datawhale深度推荐模型组队学习Task05-DIN模型
序言:
不同于之前几个模型各种拼接的画风,阿里巴巴提出的DIN模型着眼于电商广告推荐的具体场景,具有浓厚的商业气息。
在电商广告推荐场景中,如何捕捉用户的兴趣,根据用户兴趣推荐相关的商品是一个关键问题。用户的兴趣往往可以通过他历史购买过的商品来获得,因此,如何利用用户历史购买的商品来考察当前候选商品用户是否会感兴趣,就是DIN模型所要解决的问题。
1 模型原理
DIN模型的构造思路就是以常规的MLP模型作为基准模型,在其上引入注意力机制,考察当前候选商品与每个用户历史购买的商品之间的关联性,如果关联性强,则说明候选商品与用户购买过的商品很相似,用户有更大的可能会点击该商品。
注意力机制的具体做法是:对于用户购买过的某个商品,将该商品的embedding向量与候选商品的embedding向量一同作为输入,通过一个多层的学习网络,得到一个分数,这个分数就用来衡量两者之间的关联性。对于用户购买过的所有商品,我们都可以学习到一个分数,把这些分数作为每个历史购买商品embedding向量的权重,模型就会更加关注分数高的,即与候选商品关联性更强的历史商品,从而捕捉到用户的兴趣。

1.1 模型的输入特征
作者将输入特征分为四类:
- User Profile Features:用户信息特征,包含与用户个人有关的特征。
- User Behaviors:用户历史行为特征,即用户历史购买的商品信息序列,每个商品的信息包括商品ID、店铺ID和商品类别ID。
- Candidate Ad:候选商品特征,由候选商品的商品ID、店铺ID和商品类别ID组成。
- Context Features:语境特征,指推荐行为所处的环境信息,例如推荐时间、推荐平台等。
这些特征仍然采用Embedding进行处理,将类别特征经过one-hot编码后映射称为固定长度的向量。但需要注意的是,每个用户历史购买的商品数量都是不同的,这就导致用户历史行为序列长度不统一。这里需要采用multi-hot对用户历史行为序列进行编码,即令序列为长度是商品个数的向量,将用户历史购买过的商品对应位置置为1。于是输入特征的形式就如下图所示:
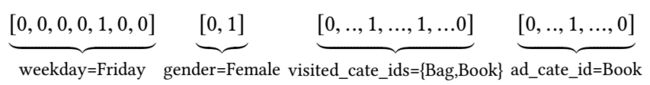
1.2 基准模型
除开注意力机制,可以看到DIN的基准模型是一个常规的Embedding+MLP模型。对用户历史行为序列经过Embedding后进行求和池化,然后与其他经过Embedding处理后的特征拼接,展平后输入MLP网络中进行学习。

1.3 注意力机制
DIN模型的注意力机制是由一个激活单元实现的。激活单元有两个输入,一个是用户历史行为序列中的某一个商品Embedding,另一个是候选商品的Embedding,将这两者与它们之间的外积进行拼接,然后输入到一个多层网络中,学习到该历史商品所对应的一个权重。

于是,将所得到的权重与历史商品Embedding相乘,就得到了用户U对于候选商品A的兴趣表达式:
v U ( A ) = f ( v A , e 1 , e 2 , . . . , e H ) = ∑ j = 1 H a ( e j , v A ) e j = ∑ j = 1 H w j e j v_U(A)=f(v_A,e_1,e_2,...,e_H)=\sum_{j=1}^Ha(e_j,v_A)e_j=\sum_{j=1}^Hw_je_j vU(A)=f(vA,e1,e2,...,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
其中, { e 1 , e 2 , . . . , e H } \{e_1,e_2,...,e_H\} {e1,e2,...,eH}为用户的历史行为Embedding序列, a ( e j , v A ) a(e_j,v_A) a(ej,vA)为第j个历史商品对应的权重。
1.4 激活函数
仔细观察的话,会发现模型使用的激活函数并不是常用的ReLU,而是PReLU或Dice。

PReLU的表达式如下。从函数曲线上可以看到,PReLU以0作为硬矫正点,函数不连续,这对于每一层的输入分布不同的情况可能并不合适。
f ( s ) = { s , s > 0 α s , s < = 0 = p ( s ) s + ( 1 − p ( s ) ) α s f(s)=\left\{ \begin{aligned} &s, s>0 \\ &\alpha s, s<=0 \end{aligned}=p(s)s+(1-p(s))\alpha s \right. f(s)={s,s>0αs,s<=0=p(s)s+(1−p(s))αs
于是,作者设计了一个新的自适应激活函数Dice,表达式如下,其中E(s)和Var(s)分别为数据的期望和方差。Dice的函数曲线是连续平滑的,并且可以根据数据的期望和方差自行调整,适应不同的数据分布。
f ( s ) = p ( s ) s + ( 1 − p ( s ) ) α s , p ( s ) = 1 1 + e − s − E [ s ] V a r [ s ] + ϵ f(s)=p(s)s+(1-p(s))\alpha s, p(s)=\frac{1}{1+e^{-\frac{s-E[s]}{\sqrt{Var[s]+\epsilon}}}} f(s)=p(s)s+(1−p(s))αs,p(s)=1+e−Var[s]+ϵs−E[s]1
2 模型构建
2.1 构建数据集
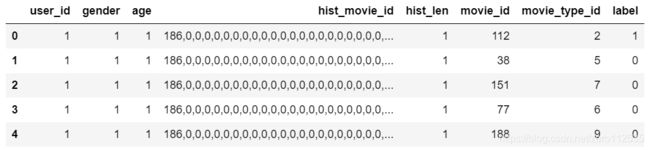
采用movie的部分数据,数据集包括7个特征,部分数据如下图所示,其中hist_movie_id是用户历史看过的电影ID,hist_len是用户历史看过的电影数量,目标是预测CTR。
构建训练数据集:
X = data.drop('label', axis=1)
y = data['label']
# 考虑到模型输入格式,以字典形式保存训练数据
X_train = {"user_id": np.array(X["user_id"]), \
"gender": np.array(X["gender"]), \
"age": np.array(X["age"]), \
"hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["hist_movie_id"]]), \
"hist_len": np.array(X["hist_len"]), \
"movie_id": np.array(X["movie_id"]), \
"movie_type_id": np.array(X["movie_type_id"])}
y_train = np.array(y)
from collections import namedtuple
# 使用具名元组定义特征标记
# 类别型特征需要记录特征名称、类别数、Embedding的输出维度
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
# 数值型特征需要记录特征名称、输入维度
DenseFeat = namedtuple('DenseFeat', ['name', 'dimension'])
# 变长度类别型特征需要记录特征名称、类别数、Embedding的输出维度、最大长度
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'vocabulary_size', 'embedding_dim', 'maxlen'])
# 标记输入特征
feature_columns = [SparseFeat('user_id', max(data["user_id"])+1, embedding_dim=8),
SparseFeat('gender', max(data["gender"])+1, embedding_dim=8),
SparseFeat('age', max(data["age"])+1, embedding_dim=8),
SparseFeat('movie_id', max(data["movie_id"])+1, embedding_dim=8),
SparseFeat('movie_type_id', max(data["movie_type_id"])+1, embedding_dim=8),
DenseFeat('hist_len', 1)]
feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(data["movie_id"])+1, embedding_dim=8, maxlen=50)]
# 行为特征列表,表示的是基础特征,在这里就是当前候选电影的ID
behavior_feature_list = ['movie_id']
# 用户历史行为序列特征
behavior_seq_feature_list = ['hist_movie_id']
这里VarLenSparseFeat用于标记变长度的类别型特征,即指用户历史行为特征,因为不同用户的历史行为数量是不等的,所以特征的输入长度不统一,一般通过填充或截断操作保证输入长度固定,代码中的maxlen就是所设置的固定输入长度。
2.2 构建DIN模型
2.2.1 构建模型的输入
对输入的所有特征各构建一个Input层,并且返回输入层字典:
def build_input_layers(feature_columns):
input_layer_dict = {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
input_layer_dict[fc.name] = Input(shape=(1,), name=fc.name)
elif isinstance(fc, DenseFeat):
input_layer_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
elif isinstance(fc, VarLenSparseFeat):
input_layer_dict[fc.name] = Input(shape=(fc.maxlen, ), name=fc.name)
return input_layer_dict
2.2.2 构建Embedding层
对特征中的每一个类别型特征和变长度类别型特征构建一个Embedding层,并且返回Embedding层字典:
# 构建embedding层
def build_embedding_layers(feature_columns, input_layer_dict):
embedding_layer_dict = {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='emb_' + fc.name)
elif isinstance(fc, VarLenSparseFeat):
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='emb_' + fc.name, mask_zero=True)
return embedding_layer_dict
为了方便后续构建模型,我们定义一个函数,用于对输入的特征进行Embedding操作,然后返回Embedding列表。
def embedding_lookup(feature_columns, input_layer_dict, embedding_layer_dict):
embedding_list = []
for fc in feature_columns:
_input = input_layer_dict[fc]
_embed = embedding_layer_dict[fc]
embed = _embed(_input)
embedding_list.append(embed)
return embedding_list
2.2.3 构建Dice激活函数
根据第1节中给出的公式构建Dice激活函数:
# 构建激活函数Dice
class Dice(Layer):
def __init__(self):
super(Dice, self).__init__()
self.bn = BatchNormalization(center=False, scale=False)
def build(self, input_shape):
self.alpha = self.add_weight(shape=(input_shape[-1],), dtype=tf.float32, name='alpha')
def call(self, x):
x_normed = self.bn(x)
x_p = tf.sigmoid(x_normed)
return self.alpha * (1.0-x_p) * x + x_p * x
2.2.4 构建注意力机制
我们首先构建一个激活单元,能够对每个历史行为序列中的物品学习一个权重。
# 构造激活单元
class LocalActivationUnit(Layer):
def __init__(self, hidden_units=(256, 128, 64), activation='prelu'):
super(LocalActivationUnit, self).__init__()
self.hidden_units = hidden_units
self.linear = Dense(1)
self.dnn = [Dense(unit, activation=PReLU() if activation=='prelu' else Dice()) for unit in self.hidden_units]
def call(self, inputs):
# query为当前候选电影的Embedding,keys为用户历史行为的Embedding序列
query, keys = inputs
# 获取序列长度
keys_len = keys.get_shape()[1]
# 将query扩展成keys_len个
queries = tf.tile(query, multiples=[1, keys_len, 1])
# 将queries,keys和二和外积拼接起来作为多层网络的输入
att_input = tf.concat([queries, keys, queries - keys, queries * keys], axis=-1)
# 输入多层网络进行学习
att_out = att_input
for fc in self.dnn:
att_out = fc(att_out)
# 获得网络输出,并调整输出维度
att_out = self.linear(att_out) # B x len x 1
att_out = tf.squeeze(att_out, -1) # B x len
return att_out
然后利用该激活单元构建注意力池化层,注意这里只将Embedding不为0的地方乘上了权重,为0的节点不参与模型学习。
class AttentionPooling(Layer):
def __init__(self, att_hidden_units=(128, 64)):
super(AttentionPooling, self).__init__()
self.att_hidden_units = att_hidden_units
self.local_att = LocalActivationUnit(self.att_hidden_units, 'dice')
def call(self, inputs):
# query为当前候选电影的Embedding,keys为用户历史行为的Embedding序列
query, keys = inputs
# 用key_masks保存keys中不为0的地方为True,其余为False
key_masks = tf.not_equal(keys[:, :, 0], 0)
# 获取行为序列中每个商品的注意力权重
attention_score = self.local_att([query, keys])
outputs = attention_score
# 构造一个与权重维度相同的全零矩阵
paddings = tf.zeros_like(attention_score)
# 若key_masks为True,则返回该处的attention_score,否则返回该处的paddings,即为0
outputs = tf.where(key_masks, attention_score, paddings)
# 重新调整输出权重的维度
outputs = tf.expand_dims(outputs, axis=1) # B x 1 x len
# 将输出权重与历史行为序列相乘
# keys : B x len x emb_dim
outputs = tf.matmul(outputs, keys) # B x 1 x emb_dim
# 重新调整输出维度
outputs = tf.squeeze(outputs, axis=1) # B x emb_dim
return outputs
2.2.5 构建DNN模型
构建一个简单的两层DNN网络,这里网络结构可以自行设置。
def get_dnn_logits(dnn_input, hidden_units=(200, 80), activation='prelu'):
dnns = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
dnn_out = dnn_input
for dnn in dnns:
dnn_out = dnn(dnn_out)
# 获取logits
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logits
2.2.6 构建DIN模型
为了便于构建模型,我们先定义两个函数。
- 定义用于进行Embedding操作的函数,返回Embedding列表
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
embedding_list = []
for fc in feature_columns:
_input = input_layer_dict[fc.name] # 获取输入层
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
embed = _embed(_input) # B x dim 将input层输入到embedding层中
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list
- 定义用于拼接Embedding列表的函数
def concat_input_list(input_list):
feature_nums = len(input_list)
if feature_nums > 1:
return Concatenate(axis=1)(input_list)
elif feature_nums == 1:
return input_list[0]
else:
return None
然后将以上步骤串连起来,构建DIN模型:
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
# 构建模型输入层
input_layer_dict = build_input_layers(feature_columns)
# 将输入层转化为列表形式
input_layers = list(input_layer_dict.values())
# 筛选出Sparse特征
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
# 筛选出Dense特征
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))
# 构建Dense特征的输入层
dnn_dense_input = []
for fc in dense_feature_columns:
dnn_dense_input.append(input_layer_dict[fc.name])
# 将Dense特征拼接起来
dnn_dense_input = concat_input_list(dnn_dense_input)
# 构建embedding层
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
# 构建输入DNN的Sparse特征的Embedding列表
dnn_sparse_emb_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
# 拼接Embedding列表
dnn_sparse_input = concat_input_list(dnn_sparse_emb_input)
# 获取当前电影id的Embedding
query_emb_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
# 获取用户行为特征的embedding
keys_emb_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
# 使用注意力机制
dnn_seq_input_list = []
for i in range(len(keys_emb_list)):
seq_emb = AttentionPooling()([query_emb_list[i], keys_emb_list[i]])
dnn_seq_input_list.append(seq_emb)
# 将使用了注意力机制的行为序列列表拼接起来
dnn_seq_input = concat_input_list(dnn_seq_input_list)
# 将处理过的所有特征拼接起来作为DNN的输入
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
# 获得DNN的输出
dnn_logits = get_dnn_logits(dnn_input, activation='dice')
model = Model(input_layers, dnn_logits)
return model
2.2.7 模型训练
# 构建模型
model = DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list)
# 查看模型结构
model.summary()
# 设置优化器
learning_rate = 1e-4
adam = tf.optimizers.Adam(lr=learning_rate)
# 模型编译
model.compile(optimizer=adam,
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 模型训练
history = model.fit(X_train, y_train, batch_size=128, epochs=5, validation_split=0.2)
2.2.8 绘制训练验证曲线
# define the function
def training_vis(hist):
loss = hist.history['loss']
val_loss = hist.history['val_loss']
auc = hist.history['auc']
val_auc = hist.history['val_auc']
bce = hist.history['binary_crossentropy']
val_bce = hist.history['val_binary_crossentropy']
# make a figure
fig = plt.figure(figsize=(12,4))
# subplot loss
ax1 = fig.add_subplot(131)
ax1.plot(loss,label='train_loss')
ax1.plot(val_loss,label='val_loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.set_title('Loss on Training and Validation Data')
ax1.legend()
# subplot auc
ax2 = fig.add_subplot(132)
ax2.plot(auc,label='train_auc')
ax2.plot(val_auc,label='val_auc')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('AUC')
ax2.set_title('AUC on Training and Validation Data')
ax2.legend()
plt.tight_layout()
# subplot binary_crossentropy
ax3 = fig.add_subplot(133)
ax3.plot(bce,label='train_binary_crossentropy')
ax3.plot(val_bce,label='val_binary_crossentropy')
ax3.set_xlabel('Epochs')
ax3.set_ylabel('Binary Crossentropy')
ax3.set_title('Binary Crossentropy on Training and Validation Data')
ax3.legend()
plt.tight_layout()
训练验证曲线如下图所示:

3 思考
引入Attention机制对用户的兴趣进行挖掘是一个很好的思路,但是DIN模型在实际应用中也存在一些问题:
- 用户历史行为序列在实际应用中应该考虑取多长时间内的历史行为?用户历史行为序列可能会过长,如何处理?
- 用户的兴趣是会随时间变化的,早期的历史行为对当前的候选商品影响会下降,如何捕捉用户的兴趣变化,使模型更多地关注近期的历史行为?
目前,有一些模型在这些方面做出了改进:
- DSIN模型根据一定的规则将用户历史行为序列划分为了多个session,利用Transformer对每个session进行学习得到兴趣向量,再通过Bi-LSTM来捕捉用户在不同session的兴趣变化。
- DIEN模型采用GRU来提取用户兴趣特征,然后利用Attention+GRU来学习用户兴趣随时间的变化。