Dropout,Batch Normalization,Maxout
Dropout浅层理解与实现:
原文地址:http://blog.csdn.net/hjimce/article/details/50413257
作者:hjimce
1.算法概述
我们知道如果要训练一个大型的网络,训练数据很少的话,那么很容易引起过拟合(也就是在测试集上的精度很低),可能我们会想到用L2正则化、或者减小网络规模。然而深度学习领域大神Hinton,在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。
Hinton认为过拟合,可以通过阻止某些特征的协同作用来缓解。在每次训练的时候,每个神经元有百分之50的几率被移除,这样可以让一个神经元的出现不应该依赖于另外一个神经元。
另外,我们可以把dropout理解为 模型平均。 假设我们要实现一个图片分类任务,我们设计出了100000个网络,这100000个网络,我们可以设计得各不相同,然后我们对这100000个网络进行训练,训练完后我们采用平均的方法,进行预测,这样肯定可以提高网络的泛化能力,或者说可以防止过拟合,因为这100000个网络,它们各不相同,可以提高网络的稳定性。而所谓的dropout我们可以这么理解,这n个网络,它们权值共享,并且具有相同的网络层数(这样可以大大减小计算量)。我们每次dropout后,网络模型都可以看成是整个网络的子网络。(需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响)。
啰嗦了这么多,那么到底是怎么实现的?Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作,示意图如下:
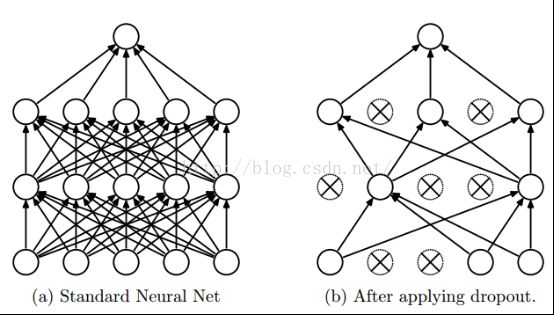
左边是原来的神经网络,右边是采用Dropout后的网络。这个说是这么说,但是具体代码层面是怎么实现的?怎么让某个神经元以一定的概率停止工作?这个我想很多人还不是很了解,代码层面的实现方法,下面就讲解一下其代码层面的实现。以前我们网络的计算公式是:

采用dropout后计算公式就变成了:

上面公式中Bernoulli函数,是为了以概率p,随机生成一个0、1的向量。
2.算法实现概述:
1、其实Dropout很容易实现,源码只需要几句话就可以搞定了,让某个神经元以概率p,停止工作,其实就是让它的激活值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活值为x1,x2……x1000,我们dropout比率选择0.4,那么这一层神经元经过drop后,x1……x1000神经元其中会有大约400个的值被置为0。
2、经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量x1……x1000进行rescale,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对x1……x1000进行rescale,那么你在测试的时候,就需要对权重进行rescale:

问题来了,上面为什么经过dropout需要进行rescale?查找了相关的文献,都没找到比较合理的解释,后面再结合源码说一下我对这个的见解。
所以在测试阶段:如果你既不想在训练的时候,对x进行放大,也不愿意在测试的时候,对权重进行缩小(乘以概率p)。那么你可以测试n次,这n次都采用了dropout,然后对预测结果取平均值,这样当n趋近于无穷大的时候,就是我们需要的结果了(也就是说你可以采用train阶段一模一样的代码,包含了dropout在里面,然后前向传导很多次,比如1000000次,然后对着1000000个结果取平均值)。
3.源码实现
下面我引用keras的dropout实现源码进行讲解,keras开源项目github地址为:
https://github.com/fchollet/keras/tree/master/keras。其dropout所在的文件为:
https://github.com/fchollet/keras/blob/master/keras/backend/theano_backend.py,dropout实现函数如下:
#dropout函数的实现
def dropout(x, level):
if level < 0. or level >= 1:#level是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
#我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
#硬币 正面的概率为p,n表示每个神经元试验的次数
#因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
sample=np.random.binomial(n=1,p=retain_prob,size=x.shape)#即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print sample
x *=sample#0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0
print x
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
函数中,x是本层网络的激活值。Level就是dropout就是每个神经元要被丢弃的概率。不过对于dropout后,为什么需要进行rescale:
x /= retain_prob有的人解释有点像归一化一样,就是保证网络的每一层在训练阶段和测试阶段数据分布相同。我查找了很多文献,都没找到比较合理的解释,除了在文献《Regularization of Neural Networks using DropConnect》稍微解释了一下,其它好像都没看到相关的理论解释。
我们前面说过,其实Dropout是类似于平均网络模型。我们可以这么理解,我们在训练阶段训练了1000个网络,每个网络生成的概率为Pi,然后我们在测试阶段的时候,我们肯定要把这1000个网络的输出结果都计算一遍,然后用这1000个输出,乘以各自网络的概率Pi,求得的期望值就是我们最后的平均结果。我们假设,网络模型的输出如下:

M是Dropout中所有的mask集合。所以当我们在测试阶段的时候,我们就是对M中所有的元素网络,最后所得到的输出,做一个期望:

P(M)表示网络各个子网络出现的概率。因为dropout过程中,所有的子网络出现的概率都是相同的,所以。
个人总结:个人感觉除非是大型网络,才采用dropout,不然我感觉自己在一些小型网络上,训练好像很是不爽。之前搞一个比较小的网络,搞人脸特征点定位的时候,因为训练数据不够,怕过拟合,于是就采用dropout,最后感觉好像训练速度好慢,从此就对dropout有了偏见,感觉训练过程一直在波动,很是不爽。
参考文献:
1、《Improving neural networks by preventing co-adaptation of feature detectors》
2、《Improving Neural Networks with Dropout》
3、《Dropout: A Simple Way to Prevent Neural Networks from Overtting》
4、《ImageNet Classification with Deep Convolutional》
**********************作者:hjimce 时间:2015.12.20 联系QQ:1393852684 原创文章,转载请保留原文地址、作者等信息***************
Batch Normalization 学习笔记
原文地址:http://blog.csdn.net/hjimce/article/details/50866313
作者:hjimce
一、背景意义
近年来深度学习捷报连连、声名鹊起,随机梯度下架成了训练深度网络的主流方法。尽管随机梯度下降法对于训练深度网络简单高效,但是它有个毛病,就是需要我们人为的去选择参数,比如学习率、参数初始化、权重衰减系数、Drop out比例等。这些参数的选择对训练结果至关重要,以至于我们很多时间都浪费在这些的调参上。那么学完这篇文献之后,你可以不需要那么刻意的慢慢调整参数。BN算法(Batch Normalization)其强大之处如下:
(1)你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
(2)你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(3)再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
(4)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度,这句话我也是百思不得其解啊)。
开始讲解算法前,先来思考一个问题:我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。Paper所提出的算法,就是要解决在训练过程中,中间层数据分布发生改变的情况,于是就有了Batch Normalization,这个牛逼算法的诞生。
二、初识BN(Batch Normalization)
1、BN概述
就像激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。在前面我们提到网络除了输出层外,其它层因为低层网络在训练的时候更新了参数,而引起后面层输入数据分布的变化。这个时候我们可能就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊,比如网络第三层输入数据X3(X3表示网络第三层的输入数据)把它归一化至:均值0、方差为1,然后再输入第三层计算,这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了。
而事实上,paper的算法本质原理就是这样:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。不过文献归一化层,可不像我们想象的那么简单,它是一个可学习、有参数的网络层。既然说到数据预处理,下面就先来复习一下最强的预处理方法:白化。
2、预处理操作选择
说到神经网络输入数据预处理,最好的算法莫过于白化预处理。然而白化计算量太大了,很不划算,还有就是白化不是处处可微的,所以在深度学习中,其实很少用到白化。经过白化预处理后,数据满足条件:a、特征之间的相关性降低,这个就相当于pca;b、数据均值、标准差归一化,也就是使得每一维特征均值为0,标准差为1。如果数据特征维数比较大,要进行PCA,也就是实现白化的第1个要求,是需要计算特征向量,计算量非常大,于是为了简化计算,作者忽略了第1个要求,仅仅使用了下面的公式进行预处理,也就是近似白化预处理:
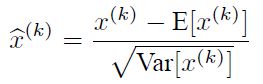
公式简单粗糙,但是依旧很牛逼。因此后面我们也将用这个公式,对某一个层网络的输入数据做一个归一化处理。需要注意的是,我们训练过程中采用batch 随机梯度下降,上面的E(xk)指的是每一批训练数据神经元xk的平均值;然后分母就是每一批数据神经元xk激活度的一个标准差了。
三、BN算法实现
1、BN算法概述
经过前面简单介绍,这个时候可能我们会想当然的以为:好像很简单的样子,不就是在网络中间层数据做一个归一化处理嘛,这么简单的想法,为什么之前没人用呢?然而其实实现起来并不是那么简单的。其实如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
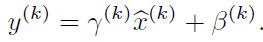
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
 、
、
是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。最后Batch Normalization网络层的前向传导过程公式就是:
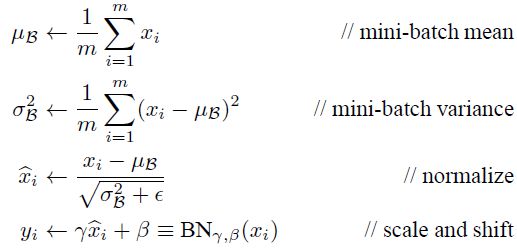
上面的公式中m指的是mini-batch size。
2、源码实现
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
上面的x是一个二维矩阵,对于源码的实现就几行代码而已,轻轻松松。
3、实战使用
(1)可能学完了上面的算法,你只是知道它的一个训练过程,一个网络一旦训练完了,就没有了min-batch这个概念了。测试阶段我们一般只输入一个测试样本,看看结果而已。因此测试样本,前向传导的时候,上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ 计算公式如下:

上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:

(2)根据文献说,BN可以应用于一个神经网络的任何神经元上。文献主要是把BN变换,置于网络激活函数层的前面。在没有采用BN的时候,激活函数层是这样的:
z=g(Wu+b)
也就是我们希望一个激活函数,比如s型函数s(x)的自变量x是经过BN处理后的结果。因此前向传导的计算公式就应该是:
z=g(BN(Wu+b))
其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后把BN层+激活函数层就变成了:
z=g(BN(Wu))
四、Batch Normalization在CNN中的使用
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。下面是来自于keras卷积层的BN实现一小段主要源码:
input_shape = self.input_shape
reduction_axes = list(range(len(input_shape)))
del reduction_axes[self.axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[self.axis] = input_shape[self.axis]
if train:
m = K.mean(X, axis=reduction_axes)
brodcast_m = K.reshape(m, broadcast_shape)
std = K.mean(K.square(X - brodcast_m) + self.epsilon, axis=reduction_axes)
std = K.sqrt(std)
brodcast_std = K.reshape(std, broadcast_shape)
mean_update = self.momentum * self.running_mean + (1-self.momentum) * m
std_update = self.momentum * self.running_std + (1-self.momentum) * std
self.updates = [(self.running_mean, mean_update),
(self.running_std, std_update)]
X_normed = (X - brodcast_m) / (brodcast_std + self.epsilon)
else:
brodcast_m = K.reshape(self.running_mean, broadcast_shape)
brodcast_std = K.reshape(self.running_std, broadcast_shape)
X_normed = ((X - brodcast_m) /
(brodcast_std + self.epsilon))
out = K.reshape(self.gamma, broadcast_shape) * X_normed + K.reshape(self.beta, broadcast_shape)
个人总结:2015年个人最喜欢深度学习的一篇paper就是Batch Normalization这篇文献,采用这个方法网络的训练速度快到惊人啊,感觉训练速度是以前的十倍以上,再也不用担心自己这破电脑每次运行一下,训练一下都要跑个两三天的时间。另外这篇文献跟空间变换网络《Spatial Transformer Networks》的思想神似啊,都是一个变换网络层。
参考文献:
1、《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
2、《Spatial Transformer Networks》
3、https://github.com/fchollet/keras
**********************作者:hjimce 时间:2016.3.12 联系QQ:1393852684 原创文章,转载请保留作者、原文地址信息********************
Maxout网络学习
原文地址:http://blog.csdn.net/hjimce/article/details/50414467
作者:hjimce
一、相关理论
本篇博文主要讲解2013年,ICML上的一篇文献:《Maxout Networks》,这个算法我目前也很少用到,个人感觉最主要的原因应该是这个算法参数个数会成k倍增加(k是maxout的一个参数),不过没关系,对于我们来说知识积累才是最重要的,指不定某一天我们就需要用到这个算法,技多不压身。个人感觉Maxout网络和Dropout有很多相似的地方。
本篇博文将从什么是maxout网络讲起,先解答maxout的源码层实现,因为很多人最感兴趣的还是算法要怎么实现,当然我也是这样的。我看文献,一般最在意的还是源码的实现,有的文献理论公式推导了十几页,结果5行代码搞定,我看到想哭,这也许就是我讨厌做学术研究的原因吧。知道了源码怎么实现后,我们简单啰嗦一下maxout相关的理论意义。
二、Maxout算法流程
1、算法概述
开始前我们先讲解什么叫maxout networks,等我们明白了什么叫maxout 网络后,再对maxout的相理论意义做出解释。Maxout是深度学习网络中的一层网络,就像池化层、卷积层一样等,我们可以把maxout 看成是网络的激活函数层,这个后面再讲解,本部分我们要先知道什么是maxout。我们假设网络某一层的输入特征向量为:X=(x1,x2,……xd),也就是我们输入是d个神经元。Maxout隐藏层每个神经元的计算公式如下:

上面的公式就是maxout隐藏层神经元i的计算公式。其中,k就是maxout层所需要的参数了,由我们人为设定大小。就像dropout一样,也有自己的参数p(每个神经元dropout概率),maxout的参数是k。公式中Z的计算公式为:

权重w是一个大小为(d,m,k)三维矩阵,b是一个大小为(m,k)的二维矩阵,这两个就是我们需要学习的参数。如果我们设定参数k=1,那么这个时候,网络就类似于以前我们所学普通的MLP网络。
我们可以这么理解,本来传统的MLP算法在第i层到第i+1层,参数只有一组,然而现在我们不怎么干了,我们在这一层同时训练n组参数,然后选择激活值最大的作为下一层神经元的激活值。下面还是用一个例子进行讲解,比较容易搞懂。
为了简单起见,假设我们网络第i层有2个神经元x1、x2,第i+1层的神经元个数为1个,如下图所示:

(1)以前MLP的方法。我们要计算第i+1层,那个神经元的激活值的时候,传统的MLP计算公式就是:
z=W*X+b
out=f(z)
其中f就是我们所谓的激活函数,比如Sigmod、Relu、Tanh等。
(2)Maxout 的方法。如果我们设置maxout的参数k=5,maxout层就如下所示:
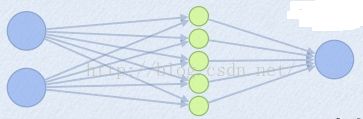
相当于在每个输出神经元前面又多了一层。这一层有5个神经元,此时maxout网络的输出计算公式为:
z1=w1*x+b1
z2=w2*x+b2
z3=w3*x+b3
z4=w4*x+b4
z5=w5*x+b5
out=max(z1,z2,z3,z4,z5)
所以这就是为什么采用maxout的时候,参数个数成k倍增加的原因。本来我们只需要一组参数就够了,采用maxout后,就需要有k组参数。
三、源码实现
ok,为了学习maxout源码的实现过程,我这边引用keras的源码maxout的实现,进行讲解。keras的网站为:http://keras.io/ 。项目源码网站为:https://github.com/fchollet/keras。下面是keras关于maxout网络层的实现函数:
#maxout 网络层类的定义
class MaxoutDense(Layer):
# 网络输入数据矩阵大小为(nb_samples, input_dim)
# 网络输出数据矩阵大小为(nb_samples, output_dim)
input_ndim = 2
#nb_feature就是我们前面说的k的个数了,这个是maxout层特有的参数
def __init__(self, output_dim, nb_feature=4,
init='glorot_uniform', weights=None,
W_regularizer=None, b_regularizer=None, activity_regularizer=None,
W_constraint=None, b_constraint=None, input_dim=None, **kwargs):
self.output_dim = output_dim
self.nb_feature = nb_feature
self.init = initializations.get(init)
self.W_regularizer = regularizers.get(W_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.b_constraint = constraints.get(b_constraint)
self.constraints = [self.W_constraint, self.b_constraint]
self.initial_weights = weights
self.input_dim = input_dim
if self.input_dim:
kwargs['input_shape'] = (self.input_dim,)
self.input = K.placeholder(ndim=2)
super(MaxoutDense, self).__init__(**kwargs)
#参数初始化部分
def build(self):
input_dim = self.input_shape[1]
self.W = self.init((self.nb_feature, input_dim, self.output_dim))#nb_feature是我们上面说的k。
self.b = K.zeros((self.nb_feature, self.output_dim))
self.params = [self.W, self.b]
self.regularizers = []
if self.W_regularizer:
self.W_regularizer.set_param(self.W)
self.regularizers.append(self.W_regularizer)
if self.b_regularizer:
self.b_regularizer.set_param(self.b)
self.regularizers.append(self.b_regularizer)
if self.activity_regularizer:
self.activity_regularizer.set_layer(self)
self.regularizers.append(self.activity_regularizer)
if self.initial_weights is not None:
self.set_weights(self.initial_weights)
del self.initial_weights
def get_output(self, train=False):
X = self.get_input(train)#需要切记这个x的大小是(nsamples,input_num)
# -- don't need activation since it's just linear.
output = K.max(K.dot(X, self.W) + self.b, axis=1)#maxout激活函数
return output看上面的代码的话,其实只需要看get_output()函数,就知道maxout的实现了。所以说有的时候,一篇文献的代码,其实就只有几行代码,maxout就仅仅只有一行代码而已:
output = K.max(K.dot(X, self.W) + self.b, axis=1)#maxout激活函数
下面在简单啰嗦一下相关的理论,毕竟文献的作者写了那么多页,我们总得看一看才行。Maxout可以看成是一个激活函数 ,然而它与原来我们以前所学的激活函数又有所不同。传统的激活函数:

比如阈值函数、S函数等。maxout激活函数,它具有如下性质:
1、maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等函数,是一个固定的函数方程
2、它是一个可学习的激活函数,因为我们W参数是学习变化的。
3、它是一个分段线性函数:

然而任何一个凸函数,都可以由线性分段函数进行逼近近似。其实我们可以把以前所学到的激活函数:relu、abs激活函数,看成是分成两段的线性函数,如下示意图所示:

maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。最直观的解释就是任意的凸函数都可以由分段线性函数以任意精度拟合(学过高等数学应该能明白),而maxout又是取k个隐隐含层节点的最大值,这些”隐隐含层"节点也是线性的,所以在不同的取值范围下,最大值也可以看做是分段线性的(分段的个数与k值有关)-本段摘自:http://www.cnblogs.com/tornadomeet/p/3428843.html
maxout是一个函数逼近器,对于一个标准的MLP网络来说,如果隐藏层的神经元足够多,那么理论上我们是可以逼近任意的函数的。类似的,对于maxout 网络也是一个函数逼近器。
定理1:对于任意的一个连续分段线性函数g(v),我们可以找到两个凸的分段线性函数h1(v)、h2(v),使得这两个凸函数的差值为g(v):
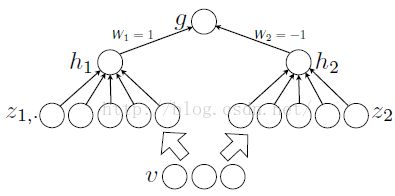

参考文献:
1、《Maxout Networks》
2、http://www.cnblogs.com/tornadomeet/p/3428843.html
**********************作者:hjimce 时间:2015.12.20 联系QQ:1393852684 原创文章,转载请保留原文地址、作者等信息**********