论文翻译:基于麦克风和AEC误差互相关性的归一化的双讲检测
NORMALIZED DOUBLE-TALK DETECTION BASED ON MICROPHONE AND AEC ERROR CROSS-CORRELATION
文章目录
-
- NORMALIZED DOUBLE-TALK DETECTION BASED ON MICROPHONE AND AEC ERROR CROSS-CORRELATION
- 1. 介绍
- 2. 之前的工作
- 3. 基于麦克风信号和AEC误差互相关性的归一化双声检测
-
- 3.1 新检验统计量与Benesty检验统计量之间的关系
- 4. 混合双讲检测
- 5. 实验和结果
- 6. 结论
- 参考文献
摘要-在本文中,我们提出了两种不同的回声消除(AEC)双声检测方案。首先,我们提出了一种基于麦克风信号和消除误差之间的互相关系数的新型归一化检测统计量。决策统计量的设计方式使其能够满足最佳双声探测器的需求。我们还表明,所提出的检测统计量收敛于最近提出的基于归一化互相关的双谈话检测器[1],这是最著名的基于互相关的检测器。接下来,我们提出一种基于互相关系数和两个信号检测器的新型混合双声检测方案。混合算法不仅可以检测双声,还可以有效地检测和跟踪任何回声路径变化。我们将结果与其他基于互相关的双关语检测器进行比较,以显示其有效性。
1. 介绍
大多数电话会议通话都是在有回声的情况下进行的[2];如果语音与其回声之间的延迟超过几十毫秒,则回声很明显让人注意到。回声消除器 (AEC)用于消除由于扬声器-麦克风所处环境而产生的回声 [3]。回声消除是通过自适应合成回声的副本并从回声损坏的信号中减去结果来实现的[2]。当近端发言者处于活动状态或语音同时来自远端和近端时,如果启用自适应,滤波器系数将与真正的回声路径脉冲响应背离。双通话检测器用于在近端语音期间停止AEC的滤波器适应[3]。
双声检测在回声消除中起着非常重要的作用。双声检测算法应该能够快速准确地检测出双讲情况,以便尽快冻结适应;同时,它应该能够跟踪任何回声路径的变化,并且应该能够将双讲与回声路径的变化区分开来[4]。为了解决这个问题,本文提出了两种不同的双讲检测技术。用于双讲检测的最佳决策变量 ξ 应表现为[3]:
- 如果双讲不存在,即 v = 0 , ξ ≥ T v=0,ξ \geq T v=0,ξ≥T。
- 如果双讲存在,即 v ≠ 0 , ξ < T v \neq0,ξ
v=0,ξ<T 。阈值 T 必须是独立于数据的常量,并且当 v = 0 v = 0 v=0时,决策统计量 ξ 必须对回声路径变化不敏感。
图1显示了自适应回声消除器的基本结构。远端信号 x x x通过房间脉冲响应 h h h滤波,得到回声信号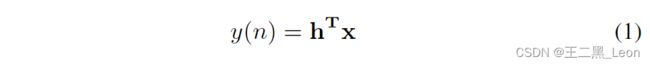
其中
并且 L L L是回声路径的长度。将此回声信号添加到近端语音信号 v v v中,以获得麦克风信号![]()
在时刻 n n n时,误差信号定义为:![]()
并且误差信号被用于调整AEC自适应滤波器^h的 L L L抽头。
本文的结构如下。在第 2 节中,我们回顾了以前的双讲检测算法。在第3节中,提出了新颖的归一化双讲检测算法,并且我们还展示了所提出的算法与[1]中提出的算法之间的联系。我们在第4节中提出了新的混合双声检测方案。接下来,我们在第5节中对提议的算法进行了全面的研究,然后在第6节中进行了总结和结论。
2. 之前的工作
参考图1,Ye和Wu[4]首先提出使用扬声器播放的远端信号矢量 x x x与AEC的消除误差 e e e, r e x = E [ e x T ] r_{ex} = E[ex^T] rex=E[exT]之间的互相关矢量作为双声检测的基础。在本文中,我们将此算法称为 XECC。Benesty [1]的仿真结果表明,这种方法不能很好地检测双重谈话,理论推导提供了进一步的见解。请注意,近端语音 v v v独立于远端信号 x x x,并且假设所有信号均值为零,则 AEC 的误差信号与扬声器信号之间的互相关值为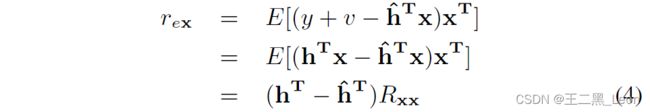
其中 E[•] 表示数学期望,而 R x x = E [ x x T ] R_{xx} = E[xx^T] Rxx=E[xxT]。显然,从等式4中我们观察到只有当回声路径发生变化时, r e x r_{ex} rex才会很高;因此,这种方法更适合于跟踪回声路径变化,而不是检测双端通话。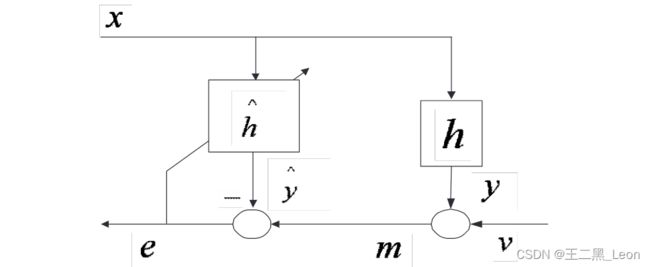
图一:基本AEC模型
最近,贝内斯蒂等人。[1] [5]提出了一种基于远端信号向量 x x x与麦克风信号标量 m ( r x m = E [ x m ] ) m(r_{xm} = E[xm]) m(rxm=E[xm])的互相关双讲检测算法,本文将其称为XMCC。贝内斯蒂用于检测 [1] 中的双重谈话的决策统计量由下式给出:![]()
其中 R x x R_{xx} Rxx较早定义以及麦克风信号的方差 ( σ m 2 ) (σ_m^2) (σm2)为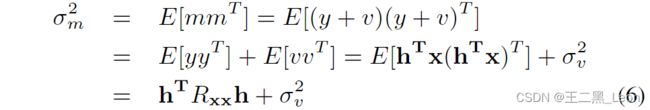
其中 σ v 2 σ_v^2 σv2是近端语音功率。
3. 基于麦克风信号和AEC误差互相关性的归一化双声检测
我们建议使用消除误差 e e e和麦克风信号 m m m, r e m = E [ e m ] r_{em} = E[em] rem=E[em] 之间的互相关,而不是使用第2节中讨论的 r e x r_{ex} rex 或$ r_{xm}$,作为双声检测的基础。该算法在本文中称为MECC。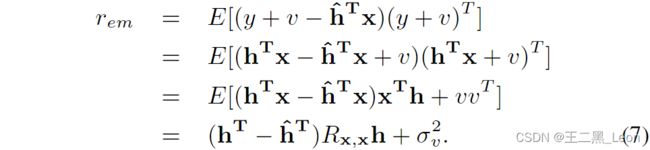
我们将新的规范化决策统计定义为: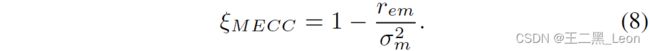
将等式6和7代入8,我们得到: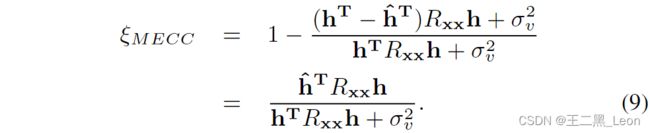
我们从等式 9 中观察到,对于 v = 0 v = 0 v=0, ξ M E C C ≈ 1 ξMECC ≈ 1 ξMECC≈1,对于 v ≠ 0 v \neq 0 v=0, ξ M E C C < 1 ξM ECC < 1 ξMECC<1。因此,所提出的检测统计量满足了最优双讲检测器的需求。
图二:显示文中提出的MECC和XMCC双讲检测器的收敛性
(8)中 r e m r_{em} rem 和 σ m 2 σ^2_ m σm2的值是精确的,其在实践中不可用。因此,最终决策统计数据由下式给出: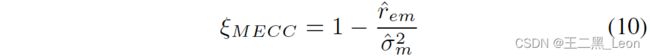
这是基于估计的^ r e m [ n ] r_{em}[n] rem[n]和^ σ m 2 σ^2_ m σm2。这估计值是通过使用指数递归加权算法 [6] [7] 找到的:
其中 e [ n ] e[n] e[n]是时刻n时捕获的消除误差样本, m [ n ] m[n] m[n]是时刻n时捕获的麦克风信号样本,λ 是指数加权因子。如果![]()
我们的结论是,捕获的麦克风信号样本被近端语音破坏,并停止了AEC自适应滤波器的适应。否则,我们将继续适应。
除了简单之外,文中所提出的检测统计量的主要优点是只需要计算最大互相关,而不是计算其他算法所需的整个互相关向量。与其他算法相比,可节省大量计算成本;我们只需要 2 次乘法、2 次加法、1 次减法和 1 次除法来计算每个样本的决策统计量(即每个样本 6 次运算),而对于Benesty检验统计量,需要 3 L + 3 3L + 3 3L+3次运算来计算每个样本的检测统计量,其中 L L L是帧大小(通常为 L ≥ 512 L ≥ 512 L≥512)。
3.1 新检验统计量与Benesty检验统计量之间的关系
本文提出的决策统计量由(10))给出,理论上可以重写为(9),Benesty的双讲决策统计量在(5)中给出。决策统计是不同的,因为前者基于 r e m r_{em} rem,后者基于 r x m r_{xm} rxm。尽管决策统计信息不同,但它们会导致产生类似的表达式。在 (5)中代入 r x m = R x x h r_{xm} = R_{xx}h rxm=Rxxh和$ σ^2_m = h^TR_{xx}h + σ^2_v$,我们得到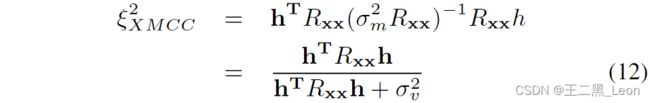
并且从(9)中我们有: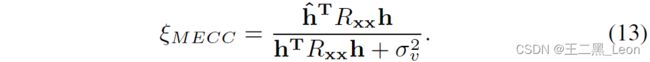
除了平方根之外,决策统计量之间的另一个区别还在于分子;我们有 ξ M E C C ξMECC ξMECC中 AEC 滤波器^ h T h^T hT的抽头和 ξ X M C C ξXMCC ξXMCC中的真实回声路径脉冲响应 h T h^T hT 。然而,为了实际实现和计算简单性,[1]中的作者用 ˆ h T ˆh^T ˆhT代替 h T h^T hT ,从而产生类似的决策统计。图 2 中的模拟表明,与 Benesty 的检验统计量相比,文中提出的决策统计量具有相似的性能。然而,我们的算法要简单得多,计算效率也更高。
4. 混合双讲检测
在本节中,我们介绍了一种基于麦克风和AEC消除误差之间的互相关测量的混合双声检测器,类似于第三节中提出的想法,以及基于语音检测和基于实时循环学习(RTRL)的鉴别器的双声检测算法[8]。混合双声检测算法的架构如图 3 所示。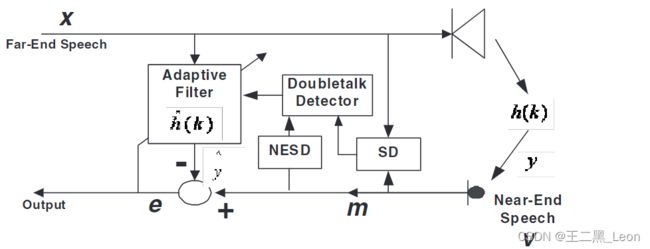
图三:混合双讲检测模型
在此算法中,我们在回声消除误差信号 e e e和由估计的互相关函数(ECC)给出的麦克风信号 m m m之间使用不同的互相关度量: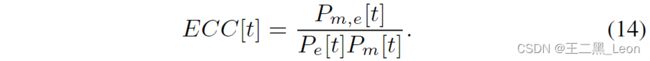
ECC是帧中相关性的最大值,并使用指数递归加权算法 [6] [7] 对其进行更新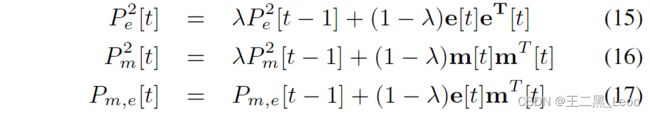
其中$e[t] 是时间帧 t 中捕获的消除误差向量, 是时间帧 t 中捕获的消除误差向量, 是时间帧t中捕获的消除误差向量,m[t] 是时间帧 是时间帧 是时间帧t$中捕获的麦克风信号向量,λ 是指数加权因子。或者,我们也可以使用(10)中给出的MECC检验统计量。λ 值越小,跟踪能力越好,但估计精度越差。在实践中,对于缓慢的时变信号,通常选择 0.9 ≤ λ ≤ 1 0.9≤λ≤1 0.9≤λ≤1[4]。我们从(14)中观察到,每当回声路径发生变化和/或当近端语音存在时,互相关性都很高。为了将近端语音与回声路径变化区分开来,我们使用基于实时循环学习(RTRL)[8]的语音检测器和信号判别器,这将在下面描述。
频域逻辑判别语音检测器用于检测语音的存在[9]。类概率被估计为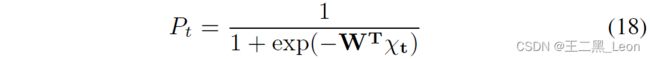
其中 P t P_t Pt是时间帧 t 处的语音概率, W T W^T WT是经过训练的权重( 1 × f r e q u e n c y b i n s 1×f requencybins 1×frequencybins), χ t χ_t χt 是时间帧 t 处每个频率箱中提取的特征的向量。训练的权重 W T W^T WT是使用实时循环学习[10]获得的,并通过离线训练获得。有关语音检测器及其训练过程的详细讨论,请参见 [8]。
我们在麦克风上使用两个检测器来检测近端语音的存在,如图3所示。对于麦克风信号检测器(NESD),我们使用估计的后通道SNR的对数作为特征[9]:![]()
其中 N N E N_{NE} NNE是近端频率箱 $k $ 和时间帧 t t t 中的噪声能量。噪声功率 N 可以使用 [11] 进行跟踪。在本文中,我们使用最小跟踪器(对于每个频率箱,我们回顾几帧(例如25)并选择信号的最低值),然后进行平滑处理,以跟踪本底噪声[11]。该NESD检测器在麦克风上提供语音的存在,这可能是由于近端语音或远端回声。
为了区分近端语音和远端回声,我们使用特殊的检测器/鉴别器SD,这需要将近端语音与远端回声区分开来的功能。因此,我们使用麦克风信号 M M M 的瞬时功率与远端信号 X X X 的瞬时功率之比的对数作为特征,即![]()
在[8]中观察到,提取的特征对于不同的场景是不同的。提取的特征通常仅针对近端语音最大,对于仅回声情况最小,对于双重通话情况,提取的特征介于两者之间。不同的特征水平对应于不同的概率水平;较大的特征对应于较高的概率。对于仅回声情况,提取的特征始终为低,与回声路径无关;因此,在没有近端语音的情况下,特殊的检测器/消旋器与回声路径无关。
当两个探测器都指示语音的存在时,我们确认近端语音的存在。基于语音检测的双声检测器[8]在单独用于双声检测时不会提供卓越的性能。然而,通过将其与所提出的互相关度量相结合,可以提高性能。混合式双讲探测器的工作原理如下:
- 当两个探测器都指示语音存在的高概率(即 P N E S D ( t ) ≥ P T h r e s h o l d 1 P_{NESD}(t)≥P_{Threshold_1} PNESD(t)≥PThreshold1和 P S D ( t ) ≥ P T h r e s h o l d 2 P_{SD}(t)≥P_{Threshold_2} PSD(t)≥PThreshold2)和估计的互相关 E C C ( t ) ≥ R t h ECC(t)≥R_{th} ECC(t)≥Rth时,麦克风信号的捕获帧被近端语音破坏。
- 当 P N E S D ( t ) ≥ P T h r e s h o l d 1 P_{NESD}(t)≥P_{Threshold_1} PNESD(t)≥PThreshold1、 P S D ( t ) < P T h r e s h o l d 2 P_{SD}(t)
- 当 P N E S D ( t ) ≥ P T h r e s h o l d 1 P_{NESD}(t)≥P_{Threshold_1} PNESD(t)≥PThreshold1、 P S D ( t ) < P T h r e s h o l d 2 P_{SD}(t)
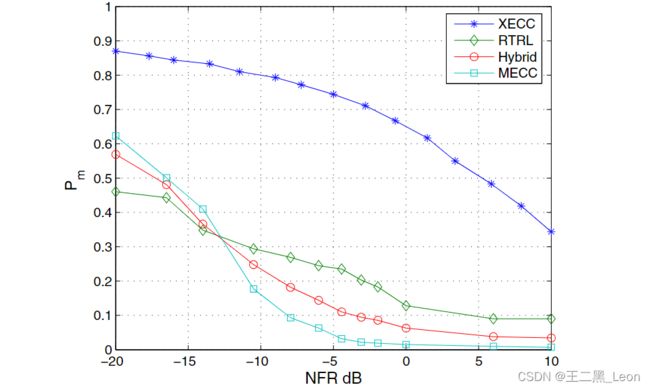
图四:P_m作为文中提出的MECC和CCSD双讲探测器和XECC双讲探测器的NFR函数,其中P_f = 0.1。
在第一种情况下,我们停止自适应滤波器系数的调整,但在最后两个条件下继续适应。图4中的结果显示使用ECC,但在混合双讲检测器中使用MECC检验统计量(8)的性能可能等于或略优于使用ECC检验统计量。
5. 实验和结果
现在,我们介绍所提出的双讲探测器的仿真结果。该性能的特征在于在误报概率 ( P f P_f Pf) 约束下,未命中概率 ( P m P_m Pm) 是近端到远端语音比 (NFR) 的函数 [5]。未命中( P m P_m Pm)的概率是存在时未检测到(未命中)双重谈话的概率;因此, P m P_m Pm 值越小,表示性能越好。为了评估所提出的双关语探测器,我们遵循[5]。
以16 KHz采样的录制数字语音用作远端语音 x x x 和近端语音 v v v ,并将测量的 L = 8000 L = 8000 L=8000 样本(500ms)的 1 0 ′ × 1 0 ′ × 8 ′ 10'×10'× 8' 10′×10′×8′ 房间的脉冲响应用作扬声器 - 麦克风环境 h h h 。我们将结果与[4]中提出的基于传统互相关(XECC)的双声探测器和[8]中提出的基于RTRL的双声探测器进行了比较。在 P f = 0.1 P_f = 0.1 Pf=0.1 的约束下,四种方法的 P m P_m Pm 特性如图 4 所示。很明显,在全NFR值范围内,本文提出的混合的归一化检测统计量(MECC)的性能明显优于传统的(XECC)双扰检测器。此外,可以观察到,对于大多数NFR值,混合双声检测方案的性能优于基于RTRL的双响检测器。因此,我们得出结论,通过将RTRL双话检测器与所提出的互相关测量方法相结合,可以提高其性能。在较低的NFR值下,RTRL和混合双声检测器的性能优于基于最佳测试统计量的MECC算法。性能提高最有可能的原因,是由于RTRL针对存在噪声的情况下改进了语音检测功能。
应该注意的是,本文所提出的归一化决策统计量(MECC)的性能与贝内斯蒂检验统计量(XMCC)完全相同,后者是众所周知的基于互相关的双声探测器。然而,我们的检测统计在计算上非常有效,检测阈值 T T T 与数据无关,并且对回声路径变化不敏感。
6. 结论
我们提出了两种不同的双声检测技术。首先,我们引入了新颖的归一化决策统计;其所提出的检测统计量满足了最优双声检测器的需求,计算效率非常高,并且收敛于最知名的基于互相关的双讲检测器。接下来,我们制定了混合双声检测方案。混合双谈话探测器逐帧工作;该算法不仅可以检测双声,还可以检测和跟踪任何回声路径变化。不过这是以增加计算复杂性为代价实现的。
参考文献


注:由于本文为博主自己翻译的仅供自己学习记录,为不影响文章的阅读性。公式和图片直接从文章中截图使用。如有错误,请联系博主改正!!!