小女也爱葵花宝典---读懂编译原理之词法分析(2)
上一编文章中的词法分析没有写全,还不能识别关键字,小女继续添加识别关键字的功能.
void toker(char* cinput ,scrWord *wordTable) {// cinput输入的单词, wordTable单词表之后讲解 int Wordlen=strlen(cinput);//得到输入串的长度 scrWord *lpWordTable=wordTable; char* lexemBegin=cinput;//串的开始指针 char* lexemEnd=cinput; //串的结束指针 bool isNewWord=false;//是否是新词单 bool isBreak=true;//是否是空格 int count=0;//记录一共有几个单 while(*lexemEnd!=';') { if((*(lexemEnd-1))!=' ' && (*lexemEnd==' ' || *lexemEnd=='(' || *lexemEnd==')'))//这里之后会改进 isNewWord=true;// else isNewWord=false; if((*lexemEnd==' ' || *lexemEnd=='(' || *lexemEnd==')') && isNewWord==true) { scrWord *wordTable2=new scrWord();//单词表 memset(wordTable2->data,0,100);//内存初始化 cpystr(wordTable2->data,lexemBegin,lexemEnd-lexemBegin);//单词表 lpWordTable->next=wordTable2;//用链表生成的单词表 lpWordTable->len=lexemEnd-lexemBegin;// 单词长度 lpWordTable=lpWordTable->next; lexemBegin=lexemEnd; //新添加的代码 if(cmptostr("create",lexemBegin,lexemEnd-1-lexemBegin)) { //识别后关键字create后添加到单词表,这种识别关键字的方法是小女自己想出 //来的,这种写法不太好,多个子关键字就要加多个if } //新添加的代码 } lexemEnd++; if(lexemEnd-lexemBegin>Wordlen) { return; } } }
以上代码添加了关键字create识别,这种方法不好,下面把代码改进成龙书中说的:状态图识别
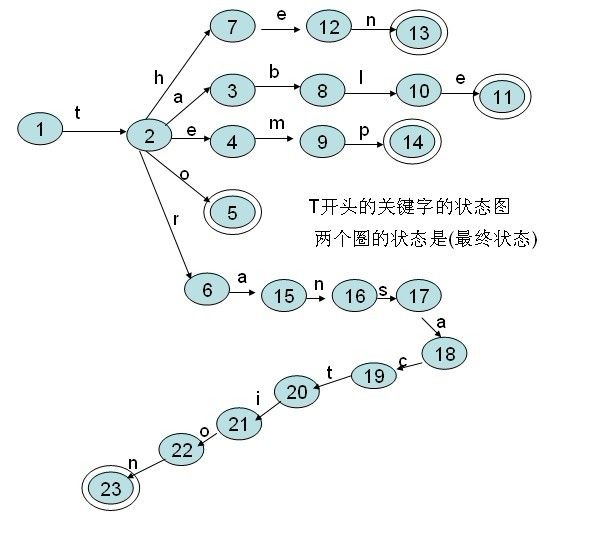
这张状态图包今了sql语法中以T打头的关键字:then,table,temp,to ,transaction这5个关键字
if(cmptostr("create",lexemBegin,lexemEnd-1-lexemBegin)) { //识别后关键字create后添加到单词表,这种识别关键字的方法是小女自己想出 //来的,这种写法不太好,多个子关键字就要加多个if }
这段代码替换成:
int k=-1; switch(tolower(*lexemBegin)) {//大家可以自己完成C打头的关键字 case 't': //实现T打头的关键字的识别,真返回1,假返回-1. k=GetKeyThen(lexemBegin,lexemEnd,360); break; }
GetKeyThen函数实现如下: int GetKeyThen(char* lexemBegin,char* lexemEnd,int state) {//代码要结合上图来看 char *lexemBegin1=lexemBegin;//单词的开始 char *lexemEnd1=lexemEnd; //单词的结束 int j=lexemEnd1-lexemBegin1+1; //单词的长度 for(int i=0;i<j;i++) { char* nextstr=lexemBegin1+1;//取下一个单词 switch(state) { case 360:// 关键字的识别码自己定 if(tolower(*nextstr)=='h') state=7; else if (tolower(*nextstr)=='a') state=3; else if (tolower(*nextstr)=='e') state=4; else if (tolower(*nextstr)=='o') state=5; else if (tolower(*nextstr)=='r') state=6; else return -1; break; case 7: if(tolower(*nextstr)=='e') state=12; break; case 12: if(tolower(*nextstr)=='n') state=13; break; case 13: return 1; break; case 3: if(tolower(*nextstr)=='b') state=8; break; case 8: if(tolower(*nextstr)=='l') state=10; break; case 10: if(tolower(*nextstr)=='e') state=11; break; case 11: return 1; break; case 4: if(tolower(*nextstr)=='m') state=9; break; case 9: if(tolower(*nextstr)=='p') state=14; break; case 14: return 1; break; case 5: return 1; break; case 6: if(tolower(*nextstr)=='a') state=15; break; case 15: if(tolower(*nextstr)=='n') state=16; break; case 16: if(tolower(*nextstr)=='s') state=17; break; case 17: if(tolower(*nextstr)=='a') state=18; break; case 18: if(tolower(*nextstr)=='c') state=19; break; case 19: if(tolower(*nextstr)=='t') state=20; break; case 20: if(tolower(*nextstr)=='i') state=21; break; case 21: if(tolower(*nextstr)=='o') state=22; break; case 22: if(tolower(*nextstr)=='n') state=23; break; case 23: return 1; break; } lexemBegin1++; } return -1;//没识别到返回-1 }
以上代码改进了词法分析的功能,在下一编中小女将讲语法分析,并把词法分析完善.
下面,给出完整的代码.
#include "stdafx.h" #include<stdio.h> #include<string.h> #include<stdlib.h> int GetKeyThen(char* lexemBegin,char* lexemEnd,int state); typedef struct scrWord { char data[100];//词素 int len; scrWord* next; scrWord* Property;//属性 }scrWord; char* opSetStr(const char* str) { printf("sdfsdf"); return "sdf"; } void cpystr(char* des ,char* scr,int len) { for(int i=0;i<len;i++) { *des=*scr; des++; scr++; } } bool cmptostr(char* scr ,char* lexemBegin ,int len) { for(int i=0;i<len;i++) { if(tolower(*scr)!=tolower(*lexemBegin)) return false; lexemBegin++; scr++; } return true; } void toker(char* cinput ,scrWord *wordTable) { int Wordlen=strlen(cinput); scrWord *lpWordTable=wordTable; char* lexemBegin=cinput; char* lexemEnd=cinput; char* forward=cinput; bool isNewWord=true; bool isBreak=true; int count=0; while(*lexemEnd!=';') { if((*(lexemEnd+1))!=' ' && (*lexemEnd==' ' || *lexemEnd=='(' || *lexemEnd==')')) isNewWord=true; else isNewWord=false; if((*lexemEnd==' ' || *lexemEnd=='(' || *lexemEnd==')') && isNewWord==true) { scrWord *wordTable2=new scrWord(); memset(wordTable2->data,0,100); cpystr(wordTable2->data,lexemBegin,lexemEnd-lexemBegin);//单词表 lpWordTable->next=wordTable2; lpWordTable->len=lexemEnd-lexemBegin; lpWordTable=lpWordTable->next; int k=-1; switch(tolower(*lexemBegin)) { case 't': k=GetKeyThen(lexemBegin,lexemEnd,360); break; } if(k==-1) { //词素为关键字则属性为空 lpWordTable->Property=NULL; } lexemBegin=lexemEnd+1; } lexemEnd++; if(lexemEnd-lexemBegin>Wordlen) { return; } } } int GetKeyThen(char* lexemBegin,char* lexemEnd,int state) { char *lexemBegin1=lexemBegin; char *lexemEnd1=lexemEnd; int j=lexemEnd1-lexemBegin1+1; for(int i=0;i<j;i++) { char* nextstr=lexemBegin1+1; switch(state) { case 360: if(tolower(*nextstr)=='h') state=7; else if (tolower(*nextstr)=='a') state=3; else if (tolower(*nextstr)=='e') state=4; else if (tolower(*nextstr)=='o') state=5; else if (tolower(*nextstr)=='r') state=6; else return -1; break; case 7: if(tolower(*nextstr)=='e') state=12; break; case 12: if(tolower(*nextstr)=='n') state=13; break; case 13: return 1; break; case 3: if(tolower(*nextstr)=='b') state=8; break; case 8: if(tolower(*nextstr)=='l') state=10; break; case 10: if(tolower(*nextstr)=='e') state=11; break; case 11: return 1; break; case 4: if(tolower(*nextstr)=='m') state=9; break; case 9: if(tolower(*nextstr)=='p') state=14; break; case 14: return 1; break; case 5: return 1; break; case 6: if(tolower(*nextstr)=='a') state=15; break; case 15: if(tolower(*nextstr)=='n') state=16; break; case 16: if(tolower(*nextstr)=='s') state=17; break; case 17: if(tolower(*nextstr)=='a') state=18; break; case 18: if(tolower(*nextstr)=='c') state=19; break; case 19: if(tolower(*nextstr)=='t') state=20; break; case 20: if(tolower(*nextstr)=='i') state=21; break; case 21: if(tolower(*nextstr)=='o') state=22; break; case 22: if(tolower(*nextstr)=='n') state=23; break; case 23: return 1; break; } lexemBegin1++; } return -1; } int main(int argc, char* argv[]) { scrWord *wordTable=new scrWord(); char * str="create table then temp ffek transaction to thne hts(fe int);"; toker(str,wordTable); return 0; }