一种基于计算机视觉的摄像机智能火灾检测方法 (英文论文翻译 )
英文版论文原文:https://www.sciencedirect.com/science/article/pii/S0957582018314526?via%3Dihub
一种基于计算机视觉的摄像机智能火灾探测方法
An intelligent fire detection approach through cameras based on computer vision methods
Hao Wu, Deyang Wu& Jinsong Zhao
- 清华大学化学工程系,化学工程国家重点实验室,北京100084
- State Key Laboratory of Chemical Engineering, Department of Chemical Engineering, Tsinghua University, Beijing, 100084, China
- 清华大学工业大数据系统与应用北京市重点实验室,北京100084
- Beijing Key Laboratory of Industrial Big Data System and Application, Tsinghua University, Beijing, 100084, China
Abstract
火灾是石油和化工厂中最严重的事故之一,可能会导致相当大的生产损失,设备损坏和人员伤亡。传统的火灾探测是由操作员通过石油和化学设施中的摄像机完成的。然而,对于大型化学设施中的操作者而言,及时发现火灾是不切实际的工作,因为可能安装了数百台摄像机,并且操作员在轮班期间可能承担多项任务。随着计算机视觉的飞速发展,智能火灾探测已引起了学术界和工业界的广泛关注。在本文中,我们提出了一种新颖的通过摄像机的智能火灾探测方法,可防止化工厂和其他高火灾风险行业失控火灾隐患。该方法包括三个步骤:运动检测,火灾检测和区域分类。首先,通过背景减法通过摄像机检测运动物体。然后,由可检测出火灾区域及其位置的火灾探测模型确定带有运动物体的框架。由于可能会生成假着火区域(某些类似于火的物体),因此使用区域分类模型来识别它是否是着火区域。一旦在任何摄像机中出现火灾,该方法就可以对其进行检测并输出火灾区域的坐标。同时,即时消息将立即作为火灾警报发送给安全主管。该方法可以在精度和速度上满足实时火灾探测的需求。其工业部署将有助于在早期阶段发现火灾,促进应急管理,从而为预防损失做出巨大贡献。
Fire that is one of the most serious accidents in petroleum and chemical factories, may lead to considerable production losses, equipment damages and casualties. Traditional fire detection was done by operators through video cameras in petroleum and chemical facilities. However, it is an unrealistic job for the operator in a large chemical facility to find out the fire in time because there may be hundreds of video cameras installed and the operator may have multiple tasks during his/her shift. With the rapid development of computer vision, intelligent fire detection has received extensive attention from academia and industry. In this paper, we present a novel intelligent fire detection approach through video cameras for preventing fire hazards from going out of control in chemical factories and other high-fire-risk industries. The approach includes three steps: motion detection, fire detection and region classification. At first, moving objects are detected through cameras by a background subtraction method. Then the frame with moving objects is determined by a fire detection model which can output fire regions and their locations. Since false fire regions (some objects similar with fire) may be generated, a region classification model is used to identify whether it is a fire region or not. Once fire appears in any camera, the approach can detect it and output the coordinates of the fire region. Simultaneously, instant messages will be immediately sent to safety supervisors as a fire alarm. The approach can meet the needs of real-time fire detection on the precision and the speed. Its industrial deployment will help detect fire at the very early stage, facilitate the emergency management and therefore significantly contribute to loss prevention.
1. Introduction
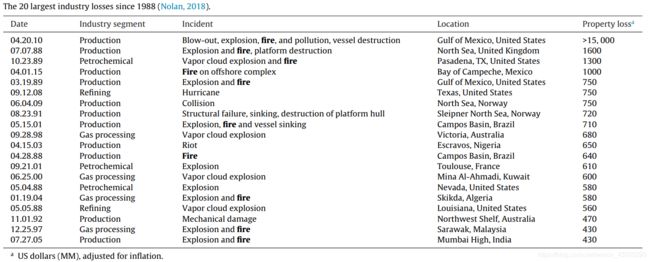
石油和化工厂的火灾可能会导致相当大的生产损失,设备损坏和人员伤亡。表1列出了自1988年以来的20大行业损失,其中一半事故是着火的(Nolan,2018)。早期的火灾探测可以有效地防止火势蔓延,并最大程度地减少火灾造成的损失。在室内环境中,烟雾报警器和火焰报警器广泛用于火灾报警。然而,这些传统的物理传感器具有许多限制。它们需要靠近火源,以使其无法在室外场景中工作(Shi等人,2017)。此外,他们通常需要将火燃烧一段时间才能产生大量烟雾,然后触发警报(Zhang et al。,2016)。此外,他们无法提供有关火灾地点和火灾规模的信息(Frizzi等,2016)。在实际情况中,在大型工厂中安装了数百台摄像机,而在控制室中仅安装了几个监视屏幕。这意味着只能同时显示几个摄像机,而其他摄像机必须轮流显示。为了显示所有摄像机,可能需要数十分钟。在此期间,负责监视监控屏幕的操作员可能会发生火灾事故并错过火警事故。另外,操作人员通常还有其他任务,例如监视DCS控制系统。因此,迫切需要开发一种自动检测火灾隐患的新方法。
Fire in petroleum and chemical factories may lead to considerable production losses, equipment damages and casualties. Table 1 lists the 20 largest industry losses since 1988 and half of the incidents had fire (Nolan, 2018). Fire detection at the early stage can effectively prevent the spread of fire and minimize the damage caused by fire. In indoor environments, smoke detectors and flame detectors are widely used for fire alarms. However, these traditional physical sensors have a number of limitations. They require a close proximity to fire sources so that they cannot work for the outdoor scenes (Shi et al., 2017). Besides, they generally require the fire to burn for a while to produce large amount of smoke and then trigger the alarm (Zhang et al., 2016). Moreover, they cannot provide information about fire location and fire size (Frizzi et al., 2016). In practical scenarios, there are hundreds of video cameras installed in a large factory and only a few monitoring screens in a control room. This means that only several cameras can be displayed simultaneously and the other cameras have to take turns to be displayed. In order to display all of the cameras, it may take dozens of minutes. During this period, fire accidents may occur and be missed by the human operator who is in charge of watching the monitoring screens. In addition, the human operators often have other tasks such as monitoring the DCS control systems. Therefore, there is an urgent demand to develop a new approach to automatically detect the fire hazards.
Table 1
随着数码相机技术和计算机视觉技术的飞速发展,已经提出了智能视频火灾探测方法,并在一些行业中得到应用。 视频火灾探测的发展经历了两个阶段。 最初,通过使用颜色模型和手动设计的功能进行火灾探测(Chen等,2004; Horng等,2005; Marbach等,2006;Töreyin等,2006; Celik和Kai- Kuang,2008; Celik,2010; Foggia等,2015)。 他们专注于火焰的颜色和形状特征。 常规的视频火灾检测方法通过提取多维特征向量并将特征向量分类为“火灾”或“非火灾”类来解决该问题。 但是,由于区分特征提取器是手工设计的,因此这些方法不够鲁棒,并且难以满足不同场景的需求。
With the rapid development of digital camera technology and computer vision technology, intelligent video fire detection methods have been proposed and applied in some industries. The development of video fire detection has gone through two stages. At the beginning, fire detection was done by using color model and hand-designed features (Chen et al., 2004; Horng et al., 2005; Marbach et al., 2006; Töreyin et al., 2006; Celik and Kai-Kuang, 2008; Celik, 2010; Foggia et al., 2015). They focused on color and shape characteristics of flames. Conventional video fire detection methods addressed the problem by extracting a multi-dimensional feature vector and classifying the feature vector into “fire” or “non-fire” class. However, since the discriminative feature extractors were hand-designed, these methods were not robust enough and were difficult to meet the needs of different scenarios.
在2012年著名的ImageNet大规模视觉识别挑战赛(ILSVRC)中,使用深度卷积神经网络(CNN)的模型AlexNet(Krizhevsky和Hinton,2012年)赢得了冠军。从那时起,CNN带来了计算机视觉和模式识别方面的一场革命。 CNN能够在一个网络内执行特征提取和分类。 CNN还可以取代手工设计的功能并了解对象的完整特征。为了获得更好的检测性能,近三年来提出了一些基于卷积神经网络(CNN)的视频火灾检测方法。 Frizzi等。 (2016年)提出了用于视频火灾和烟雾检测的CNN。结果表明,基于CNN的方法比一些相关的常规视频火灾检测方法具有更好的性能。张等。 (2016年)提出了一种基于CNN的森林火灾检测方法。该检测以级联方式进行。首先,通过全局图像级别分类器测试来自摄像机的帧,如果检测到火灾,则遵循细粒补丁分类器来检测火灾补丁的精确位置。 Wang等。 (2017)开发了一种基于CNN和支持向量机(SVM)的新颖方法。他们用SVM替换了完全连接的层以执行分类任务。它显示出比纯CNN更好的性能。 Maksymiv等。 (2017)提出了一种基于AdaBoost,局部二进制模式(LBP)和CNN的检测级联方法。
In the famous ImageNet Large Scale Visual Recognition Challenge (ILSVRC) competition in 2012, AlexNet (Krizhevsky and Hinton, 2012), the model that used a deep convolutional neural network (CNN) won the champion. Since then, CNN has brought about a revolution in computer vision and pattern recognition. CNN has the ability to perform feature extraction and classification within one network. CNN can also replace the hand-designed features and learn the complete characteristics of objects. To achieve better detection performance, some convolutional neural network (CNN) based video fire detection methods have been proposed over the past three years. Frizzi et al. (2016) proposed a CNN for video fire and smoke detection. The results showed that CNN based method achieved better performance than some relevant conventional video fire detection methods. Zhang et al. (2016) proposed a CNN based method for forest fire detection. The detection was operated in a cascaded fashion. At first, the frame from a camera is tested by the global image-level classifier, if fire is detected, the fine grained patch classifier is followed to detect the precise location of fire patches. Wang et al. (2017) developed a novel approach based on CNN and support vector machine (SVM). They replaced the fully connected layer with SVM for the classification task. It showed better performance than the pure CNN. Maksymiv et al. (2017) presented a cascaded approach based on AdaBoost, local binary patterns (LBP) and CNN for detection.
尽管它们具有出色的火灾探测性能,但在实际应用中仍然存在一些局限性。前述方法利用CNN作为分类器,因此它们只能检测图像中是否存在火灾。由于几乎所有像素都是背景,因此几乎不可能知道起火的位置,并且很难从相机检测大图像中的小起火。其中一些(Maksymiv等,2017; Wang等,2017)必须使用常规的手工设计特征提取器提取感兴趣区域(ROI),然后检测ROI中的火灾。但是,这违反了用CNN替换手动设计的特征提取器的目的,并且该方法无法了解火焰的全部特征。他们中的一些人(Frizzi等人,2016; Zhang等人,2016)利用滑窗方法克服了这一问题。原始图像分为许多补丁,每个补丁由CNN检测。补丁大小是固定的,通常小于射击大小。结果,补丁分类器也无法学习火焰的全部特征。此外,应通过CNN网络计算每个生成的ROI或补丁。由于CNN的计算会花费大量时间和硬件资源,因此在没有良好硬件资源的情况下,这些方法在检测速度方面仍然不能令人满意。此外,这些方法并未考虑到应用中有许多与火灾相似的对象。因为他们的CNN模型着重于火灾图像和非火灾图像之间的分类,所以类似火灾的物体可能会导致过多的错误警报。
Despite their excellent performance for fire detection, there were still some limitations during the practical application. The aforementioned methods utilized CNN as a classifier so that they can only detect whether fire exists in an image or not. It is almost impossible to know the fire location and it is difficult to detect a small fire in a large image from a camera because most of the pixels are the background. Some of them (Maksymiv et al., 2017; Wang et al., 2017) had to use conventional hand-designed feature extractors to extract the regions of interest (ROI), then detect the fire in the ROI. However, this violates the purpose of replacing the handdesigned feature extractors with CNN, and the approach doesn’t learn the complete characteristics of the flame. Some of them (Frizzi et al., 2016; Zhang et al., 2016) utilized a slide window method to overcome this problem. The raw image is divided into many patches and each patch is detected by CNN. The patch size is fixed and usually less than the fire size. As a result, patch classifier also cannot learn the complete characteristics of the flames. Besides, each of the generated ROIs or patches should be computed via the CNN network. Since the CNN computation costs lots of time and hardware resources, these methods are still not satisfactory in term of detection speed when there is not a good hardware resource. Moreover, these methods didn’t consider that there are many objects similar with fire in application. Because their CNN model focused on the classification between fire images and non-fire images, the fire-like objects might lead to too many false alarms.
在本文中,我们提出了一种新颖的智能火灾探测方法,旨在实现高探测率,低误报率和高速度。 为了减少CNN的计算,我们增加了一种运动检测方法。 仅当出现移动物体时,才会执行以下计算。 为了代替手工设计的特征提取器或滑动窗口方法来生成ROI,我们使用了基于CNN的目标检测方法来直接生成火灾区域。 然后,我们着重于火灾图像和类火图像之间的分类,以避免误报问题。 本文的其余部分安排如下:第2节介绍了建议的方法。 第三部分显示了实验结果,最后第四部分总结了本文。
In this paper, we present a novel intelligent fire detection approach, which aims to achieve high detection rate, low false alarm rate and high speed. In order to reduce the CNN computation, we added a motion detection method. Only if moving objects appear, the following computations will be implemented. To replace the hand-designed feature extractors or the slide window methods for ROI generation, we used an object detection method based on CNN to generate fire regions directly. Then we focused on the classification between fire images and fire-like images to avoid the false alarm problem. The rest of this paper is organized as follows: Section 2 describes the proposed approach. Section 3 shows the experimental results and finally section 4 summaries this paper.
2. Method
2.1. Computer vision
近年来,随着深度学习(DL)和人工智能(AI)的飞速发展,计算机视觉引起了学术界和工业界的极大关注,并取得了惊人的成功。 在此期间,最重要的事件是深层CNN的出现。 CNN最早是在1980年代后期提出的(LeCun等,1989),以取代传统的手工设计特征描述符,例如尺度不变特征变换(SIFT),定向梯度直方图(HOG)和局部二进制模式(LBP)。。 2012年,一个名为AlexNet的CNN架构(Krizhevsky和Hinton,2012年)赢得了ImageNet大规模视觉识别挑战赛(ILSVRC)的冠军,并且错误率仅次于第二模型。 从那时起,CNN带来了计算机视觉和模式识别方面的一场革命(LeCun等,2015)。 现在,CNN已成为计算机视觉乃至机器学习任务中的主要方法。
Recently, with the rapid development of deep learning (DL) and artificial intelligence (AI), computer vision has drawn significant attention from academia and industry, and has achieved spectacular success. During this period, the emergence of deep CNN was the most important event. CNN was first proposed in the late 1980s (LeCun et al., 1989), to replace the traditional hand-designed feature descriptors such as scale invariant feature transform (SIFT), histogram of oriented gradient (HOG) and local binary pattern (LBP). In 2012, a CNN architecture named AlexNet (Krizhevsky and Hinton, 2012) won the champion of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) competition and achieved half the error rate of the second-best model. Since then, CNN has brought about a revolution in computer vision and pattern recognition (LeCun et al., 2015). Now CNN has become the dominant method in computer vision and even machine learning tasks.

图1. 计算机视觉领域中的三个任务。
Fig. 1. Three tasks in computer vision domain.
在计算机视觉领域,有三个主要任务,分别是图像分类,对象检测和实例分割。 其中,图像分类已使用ImageNet数据集进行了全面研究。 图像分类旨在识别图像的类别(参见图1(a))。 在此任务中,使用基于CNN的方法的计算机性能已经超越了人类。 物体检测旨在检测和定位图像中的物体(见图1(b))。 这意味着模型将输出对象的标签及其坐标。 此外,实例分割采用对象检测方法从一个图像中构筑出不同的实例,然后使用语义分割方法标记不同实例区域中的每个像素(见图1(c))。
In computer vision domain, there are three main tasks, which re image classification, object detection, instance segmentation. Among them, image classification has been studied completely with the ImageNet dataset. Image classification aims to identify the classes of the images (see Fig. 1(a)). In this task, the performance of computers using CNN based methods has surpassed humans. Object detection aims to detect and locate objects in images (see Fig. 1(b)). This means that the model will output the labels of objects and their coordinates. Besides, instance segmentation frames different instances from one image with object detection method, and then uses semantic segmentation method to mark each pixel in different instance areas (see Fig. 1©).
在我们的方法中,图像分类和目标检测方法相结合来处理火灾检测。图像分类依赖于CNN模型,其输入和输出分别是图像和预测标签。对于我们作为二进制分类问题的方法,如果我们将火警图像输入到CNN,则网络将输出2长度的矢量,例如[0.1,0.9]。 “ 0.1”表示在输入图像中不发射的可能性,而“ 0.9”表示发射的可能性。这样,CNN可以预测图像的标签。 CNN的基本体系结构是几层的堆栈,例如卷积层,池化层,批处理规范化层和完全连接的层。最近,研究人员提出了一些性能更高的模块,例如初始(Szegedy等人,2015,2016),残差(He等人,2016)和Xception模块(Chollet,2017)。但是,来自相机的大多数帧都包含很多背景,这可能会干扰标签预测。因此,我们利用物体检测来直接检测帧中的着火区域。有两种类型的对象检测方法:两阶段方法和一阶段方法。两阶段方法基于区域提议,包括R-CNN(Girshick等,2014),Fast R-CNN(Girshick,2015),Faster R-CNN(Ren等,2017)等。这些方法将物体检测分为两部分。首先,它们会生成许多可能存在对象的区域建议。然后将每个区域建议输入到CNN模型中,以预测区域建议的标签并调整其坐标。一阶段方法将检测任务视为一种回归问题,包括YOLO(您只看一个)(Redmon等人,2016,2017),SSD(Liu等人,2016)等。这些方法将输出类对象的概率和坐标。由于两阶段方法会生成许多区域建议,并且每个区域建议都需要输入到网络中,因此检测将占用大量时间和计算资源。一阶段方法可以实现更快的检测速度,但是其准确性比两阶段方法要低一些。在我们的火灾探测任务中,考虑到实时速度,我们选择YOLO方法进行目标探测。
In our approach, image classification and object detection methods are combined to deal with fire detection. Image classification relies on a CNN model, the input and the output of which are images and predictive labels respectively. For our approach as a binary classification issue, if we input a fire image to CNN, the network will output a 2-length vector like [0.1, 0.9]. “0.1” means the probability of non-fire in the input image and “0.9” means the probability of fire. In this way, CNN can predict the labels of images. The basic architecture of CNN is a stack of several layers, such as convolutional layers, pooling layers, batch normalization and fully connected layers. Recently, some modules with greater performance have been presented by researchers, such as inception (Szegedy et al., 2015, 2016), residual (He et al., 2016) and xception modules (Chollet, 2017). However, most of frames from cameras include lots of background, which may interfere the label prediction. Therefore, we utilized object detection to detect the fire regions in frames directly. There are two categories of methods for object detection: two-stage methods and one-stage methods. Two-stage methods are based on region proposal, including R-CNN (Girshick et al., 2014), Fast R-CNN (Girshick, 2015), Faster R-CNN (Ren et al., 2017), etc. These methods divide the object detection into two parts. At first, they generate many region proposals where objects may exist. Then each region proposal will be input into a CNN model, to predict the labels of region proposals and adjust their coordinates. One-stage methods regard the detection task as a regression problem, including YOLO (You only look one) (Redmon et al., 2016, 2017), SSD (Liu et al., 2016), etc. These methods will output the class probabilities and coordinates of objects directly. Because the two-stage methods generate many region proposals and each of them needs to be input to the network, the detection will take up lots of time and computing resources. One-stage methods can achieve faster detection speed but the accuracy is a little lower than two-stage methods. In our fire detection task, considering the real-time speed, we select YOLO method for the object detection.
2.2. Framework

图2. 智能视频火灾检测方法的框架。
Fig. 2. Framework of the intelligent video fire detection approach.
图2显示了所提出的智能火灾探测方法的框架。该方法有两个关键步骤,分别是基于对象检测方法的火灾检测步骤和基于图像分类方法的区域分类步骤。在申请之前,我们应该为这两个步骤训练两个CNN网络。在应用阶段,通过背景扣除方法捕获并处理来自监视摄像机的视频,该方法可以从静态场景中检测运动物体。如果出现移动物体(火灾是移动物体),则经过训练的火灾探测网络将处理当前帧。网络将直接预测火灾区域的概率和坐标,即ROI。但是,在此步骤中,网络可能会生成一些错误的ROI,例如红色/橙色/黄色的衣服,头盔,灯等。我们继续使用受过训练的区域分类网络来识别每个生成的ROI是否是火区或不。这样,一旦当前帧中出现火灾,该方法便可以找到火灾区域。同时,火灾区域所在的框架将立即发送给安全主管,作为火灾警报。在下面的部分中,将详细描述背景扣除,火灾检测和区域分类。
Fig. 2 shows the framework of the proposed intelligent fire detection approach. The approach has two key steps, which are fire detection step based on object detection method and region classification step based on image classification method. Before the application, we should train two CNN networks for these two steps. At the application stage, videos from surveillance cameras are captured and processed by the background subtraction method, which can detect moving objects from static scenes. If moving objects appear (fire is a moving object), the current frame will be processed by the trained fire detection network. The network will directly predict the probabilities and coordinates of fire regions, which are ROIs. However, in this step, the network may generate some false ROIs such as red/orange/yellow clothes, helmets, lights, etc. We continue to use the trained region classification network to identify whether each of the generated ROIs is a fire region or not. In this way, once fire appears in the current frame, the approach can find the fire region. Simultaneously, the frame where the fire region is localized will be immediately sent to safety supervisors as a fire alarm. In the following part, the background subtraction, fire detection and region classification will be described in details.
2.3. Background subtraction

图3. 视频流的背景减法过程
Fig. 3. Background subtraction process for video streams.
计算服务器从室外监控摄像机捕获视频流。背景扣除的目的是消除大多数静态图像帧并减少图像计算的资源,因为网络是在GPU上进行计算以加快速度。早期的背景扣除方法基于高斯混合模型(GMM)(Power and Schoonees,2002; Hayman and Eklundh,Hayman,2003)。此外,为提高GMM的自适应速度,KaewTraKulPong和Bowden于2002年开发了高斯自适应混合方法。一项研究表明,基于KNN的方法在简单的静态场景中具有更好的性能(Zivkovic和Van Der Heijden,2006)。这种方法更适合我们在室外静态场景中的火灾探测任务。视频流捕获和背景减法由OpenCV实现,OpenCV是一个开源计算机视觉库。图3说明了整个背景扣除过程。首先,为消除图像噪声,将高斯模糊应用于一个视频流的原始帧(请参见图3(a))。之后,在图3(a)中实现了基于KNN的背景减法。我们可以捕获移动物体(例如火和人),它们是图3(b)中的白色区域。但是我们可以发现在图3(b)中有一些灰色区域(在绿色圆圈中),因此我们将图像二值化并在图3(c)中用白色标记运动对象。最后,使用形态学的闭合操作将少量离散区域组合成一个完整区域(红色圆圈中)。以这种方式,在图3(d)中检测到整个移动物体。
Video streams are captured from outdoor surveillance cameras by a computing server. Background subtraction aims to eliminate most of static image frames and retrench the resources of image computation, because the networks are computed on GPUs to accelerate the speed. The early methods for background subtraction were based on Gaussian Mixture Model (GMM) (Power and Schoonees, 2002; Hayman and Eklundh, Hayman, 2003). Besides, to improve the adaptation speed of GMM, the Adaptive Mixture of Gaussian method was developed by KaewTraKulPong and Bowden in, 2002. A study showed that KNN based method has better performance on simple static scenes (Zivkovic and Van Der Heijden, 2006). This method is more suitable for our fire detection task in outdoor static scenes. The video stream capture and the background subtraction are implemented by OpenCV, which is an open source computer vision library. Fig. 3 illustrates the whole background subtraction process. First, to eliminate the noise of images, Gaussian blur is applied on the original frames from one video stream (see Fig. 3(a)). After that, KNN based background subtraction is implemented on Fig. 3(a). We can capture the moving object (such as fire and humans), which is the white regions in Fig. 3(b). But we can find that there are some grey regions (in the green circle) in Fig. 3(b), so we binarize this image and mark the moving object with white color in Fig. 3©. Finally, closing operation of morphology is used to combine little discrete regions into a complete region (in the red circle). In this way, the whole moving object is detected in Fig. 3(d).
在火灾探测方法中,我们将计算整个帧中白色区域的大小。 我们将设置一个阈值n,如果白色区域(运动物体)的大小超过阈值,将执行下一个检测步骤。
In the fire detection approach, we will calculate the size of white regions in the whole frame. We will set a threshold n and if the size of white regions (moving objects) exceeds the threshold, the next detection steps will be implemented.
2.4. Fire detection
火灾探测模型是我们方法中的关键步骤之一。 此模型将从背景减法步骤中处理带有移动对象的帧,并在可能存在火灾的位置生成ROI。 火灾探测模型是通过YOLO方法开发的。 YOLO将对象检测框架化为空间分隔边界框和相关类概率的回归问题。 它训练像CNN这样的单个神经网络,直接在一次评估中根据图像预测边界框和分类概率。 它是为多对象检测而设计的,但是,火灾检测是一个单对象(火灾)检测任务。
The fire detection model is one of the key steps in our approach. This model will process the frames with moving objects from the background subtraction step and generate the ROIs where fire may exist. The fire detection model is developed by YOLO method. YOLO frames object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. It trains a single neural network like CNN to predict bounding boxes and class probabilities directly from images in one evaluation. It is designed for multi-object detection, however, fire detection is a single-object (fire) detection task.

图4. YOLO的网格划分和预测
Fig. 4. Grid partition and prediction of YOLO.
要将帧输入到CNN中,图像的大小应调整为416×416像素。 YOLO将输入图像划分为S×S网格(请参见图4)。 如果对象的中心落入网格单元,则该网格单元负责检测该对象。 YOLO的网络为每个网格单元中的k个边界框(边界框的宽度和高度不同)预测了三个部分:坐标,置信度得分和条件分类概率。
To input the frame into the CNN, the image should be resized to 416 × 416 pixels. YOLO divides the input image into an S × S grid (see Fig. 4). If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. The network of YOLO predicts three parts for k bounding boxes (the bounding boxes are with different width and height) in each grid cell: coordinates, confidence scores and conditional class probabilities.

图5. 带锚框的边界框的位置预测(Redmon和Farhadi,2017年)。
Fig. 5. Location predictions of bounding boxes with anchor boxes (Redmon and Farhadi, 2017).
YOLO不会直接预测边界框的坐标,而是使用k个精选的先验先验值(称为锚定框)来预测k个边界框。 根据YOLO的论文,预测偏移量而不是坐标可以简化问题,并使网络更易于学习(Redmon和Farhadi,2017年)。 网络为每个边界框预测4个坐标的偏移和置信度得分: t y t_y ty, t w t_w tw, t h t_h th 和 t o t_o to(见图5)。 如果单元格从图像的左上角偏移了( c x c_x cx, c y c_y cy),并且先前的边界框(锚定框)的宽度和高度( p w p_w pw, p h p_h ph),则边界框 预测对应于等式 (1)〜(5),其中 σ \sigma σ 是逻辑激活。 这限制了相应网格单元内的预测边界框中心。
Instead of predicting coordinates of the bounding boxes directly, YOLO uses k hand-picked priors (named anchor boxes) to predict k bounding boxes. According to the paper of YOLO, predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn (Redmon and Farhadi, 2017). The network predicts the offsets of 4 coordinates and a confidence score for each bounding box: t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, and t o t_o to (see Fig. 5). If the cell is offset from the top left corner of the image by ( c x c_x cx, c y c_y cy) and the bounding box prior (anchor box) has width and height ( p w p_w pw, p h p_h ph), then the bounding box predictions correspond to Eq. (1)˜(5), where σ \sigma σ is the logistic activation. This bounds the predicted bounding box centers within the corresponding grid cell.
b x = σ ( t x ) + c x (1) \tag{1} b_x=\sigma(t_x)+c_x bx=σ(tx)+cx(1)
b y = σ ( t y ) + c y (2) \tag{2} b_y=\sigma(t_y)+c_y by=σ(ty)+cy(2)
b w = p w e t w (3) \tag{3} b_w=p_we^{t_w} bw=pwetw(3)
b h = p h e t h (4) \tag{4} b_h=p_he^{t_h} bh=pheth(4)
c o n f i d e n c e = σ ( t o ) (5) \tag{5} confidence=\sigma(t_o) confidence=σ(to)(5)
置信度得分反映出该模型包含该对象的置信度。
The confidence score reflects how confident the model is that the box contains an object.
c o n f i d e n c e = P r ( O b j e c t ) × I O U p r e d t r u t h (6) \tag{6}confidence=Pr(Object)×IOU_{pred}^{truth} confidence=Pr(Object)×IOUpredtruth(6)
其中Pr(对象)表示该框中是否存在对象。 如果没有对象,则置信度分数应为0。否则,置信度分数等于预测框与地面真实框(对象实际存在的区域)之间的交集相交(IOU)。
where Pr (Object) represents whether objects exist in that box. If no object, the confidence score should be 0. Otherwise, the confidence score is equal to the intersection over union (IOU) between the predicted box and the ground truth box (the region where objects really exist).
对于多对象任务,每个边界框还预测C个条件类概率 P r ( C l a s s i ∣ O b j e c t ) Pr (Class_i|Object) Pr(Classi∣Object)。 为了获得每个框的特定于类别的置信度分数,将条件的类别概率乘以置信度分数:
For the multi-object task, each bounding box also predicts C conditional class probabilities, P r ( C l a s s i ∣ O b j e c t ) Pr (Class_i|Object) Pr(Classi∣Object). To obtain the class-specific confidence scores for each box, the conditional class probabilities are multiplied by the confidence score:
P r ( C l a s s i ∣ O b j e c t ) × c o n f i d e n c e = P r ( C l a s s i ∣ O b j e c t ) × P r ( O b j e c t ) × I O U p r e d t r u t h = P r ( C l a s s i ) × I O U p r e d t r u t h ) (7) \tag{7}Pr(Class_i|Object)\times confidence=Pr(Class_i|Object)\times Pr(Object)\times IOU_{pred}^{truth}=Pr(Class_i)\times IOU_{pred}^{truth}) Pr(Classi∣Object)×confidence=Pr(Classi∣Object)×Pr(Object)×IOUpredtruth=Pr(Classi)×IOUpredtruth)(7)
这些分数既反映了该类出现在框中的可能性,也反映了预测的框适合对象的程度。 网络对每个图像的预测被编码为 S × S × k × ( 4 + 1 + C ) S × S × k × (4 + 1 + C) S×S×k×(4+1+C) 张量。 对于作为单类检测任务的火灾检测, C = 1 C = 1 C=1。
These scores reflect both the probability of that class appearing in the box and how well the predicted box fits the object. The predictions of the network for each image are encoded as an S × S × k × ( 4 + 1 + C ) S × S × k × (4 + 1 + C) S×S×k×(4+1+C) tensor. For fire detection that is a single-class detection task, C = 1 C = 1 C=1.
为了训练我们的YOLO网络,火灾探测的损失函数定义如下:
For training our network of YOLO, a loss function for fire detection is defined as follows:

其中 ∣ i j o b j |^{obj}_{ij} ∣ijobj 表示对象出现在单元格i的第j个边界框中,而 ∣ i j n o o b j |^{noobj}_{ij} ∣ijnoobj 表示没有对象。 第一项表示如果对象存在,则预测边界框和地面真实框之间的坐标误差。 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 表示预测边界框的坐标, ( x ^ , y ^ , w ^ , h ^ ) (\hat{x},\hat{y},\hat{w},\hat{h} ) (x^,y^,w^,h^) 表示坐标 地面真相箱。 第二和第三项表示具有对象或非对象的边界框的置信度得分误差。 如果地面真理框中存在对象(火),则 c ^ i j = I O U p r e d t r u t h \hat{c}_{ij} = IOU^{truth}_{pred} c^ij=IOUpredtruth , p ^ i j ( f i r e ) = 1 \hat{p}_{ij}(fire) = 1 p^ij(fire)=1 ; 否则 c ^ i j = 0 \hat{c}_{ij} = 0 c^ij=0 , p ^ i j ( f i r e ) = 0 \hat{p}_{ij}(fire) = 0 p^ij(fire)=0 。 最后一项表示如果该网格单元中存在对象,则分类错误(条件类概率)。
where ∣ i j o b j |^{obj}_{ij} ∣ijobj denotes that objects appears in the j th bounding box in cell i and ∣ i j n o o b j |^{noobj}_{ij} ∣ijnoobj denotes that there is no object. The first item denotes the error of coordinates between the predicted bounding boxes and the ground truth boxes, if object exists. ( x , y , w , h ) (x, y, w, h) (x,y,w,h) denote the coordinates of the predicted bounding boxes and ( x ^ , y ^ , w ^ , h ^ ) (\hat{x},\hat{y},\hat{w},\hat{h} ) (x^,y^,w^,h^) denote the coordinates of the ground truth boxes. The second and the third items denote the error of confidence scores of bounding boxes with object or non-object. If objects (fire) exist in the ground truth box, c ^ i j = I O U p r e d t r u t h \hat{c}_{ij} = IOU^{truth}_{pred} c^ij=IOUpredtruth , p ^ i j ( f i r e ) = 1 \hat{p}_{ij}(fire) = 1 p^ij(fire)=1; otherwise c ^ i j = 0 \hat{c}_{ij} = 0 c^ij=0, p ^ i j ( f i r e ) = 0 \hat{p}_{ij}(fire) = 0 p^ij(fire)=0. And the last item denotes the classification error (the conditional class probabilities) if an object is present in that grid cell.
但是,坐标误差和分类误差的大小可能不同。 一幅图像中的大多数网格单元都不包含任何对象。 为了解决这些问题,对于不包含对象的盒子,我们增加了边界框坐标预测的损失,并减少了置信度预测的损失。 我们设置 λ c o o r d = 2 \lambda_{coord} = 2 λcoord=2, λ c l a s s = 1 \lambda_{class} = 1 λclass=1, λ n o o b j = 0.2 \lambda_{noobj} = 0.2 λnoobj=0.2, λ c l a s s = 1 \lambda_{class} = 1 λclass=1。 使用这个损失函数,我们可以用小批量梯度下降法训练网络。
However, the magnitudes of coordinate error and classification error may be different. And most of the grid cells in one image do not contain any object. To remedy these issues, we increase the loss from bounding box coordinate predictions and decrease the loss from confidence predictions for boxes that do not contain objects. We set with λ c o o r d = 2 \lambda_{coord} = 2 λcoord=2, λ c l a s s = 1 \lambda_{class} = 1 λclass=1, λ n o o b j = 0.2 \lambda_{noobj} = 0.2 λnoobj=0.2, λ c l a s s = 1 \lambda_{class} = 1 λclass=1. Using this loss function, we can train the network with mini-batch gradient descent method.
训练后,我们可以应用网络来检测捕获帧的着火区域。 我们应该设置一个阈值 t ∈ ( 0 , 1 t∈(0,1 t∈(0,1,网络将预测每个网格单元中每个边界框的概率。 如果在当前帧中出现火灾,则网络将输出概率为 c i j × p i j ( f i r e ) > t c_ {ij}×p_ {ij}(fire)> t cij×pij(fire)>t 的火灾区域。 但是,由于网络仅在此步骤中了解了火的特性,因此它可能会生成带有类似火的物体的“火区”,例如红色/橙色/黄色的衣服,头盔,灯等。 区域提案,下一步需要严格区分它们。
After the training, we can apply the network to detect the fire regions for the captured frames. We should set a threshold t ∈ ( 0 , 1 ) t ∈ (0, 1) t∈(0,1) and the network will predict the probabilities of each bounding box in each grid cell. If fire appears in the current frame, the network will output the fire region whose probability c i j × p i j ( f i r e ) > t c_{ij} × p_{ij}(fire) > t cij×pij(fire)>t. However, because the network only learnt the knowledge of fire characteristics in this step, it may generate “fire regions” with fire-like objects, such as red/orange/yellow clothes, helmet, lights, etc. So we just obtain the fire region proposals and they need to be distinguished strictly in the next step.
2.5. Region classification
在此步骤中,我们设计了一个CNN模型,以将真实火灾区域(正)与类火区域(负)区分开来,这是典型的分类任务。 由于CNN模型的输入大小是固定的,因此需要将生成的具有不同宽度和高度的ROI调整为256×256像素。 然后,将通过单个CNN模型计算每个调整大小的区域。 由于在ImageNet分类任务上的出色表现,在以下实验中,我们选择了Inception-V3(Szegedy等人,2016),ResNet-50(He等人,2016)和Xception(Chollet,2017)作为CNN 架构,以比较我们在区域分类任务中的表现。
In this step, we design a CNN model to distinguish the real fire regions (positive) from the fire-like regions (negative), which is a typical classification task. Since the input size of CNN model is fixed, the generated ROIs with different width and height need to be resized to 256 × 256 pixels. Then each of the resized regions will be computed through a single CNN model. Due to the excellent performances on ImageNet classification task, in the following experiments, we chose Inception-V3 (Szegedy et al., 2016), ResNet-50 (He et al., 2016) and Xception (Chollet, 2017) as the CNN architectures to compare their performances on our region classification task.

**图6. ** 初始、调整和xception模块。
Fig. 6. Inception, residule and xception modules.
初始模块主要在保持计算预算不变的同时增加了网络的宽度(见图6(a))。 残差模块克服了更深层神经网络的训练问题,使训练100层甚至1000层的网络成为可能(见图6(b))。 Xception解释了Inception模块是介于常规卷积和深度可分离卷积之间的中间步骤。 因此,它用深度可分离卷积代替了Inception模块,并在ImageNet数据集上实现了更高的性能(见图6(c))。
Inception modules mainly increased the width of the network while keeping the computational budget constant (see Fig. 6(a)). Residual module overcame the training problem of deeper neural networks, and made it possible to train the network with 100 or even 1000 layers (see Fig. 6(b)). Xception interpreted the Inception modules are an intermediate step in-between regular convolution and depthwise separable convolution. So it replaced the Inception modules with depthwise separable convolutions and achieved greater performance on ImageNet dataset (see Fig. 6©).
每个调整大小区域的CNN输出为2长度数组 Z = [ Z 1 , Z 2 ] Z = [Z_1, Z_2] Z=[Z1,Z2]。 然后使用softmax函数将其转换为着火和类火的概率。 softmax函数也称为归一化指数函数,它将任意实值的 K K K 维向量Z转换为(0,1)范围内的实值的 K K K 维向量 σ ( Z ) \sigma(Z) σ(Z) 总计1:
The output of the CNN for each resized region is a 2-length array Z = [ Z 1 , Z 2 ] Z = [Z_1, Z_2] Z=[Z1,Z2]. Then using softmax function to transform it into the probabilities of fire and fire-like classes. The softmax function also named normalized exponential function, transforms a K K K-dimensional vector Z of arbitrary real values into a K K K-dimensional vector σ ( Z ) \sigma(Z) σ(Z) of real values in the range of (0,1) that add up to 1:
σ ( Z ) j = e Z j ∑ k = 1 K e Z k , j = 1 , 2... , K (9) \tag{9} \sigma(Z)_ {j} =\frac{e^{Z_j}}{\textstyle\sum_{k=1}^Ke^{Z_k}}, j=1,2...,K σ(Z)j=∑k=1KeZkeZj,j=1,2...,K(9)
输出为数组 σ ( Z ) = [ σ ( Z ) 1 , σ ( Z ) 2 ] \sigma(Z) = [\sigma(Z)_ 1, \sigma(Z)_ 2] σ(Z)=[σ(Z)1,σ(Z)2] 和 σ ( Z ) 1 + σ ( Z ) 2 = 1 \sigma(Z)_ 1 + \sigma(Z)_ 2 = 1 σ(Z)1+σ(Z)2=1. σ ( Z ) 1 \sigma(Z)_ 1 σ(Z)1 表示发生火灾的概率, σ ( Z ) 2 \sigma(Z)_ 2 σ(Z)2 表示发生类似火灾的概率。 因此,如果 σ ( Z ) 1 > 0.5 \sigma(Z)_ 1 > 0.5 σ(Z)1>0.5,则生成的区域是火区;否则,它不是火区。
The output is an array σ ( Z ) = [ σ ( Z ) 1 , σ ( Z ) 2 ] \sigma(Z) = [\sigma(Z)_ 1, \sigma(Z)_ 2] σ(Z)=[σ(Z)1,σ(Z)2] and σ ( Z ) 1 + σ ( Z ) 2 = 1 \sigma(Z)_ 1 + \sigma(Z)_ 2 = 1 σ(Z)1+σ(Z)2=1. σ ( Z ) 1 \sigma(Z)_ 1 σ(Z)1 denotes the probability of fire and σ ( Z ) 2 \sigma(Z)_ 2 σ(Z)2 denotes the probability of fire-like. Therefore, if σ ( Z ) 1 > 0.5 \sigma(Z)_ 1 > 0.5 σ(Z)1>0.5, the generated region is a fire region; otherwise, it’s not a fire region.
3. Experimental results
3.1. Fire detection
3.1.1. Dataset
Fig. 7. Fire detection dataset.
包含火灾区域的图像是从一些火灾图像数据集(例如ImageNet)中收集的,这些数据集是由以前的研究人员以及一些图像搜索引擎(例如Google和百度)建立的。 此外,通过互联网,我们用化工厂火灾和其他场景的图像扩充了我们的数据集。 整个火灾图像数据集包含5075张具有不同宽度和高度的图像。 训练集的比例为80%,即训练集为4060张图像,测试集为1015张图像。 应当注意的是,每个图像可以包含一个或几个着火区域,并且每个着火区域都用一个边界框注释,以描述其位置(见图7)。
Images that contains fire regions, were collected from some fire image datasets (like ImageNet) which were set up by previous researchers and some image search engines such as Google and Baidu. Furthermore, via the internet, we augmented our dataset with the images of chemical plant fire and other scenarios. The whole fire image dataset contains 5075 images with various width and height. The proportion of the training set is 80%, that is, 4060 images as the training set and 1015 images as the testing set. It should be noted that each image may contain one or several fire regions and each fire region is annotated by a bounding box for describing its location (see Fig. 7).
3.1.2. Network
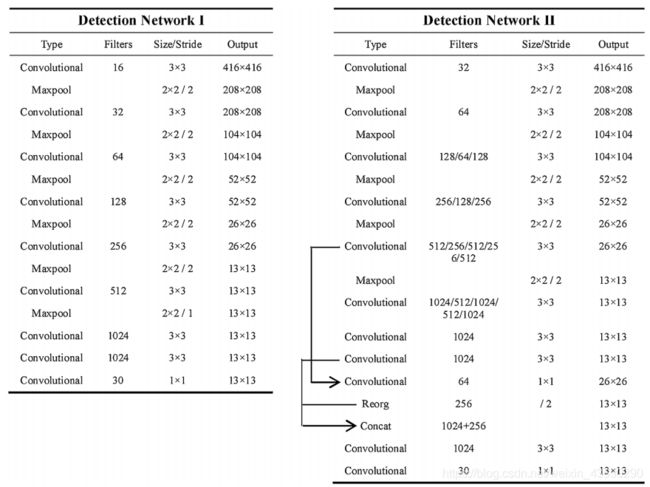
图8. 用于火灾探测的探测网络I和II。
Fig. 8. Detection Network I and II for fire detection.
此步骤的网络如图8所示。为了进行比较,我们选择了两个具有不同网络大小的网络,即检测网络I和II,以验证我们任务的检测性能。 网络的输入为416×416,具有3个通道(RGB)。 这两个网络都由具有批处理归一化和最大池化层的卷积层组成。 网络的输出为13×13×30,这意味着将输入图像划分为13×13的网格,并且网络预测 t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, t o t_o to 和 p ( f i r e ) p(fire) p(fire) 5个锚定框。
The networks for this step are shown in Fig. 8. For comparison, we selected two networks with different network size, Detection Network I and II, to validate the detection performance for our task. The input of the networks is 416 × 416 with 3 channels (RGB). The two networks are both composed of convolutional layers with batch normalization and maxpooling layers. The output of the networks is 13 × 13 × 30, which means that the input image is divided into a 13 × 13 grid and the networks predicts t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, t o t_o to and p ( f i r e ) p(fire) p(fire) for 5 anchor boxes.
如第2.4节所述,由于网络会预测相对于锚点的坐标偏移,因此,锚点的宽度和高度至关重要,并且已在每个网格单元中预先指定了用于预测的坐标。 如果要启动更好的锚定框,网络将更容易预测。 在这里,对训练集的边界框实施了K均值聚类,以找到合适的锚框。 因为我们希望锚框产生良好的IOU分数,所以我们定义K-means算法的距离度量如下:
As mentioned in section 2.4, because the networks predict the offsets of coordinates relative to anchors, widths and heights of anchors are vital and prespecified in each grid cell for prediction. If better anchor boxes for the network to start, it is easier for the network to predict. Here K-means clustering was implemented on the bounding boxes of the training set to find appropriate anchor boxes. Because we want the anchor boxes to lead to good IOU scores, we define the distance metric of the K-means algorithm as follows:
d ( t r u t h , a n c h o r ) = 1 − I O U a n c h o r t r u t h (10) \tag{10} d(truth,anchor)=1-IOU^{truth}_{anchor} d(truth,anchor)=1−IOUanchortruth(10)

图9. 火灾图像数据集上的聚类框尺寸。
Fig. 9. Clustering box dimensions on fire image dataset.
图9显示了具有不同k的聚类框尺寸的平均IOU。 这表明平均IOU随着k的增加而增加。 但是,模型复杂度也会增加。 因此,在模型测试阶段,我们需要考虑模型复杂度和召回率之间的折衷。 在这里,我们选择k =5。表2列出了k = 5的锚框的宽度和高度。
Fig. 9 shows the average IOU of clustering box dimensions with different k. It demonstrates that the average IOU increases with the increase of k. However, the model complexity will also increase. Therefore, at the model testing phase, we need to consider the tradeoff between model complexity and recall rate. Here we select k = 5. Table 2 lists widths and heights of anchor boxes with k = 5.