U-Net及其变体(不定时更新)
文章目录
- 前言
- 一、U-Net
- 二、U-Net的变体
-
- 待更新
- 总结
前言
U-net是一种主要为图像分割任务开发的图像分割技术,在医学图像分割领域有很高的实用性。
为希望探索U-net的研究人员提供一个起点。基于U-net的架构在医学图像分析中是有相当潜力和价值的。自2017年依赖U-net论文的增长证明了其作为医学影像深度学习技术的地位。预计U-net将是主要的前进道路之一。
忘了在哪听到的了,医学图像分割主要是解决位置和物体尺寸大小变化,扩展路径输出的图像有一定位置信息,加上收缩路径的输出对位置进行了更加详细的刻画;同时由于有池化类似于金字塔尺寸问题得到了一定程度解决,所以U-net效果才会这么好。
目前主要参考下面这个综述文章,并结合其中参考文献进行整理。不定时更新,处于小白阶段,有错误感谢指正,共同进步。
综述文章:https://ieeexplore.ieee.org/document/9446143
一、U-Net
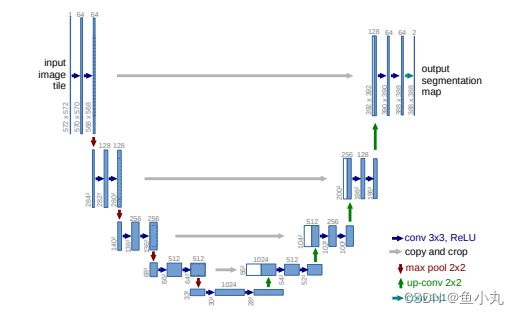
U-net分为两个部分。(中间对称)一部分是左边部分是典型的CNN架构的收缩路径(两个连续的3×3卷积+ReLU激活单元+最大池化层),每一次下采样后我们都把特征通道的数量加倍。第二部分是扩展路径(2×2上采样+收缩路径中对应的层裁剪得到与上采样得到的图片大小相同大小的图片concatenated上采样的特征地图上+2次连续的3×3conV+ReLU),每次使用反卷积都将特征通道数量减半,特征图大小加倍。最后阶段增加1×1卷积将特征图减少到所需数量的通道并产生分割图像。
之前它进行卷积由于没加padding,所以它每一次卷积过后图片的w和h都会减2,现在一般加上padding,使每次卷积后的图像大小不变,就省去了裁剪的操作(之前裁剪后才能与上采样的图片大小匹配,那篇文章中是说图片边缘信息不重要裁剪不会造成太大影响)。
对卷积不熟悉的可以看这个:
卷积算法:https://gitcode.net/mirrors/vdumoulin/conv_arithmetic?utm_source=csdn_github_accelerator
import torch
import torchvision.transforms.functional
from torch import nn
'''
两个3×3卷积层
不管是收缩路径还是扩张路径每一步都有两个3×3的卷积层,然后是ReLU激活。
在U-Net论文中,它们使用0 padding,这里使用1 padding,以便最后的特征图不会被裁剪
'''
import torch
import torchvision.transforms.functional
from torch import nn
import cv2
from torchvision import transforms
'''
两个3×3卷积层
不管是收缩路径还是扩张路径每一步都有两个3×3的卷积层,然后是ReLU激活。
在U-Net论文中,它们使用0 padding,这里使用1 padding,以便最后的特征图不会被裁剪
'''
class DoubleConvolution(nn.Module):
def __init__(self,in_channels:int,out_channels:int):#in_channels:输入通道数 out_channels:输出通道数
super().__init__()
self.first = nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1)
self.act1 = nn.ReLU() #这两行是第一个3×3卷积层,从U-net架构图可以看出在这一层图像的通道数已经变成out_channel
self.second = nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
self.act2 = nn.ReLU() #这两行是第二个卷积,从U-net架构图可以看出在这一层图像的通道数不变
#函数实例化,下面调用相应的函数
def forward(self,x:torch.Tensor):
x = self.first(x)
x = self.act1(x)
x = self.second(x)
return self.act2(x)
class DownSample(nn.Module):#下采样,收缩路径中的每一步都使用2×2最大池化层对特征图进行下采样
def __init__(self):
super().__init__()
self.pool = nn.MaxPool2d(2) #最大池化层
def forward(self,x:torch.Tensor):
return self.pool(x)
class UpSample(nn.Module):#上采样,扩展路径中每一步都使用2×2上卷积
def __init__(self,in_channels:int,out_channels:int):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels,out_channels,kernel_size=2,stride=2)
'''输出数据体在空间上的尺寸可以通过输入数据体尺寸,卷积层中卷积核尺寸(F对应kernel_size),步长(S对应stride)和零填充的数量(P该函数中默认为0)计算出来。
W2=(W1-F+2P)/S+1,上采样大小减半->s=2,w2=w1/2->P=0,F=2
对转置卷积感兴趣的可以看这个https://blog.csdn.net/qq_39478403/article/details/121181904,注意函数中对应的参数即可
'''
def forward(self,x:torch.Tensor):
return self.up(x)
class CropAndConcat(nn.Module): #裁剪并串联要素地图,在扩展路径中的每一步,来自收缩路径的对应特征图与当前特征图连接
def forward(self, x : torch.Tensor, contracting_x : torch.Tensor):
contracting_x = torchvision.transforms.functional.center_crop(contracting_x,[x.shape[2],x.shape[3]])
#torchvision.transforms.functional.center_crop ( img : Tensor , output_size : List [int ]), imgs是要中心裁剪的图像,后面List是裁剪后的大小
x = torch.cat([x,contracting_x],dim=1)
return x
class UNet(nn.Module):
def __init__(self,in_channels:int,out_channels:int):
super().__init__()
self.down_conv = nn.ModuleList([DoubleConvolution(i,o) for i,o in
[(in_channels,64),(64,128),(128,256),(256,512)]])#收缩路径的双层卷积。从64开始的每一步中,特征的数量加倍
self.down_sample = nn.ModuleList([DownSample() for _ in range(4)])#循环4次
self.middle_conv = DoubleConvolution(512,1024)#U-net的底部,分辨率最低的两个层
self.up_sample = nn.ModuleList([UpSample(i,o) for i,o in
[(1024,512),(512,256),(256,128),(128,64)]])
self.up_conv = nn.ModuleList([DoubleConvolution(i,o) for i,o in
[(1024,512),(512,256),(256,128),(128,64)]])
self.concat = nn.ModuleList([CropAndConcat() for _ in range(4)])
self.final_conv = nn.Conv2d(64,out_channels,kernel_size=1)
def forward(self,x:torch.Tensor):
pass_through = []
for i in range(len(self.down_conv)):# 收缩路径,ModuleList可以理解为这个模型中的列表,具体可以查看其他资料
x = self.down_conv[i](x) #两个3x3卷积层
pass_through.append(x) #收集输出,在元素结尾插入指定内容
x = self.down_sample[i](x) #下采样
x = self.middle_conv(x)
for i in range(len(self.up_conv)):#扩张路径
x = self.up_sample[i](x)
x = self.concat[i](x,pass_through.pop())#连续接收收缩路径的输出,pop删除并返回最后一个元素。堆栈
x = self.up_conv[i](x)
x = self.final_conv(x)
return x
二、U-Net的变体
待更新
总结
本文目前只更新了U-net的架构及其模型的代码。怎么运用数据集和怎么训练之后摸索摸索再更新。