中随机采样完整的程序。为了得到非常大的搜索空间,Ansor定义了一个具有两个级别的分层搜索空间:sketch和annotation。将程序的high-level的结构定义为sketches,并将数十亿个low-level选择(如tile size、unroll annotations)作为annotations。在顶层,通过递归应用一些推导规则来生成sketch,在底层,随机注释这些sketch以获得完整的程序。并通过进化搜索和代价模型提供搜索性能。

Ansor流程分为以下4个步骤:
- Task Scheduler:将整个的计算图(computational graph)切分成多个子图,采用梯度下降的方法找到热点子图,然后对热点子图进行重点优化。
- Sketch:提取子图中算子中的高层的特征,对算子进行较粗粒度的优化,确定优化的基本结构。
- Annotation:随机初始化 Tilling Size 和一些 for 循环的策略,得到子图的完整表示。
- Performance fine-tuning:通过进化搜索和代价模型的方式提高搜索性能,并得到最终代码的高效实现。
Task Scheduler
对于DNN的计算图可以拆分成独立的子图,Task Scheduler会挑选出热点子图,进行重点优化。Ansor主要思想是采用梯度下降的方法得到热点子图。
Sketch
Ansor首先对计算子图节点进行拓扑排序,方便后续策略选择。
对于计算密集型算子(如conv、matmul)拥有更多数据重复使用的机会,一般采用tile和fusion结构作为sketch。对于简单的element-wise算子(比如relu、element-wise add)一般采用inline结构作为sketch。

Ansor提出了一种基于推导(derivation-based)的枚举方法,通过递归地应用几个基本规则来生成所有可能的草图。这种方法以DAG作为输入产生一系列的sketch。定义状态 σ = ( S , i ) \sigma=(S,i) σ=(S,i),S 是当前为DAG部分生成sketch,i 是当前工作的节点的index。DAG中节点索引是从输出到输入的拓扑序进行排列。推导是从初始的naive程序和最后一个节点开始。然后尝试将所有推导规则递归地应用于 σ = ( S , i ) \sigma=(S,i) σ=(S,i),得到 σ ′ = ( S ′ , i ′ ) \sigma^{'}=(S^{'},i^{'}) σ′=(S′,i′),其中 i ′ < i i^{'}i′<i。 这样工作节点的索引 i 就会单调减少,当 i 变成0的时候状态就是终止状态。在枚举过程中,可以将多个规则应用于一个状态以生成多个后续状态。一个规则也可以产生多个可能的后续状态,所以维护一个队列来存储所有中间状态。当队列为空时,推导过程结束。一般来说子图生成的sketch数量会小于10。
Derivation rules
Table1列出了用于CPU的derivation rules。 i s S t r i c t I n l i a b l e ( S , i ) isStrictInliable(S,i) isStrictInliable(S,i)表示节点 i 是一个elememt-wise op,可以被inline(例如element-wise add、relu)。 h a s D a t a R e u s e ( S , i ) hasDataReuse(S,i) hasDataReuse(S,i)表示节点 i 是一个计算密集型op,并且在op内有大量数据重复使用的机会(比如conv、matmul)。 h a s F u s i b l e C o n s u m e r ( S , i ) hasFusibleConsumer(S,i) hasFusibleConsumer(S,i)表示节点 i 有唯一的消费节点 j ,并且节点 j 可以被融合到节点 i (比如matmul+bias_add、conv+relu)。 h a s M o r e R e d u c t i o n P a r a l l e l ( S , i ) hasMoreReductionParallel(S,i) hasMoreReductionParallel(S,i)表示节点 i 在空间维度上几乎无法并行但在reduction维度上有足够的并行机会(例如二维矩阵乘, C 2 × 2 = A 2 × 512 ∗ B 512 × 2 C_{2×2}=A_{2×512}*B_{512×2} C2×2=A2×512∗B512×2)。Ansor对计算图进行op的数学表达式进行静态分析得到这些规则策略。
Rule1只是是简单的跳过一个节点,如果它不是严格inline的。Rule2是对于严格inline的节点总是执行inline操作。Rule1和Rule2的条件是互斥的,i>1的状态总是可以满足其中之一并继续推导。
Rule3、4、5用于处理有重复使用数据的节点的multi-level tile和fusion。Rule3对重复使用数据的节点执行multi-level tile。对于CPU,Ansor使用一个”SSRSRS“ 的tiling结构,其中S代表空间循环的一个tile level,R代表reduction 循环的一个tile level。”SSRSRS“将一个原始3层循环 ( i , j , k ) (i,j,k) (i,j,k)扩展成10层循环 ( i 0 , j 0 , i 1 , j 1 , k 0 , i 2 , j 2 , k 1 , i 3 , j 3 ) (i_0 , j_0 , i_1 , j_1 , k_0 , i_2 , j_2 , k_1 , i_3 , j_3 ) (i0,j0,i1,j1,k0,i2,j2,k1,i3,j3)。
Rule4执行multi-leve tile和fuse消费者。例如,可以将element-wise节点(bias add、relu)fuse到tiled节点(matmul、conv)。
Rule5为当前有数据重复使用的节点没有消费节点增加一个cache节点,这种情况下默认直接将暑促和写到主存中,由于内存访问的高延迟而导致效率低下,通过增加cache节点,我们在 DAG 中引入了一个新的可融合的消费者节点,然后可以使用Rule4将这个新添加的cache节点融合到最终的输出节点中。 cache节点融合后,现在最终输出节点将其结果写入cache中,最后cache的结果再写入主内存。
Rule6将reduction 循环分解成空间循环以获取更大的并行性。

Examples
上图显示的例子,根据DAG产生如下sketchs:


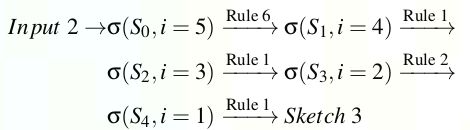
Customization
虽然Ansor提供了比较丰富的推导规则,但是对于特殊的算法和加速器intrinsics需要特殊的tile 结构,Ansor允许用户注册自己的推导规则。
Annotation
Sketchs仅仅是tile的结构,不包含特定的tile size和loop annotate,比如并行、展开和性量化。需要给sketchs添加annotates使他们成为完整的调优和评估程序。
对于生成的一些列sketchs,随机选择一个sketch,随机填充tile size,并行一些外循环,向量化一些内循环,并展开一些内循环。还随机改变一些节点的计算位置,对tile结构进行了微调。Annotation 只负责随机的生成代码,并不会考虑搜索性能,性能由 Performance fine-tuning来保证。结果见以上examples。
Performance fine-tuning
sketch和annotation很好地保证了搜索空间的覆盖,但是搜索的性能无法保障。Ansor采用了进化搜索(evolutionary
search)和代价模型(a learned cost model)的调优器。
fine-tuning是迭代进行的,在每次迭代,首先使用进化搜索根据学习后的代价模型找到一小批性能还可以的程序。 然后在硬件上测量这些程序以获得实际的性能。 最后,从中获得的分析数据用于重新训练代价模型,使其更加准确。
进化搜索是一种源于生物进化得到的通用元启发式算法(meta-heuristic algorithm)。 通过对高质量程序进行迭代转化,可以生成具有潜在更高质量的新程序。 进化开始采样的初代, 为了产生下一代,首先根据一定的概率从当前一代中选择一些程序,选择程序的概率与可学习的代价模型预测的合适模型成正比,也就是说具有更高性能的程序被选择的概率更高。 对于在采样过程中做出的决策,我们都设计了相应的进化操作来重写和微调它们。
基于可学习的代价模型拥有很好的可移植性,因为单个模型设计可以通过输入不同的训练数据来重用于不同的硬件后端。
评估数据
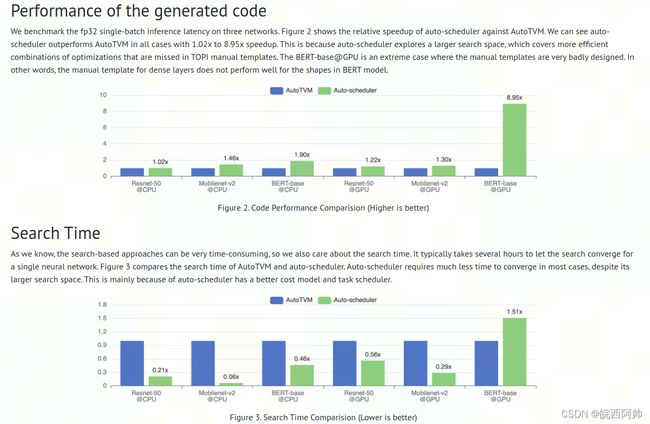
性能数据来源TVM官网,也可以查看论文最后给出数据。
不足
- 不支持可变shape
- 不支持sparse算子
- 不支持特殊算子
参考
- [1] Ansor: Generating High-Performance Tensor Programs for Deep Learning
- [2] Introducing TVM Auto-scheduler (a.k.a. Ansor)