使用tushare社区实现简单的三因子模型
文章目录
- 一、关于Tushare
- 二、三因子模型
- 三、过程步骤
-
- 1.变量数据的选取
- 2、因子的计算方法
- 3、三因子模型回归选股
- 总结
最近在学习金融量化分析,找了一些网络接口都不太好用,昨天朋友推荐了一个开源的股票数据接口包TuShare,尝试了一下感觉像找到了宝,下面是大致的使用方法,分享出来。
一、关于Tushare
TuShare是一个著名的免费、开源的python财经数据接口包。其官网主页为:TuShare -财经数据接口包。该接口包如今提供了大量的金融数据,涵盖了股票、基本面、宏观、新闻的等诸多类别数据(具体请自行查看官网),并还在不断更新中。
二、三因子模型
在资本资产定价模型(CAPM)等传统理论下,投资组合的全部风险溢价由Beta系数表示。但是这一模型在解释股票市场回报的现实情况上,如一月效应,遇到了诸多挑战。法马和佛伦奇(1992)观察发现市值较小、账面市值比较高的两类公司更有可能取得优于市场水平的平均回报率。由此三因子模型通过引入二个新的解释变量[1]:市净率、公司规模,与CAPM中的市场指数一同估计股票的回报水平:
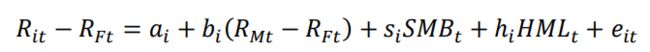
上式中表示股票组合 i 在时间 t 的收益率;表示 t 时刻的无风险利率;表示市场组合的收益率,表示 t 时期流通市值低的公司组合和流通市值高的公司组合回报率之差;表示 t 时期的账面市值比高的价值型公司和账面市值比低的成长性公司的组合回报率之差;表示残差。
Fama-French 三因子模型的贡献在于,根据新加入 CAPM 模型的公司规模因素和账面市值比因素构建了不同的股票组合,进而引出这两个要素的代理变量SMB 和 HML,使得模型的实证检验解释能力增强。
假设公式中的三个因子可以很好的解释个股的收益率,则超额收益率的长期均值应该是 0。那么对于某个时期的股票,回归得到 < 0,说明这段时间里面收益率偏低,根据市场有效性,在未来的一段时间内,低估值的股票价格会回归到均衡位置,所以应该买入 < 0的股票,以期在未来的均值回复过程中获利。如果回归得到的股票 > 0,说明这段时间里面收益率偏高,根据市场有效性,在未来的一段时间内,这些高估值的股票价格将会下降,故投资者应该卖出(做空)这类股票。
三、过程步骤
1.变量数据的选取
所需要的数据类型分为两种,其一是用来计算解释变量的投资组合分组指标,包括上市公司股票规模,账面市值比等,其二是用来计算被解释变量的上市公司日度收益率数据和日度无风险收益率的样本数据。
其中日度无风险收益率的数据来自国泰安数据库,使用的无风险利率基准为“定期-整存整取-一年利率”,根据复利方法,将年度的无风险利率转化为日度数据。为了使得市场汇报率所涵盖的股票范围尽可能大,选取上证 A 指的日度收益率作为市场回报率的代表。上市公司股票收益率、账面市值比等的数据来自 Tushare 金融大数据开放社区,通过公开的 python 接口进行调用。
在研究的时间区间上,本文选取 2019 年初到 2020 年 7 月份的时间区间,总共 384 个交易日的日度数据进行处理。
2、因子的计算方法
对于SMB和HML这两个解释变量因子,根据每天的流通市值将股票分为1:1 的大市值(B)和小市值(S)股票;根据发行股票的公司的账面市值比将股票分成 3:4:3 的高中低(H/M/L)三组,总共是 2*3 共计 6 种投资组合:SL、SM、SH、BL、BM、BH。接下来根据市值加权平均的方法计算得到各组的收益率,再根据下式计算得到 SMB 和 HML 序列:
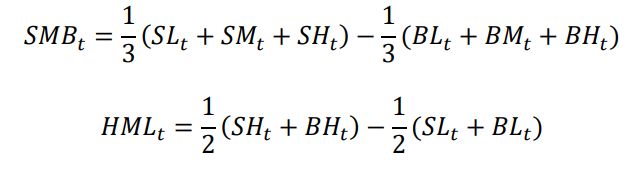
代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 4 19:53:56 2020
@author: 12767
"""
#%%
import pandas as pd
import tushare as ts
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
import datetime
sns.set()
mpl.rcParams['font.sans-serif'] = 'WenQuanYi Micro Hei'
pro = ts.pro_api()
#%%定义计算函数
def cal_smb_hml(df):
# 划分大小市值公司
df['SB'] = df['circ_mv'].map(lambda x: 'B' if x >= df['circ_mv'].median() else 'S')
# 求账面市值比:PB的倒数
df['BM'] = 1 / df['pb']
# 划分高、中、低账面市值比公司
border_down, border_up = df['BM'].quantile([0.3, 0.7])
border_down, border_up
df['HML'] = df['BM'].map(lambda x: 'H' if x >= border_up else 'M')
df['HML'] = df.apply(lambda row: 'L' if row['BM'] <= border_down else row['HML'], axis=1)
# 组合划分为6组
df_SL = df.query('(SB=="S") & (HML=="L")')
df_SM = df.query('(SB=="S") & (HML=="M")')
df_SH = df.query('(SB=="S") & (HML=="H")')
df_BL = df.query('(SB=="B") & (HML=="L")')
df_BM = df.query('(SB=="B") & (HML=="M")')
df_BH = df.query('(SB=="B") & (HML=="H")')
# 计算各组收益率
R_SL = (df_SL['pct_chg'] * df_SL['circ_mv'] / 100).sum() / df_SL['circ_mv'].sum()
R_SM = (df_SM['pct_chg'] * df_SM['circ_mv'] / 100).sum() / df_SM['circ_mv'].sum()
R_SH = (df_SH['pct_chg'] * df_SH['circ_mv'] / 100).sum() / df_SH['circ_mv'].sum()
R_BL = (df_BL['pct_chg'] * df_BL['circ_mv'] / 100).sum() / df_BL['circ_mv'].sum()
R_BM = (df_BM['pct_chg'] * df_BM['circ_mv'] / 100).sum() / df_BM['circ_mv'].sum()
R_BH = (df_BH['pct_chg'] * df_BH['circ_mv'] / 100).sum() / df_BH['circ_mv'].sum()
# 计算SMB, HML并返回
smb = (R_SL + R_SM + R_SH - R_BL - R_BM - R_BH) / 3
hml = (R_SH + R_BH - R_SL - R_BL) / 2
return smb, hml, R_SL, R_SM, R_SH, R_BL, R_BM, R_BH
#%%计算并存储数据
data = []
#获取一段时间内的历史交易日
df_cal = pro.trade_cal(start_date='20190101', end_date='20200801')
df_cal = df_cal.query('(exchange=="SSE") & (is_open==1)')#筛选,清除非交易日
Date=df_cal.cal_date.tolist()
#%%挑选出需要的时间跨度交易日
month_trade_days=[]
i0=0
while i0<len(Date)-1:
# if Date[i0][5]!=Date[i0+1][5]:
month_trade_days.append(Date[i0])
i0+=1
month_trade_days.append(Date[-1])
#%%开始获取数据
i0=292
while i0<len(month_trade_days):
date=month_trade_days[i0]
#获取月线行情
df_daily = pro.daily(trade_date=date)
#获取该日期所有股票的基本面指标
df_basic = pro.daily_basic(trade_date=date)
#数据融合——只保留两个表中公共部分的信息
df = pd.merge(df_daily, df_basic, on='ts_code', how='inner')
smb, hml,sl,sm,sh,bl,bm,bh = cal_smb_hml(df)
data.append([date, smb, hml,sl,sm,sh,bl,bm,bh])
print(date, smb, hml)
i0+=1
#%%保存因子数据
df_tfm = pd.DataFrame(data, columns=['trade_date', 'SMB', 'HML','SL','SM','SH','BL','BM','BH'])
# df_tfm['trade_date'] = pd.to_datetime(df_tfm.trade_date)
# df_tfm = df_tfm.set_index('trade_date')
df_tfm.to_excel('three_factor_model.xlsx')
3、三因子模型回归选股
在计算得到因子模型的数据之后,选取在 2020 年 8 月 8 号可获得的 A 股上市股票,计算其在 2019 年初到 2020 年 7 月的日收益率数据(采用对数收益率计算方法),将日收益率减去无风险收益后得到被解释变量并进行回归。考虑到一些股票的上市时间较短,观测值较少,故将 2019 年后上市的股票剔除出样本范围。同时剔除掉 ST、*ST 股票。
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 6 08:16:05 2020
@author: 12767
"""
import pandas as pd
import tushare as ts
pro = ts.pro_api('')
import statsmodels.api as sm
#回归函数,返回α
def cal_aaa(df_buff):
df_buff['index-rf']=df_buff['index']-df_buff['rf']
df_buff['stock-rf']=df_buff['pct_chg']-df_buff['rf']
model = sm.OLS(df_buff['stock-rf'], sm.add_constant(df_buff[['index-rf','SMB','HML']].values))
result=model.fit()
# print(result.params)
print(result.summary())
return result.params[0]
#%%获取一段时间内的历史交易日
df_cal = pro.trade_cal(start_date='20190101', end_date='20200801')
df_cal = df_cal.query('(exchange=="SSE") & (is_open==1)')#筛选,清除非交易日
Date=df_cal.cal_date.tolist()
#挑选出所需跨度的交易日
month_trade_days=[]
i0=0
while i0<len(Date)-1:
# if Date[i0][5]!=Date[i0+1][5]:
month_trade_days.append(Date[i0])
i0+=1
month_trade_days.append(Date[-1])
#%%提取出无风险利率
rf=pd.read_excel('RF.xlsx')
month_rf=[]
i0=0
while(i0<len(rf['Clsdt'])):
if rf['Clsdt'][i0].replace('-','') in month_trade_days:
month_rf.append(rf['Nrrdaydt'][i0]/100)
i0+=1
#%%
data_buff=pd.DataFrame()
data_buff['trade_date']=month_trade_days
data_buff['rf']=month_rf
#获取指数收益率信息
index=pro.index_daily(ts_code='000002.SH',start_date='20190101',end_date='20200731')
index=index.drop(['close','open','high','ts_code','low','change','pre_close','vol','amount'],axis=1)
index=index.rename(columns={'pct_chg':'index'})
index['index']=index['index']/100
data_buff=pd.merge(data_buff,index,on='trade_date',how='inner')
#提取另外两个因子序列
two_factor=pd.read_excel('three_factor_model.xlsx')
data_buff['SMB']=two_factor['SMB']
data_buff['HML']=two_factor['HML']
#%%遍历所有股票,计算每只股票的α
# 获取所有股票的信息
stock_information = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
aerfa_list=[]
#%%输出挑选出来的股票的详细回归信息
aerfa_list=[]
stock_list=['300156.SZ',
'300090.SZ',
'600175.SH',
'002220.SZ',
'002370.SZ',
'300677.SZ',
'600685.SH',
'600095.SH',
'603069.SH',
'601066.SH']
i0=0
while(i0<len(stock_list)):
stock=stock_list[i0]
df=pro.daily(ts_code=stock,start_date='20190101',end_date='20200731')
df_buff = pd.merge(data_buff, df, on='trade_date', how='inner')
df_buff=df_buff.drop(['close','open','high','low','pre_close','change','vol','amount'],axis=1)
if len(df_buff['rf'])==0:
aerfa_list.append(99)
else:
aerfa_list.append(cal_aaa(df_buff))
print(stock)
i0+=1
#%%********此处循环3000只股票
i0=0
while(i0<len(stock_information['ts_code'])):
stock=stock_information['ts_code'][i0]
df=pro.daily(ts_code=stock,start_date='20190101',end_date='20200731')
df_buff = pd.merge(data_buff, df, on='trade_date', how='inner')
df_buff=df_buff.drop(['close','open','high','low','pre_close','change','vol','amount'],axis=1)
if len(df_buff['rf'])==0:
aerfa_list.append(99)
else:
aerfa_list.append(cal_aaa(df_buff))
print(stock)
i0+=1
#%%保存数据
stock_information['aerfa']=aerfa_list
stock_information.to_excel('stock_information.xlsx')
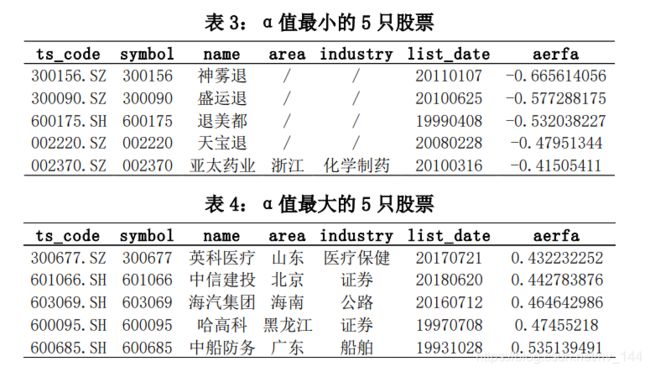
总结
以上只是记录一部分作业内容,不得不说tushare社区真的很香