PCA原理学习及实战应用
欢迎各位童鞋交流和指教!
1. 前言
在接触到了文本的分布式表示(或称嵌入式、向量)后,发现深入学习和理解主成分分析十分有必要,主成分分析(Principal Component Analysis,PCA)可以帮助我们把数据中,相对不重要、或者说对于数据没有很强的区分能力的维度去掉,将数据映射到一个有着主要能区分数据、数据的相关性不大的维度空间里。
这是一个非常经典和美妙的数据分析方法。属于数据降维的方法中的一种(如SVD、LDA、t-SNE等等)。而且在上次师兄讲过PCA的原理后(虽然走神了没听懂。。。)一直想学习和实践,因为这个方法对于目前我对于数据的分析十分有用和迫切需要。前几天把PCA的数学原理学习了一下,同时还回去复习了一下线代。。。今天趁着周末有空就来实践一下啦!
接下来我将阐述PCA的数学原理,以及在scikit-learn、matlab和谷歌的embedding projector上进行实验。
2. PCA的数学原理
在数据挖掘和机器学习中,数据通常被表示成向量。举一个网上人们嚼的烂的例子,某淘宝店一年的数据分析信息如下,其中每一条代表了一天的交易数据:
[日期,浏览量,访客数,下单数,成交数,成交金额]
一般来讲,日期是一个记录标志,不是度量值,我们对于数据分析分析的是度量值,所以把日期删掉。然后得到一个五维向量:
[浏览量,访客数,下单数,成交数,成交金额]T
我们一般取列向量而不是行向量,因为当多条数据组成矩阵之后每一列代表一条数据,可以在后面的运算看到,这样表示的话方便我们表示特征矩阵及之后的运算(估计是习惯了吧,词向量那块人们也都这样做的,忽然转过去的话看起来不习惯。。)。
那么什么是主要成分、什么是区分不同数据能力不强的特征(维度)?
对于上面的例子来说,浏览量和访客数往往具有较强的相关关系,下单数与成交数也有较强的相关关系,所以这两对每一对的两个特征之间对于数据的区分能力不强,也就是说这两对每一对的两个特征中,我们可以去掉其中任意一个,我们期待这样并不会丢失太多信息。为什么要删除呢?因为我们要降低机器学习算法的复杂度。
以上讲的就是PCA的简单的思想描述,有助于直观理解降维的动机和可行性,但并不具有操作指导意义。如:对于数据维数非常大,并且各维没有实际含义,我们应该删除哪行?如何度量各维度携带的信息量?
所以接下来就要介绍PCA主要的实现原理了。
2.1 PCA的主要实现原理
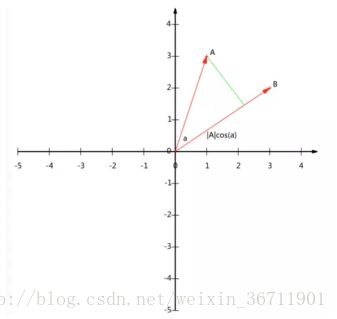
在讲原理之前不得不提的就是向量(或矩阵)的乘法的理解问题了,这里我们举一个简单的例子:A=(X1,Y1)、B=(X2,Y2),对于这两个向量的点乘AB我们知道可以表示为:A在B向量上的投影*B向量的长度,如下图所示。那如果B向量的长度是单位长度,那点乘就是A向量在B上的投影长度,将这个想法拓展到矩阵(如果B矩阵每一列的L2范数等于1),我们可以认为是A矩阵在B矩阵表示的向量空间中的投影。
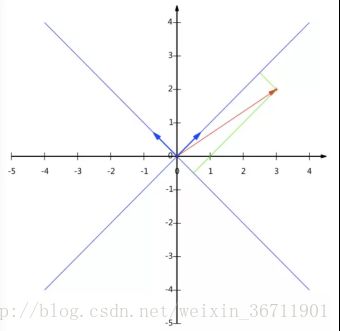
目前所使用的这种坐标系是经典的笛卡尔坐标系,也就是默认基底由(如果是2维空间的话)(1,0)(0,1)组成,那么如果我们找到一组基底,基底之间线性无关,那么就可以构成一个向量空间。
例如二维空间,我们可以使用(1,1)(-1,1)组成一组基底。但我们希望基底模(L2范数)为1,所以归一化后,如下图表示一个(3,2)的向量在新的基底表示下的坐标:
我们借鉴之前点乘代表映射的方式,将(3,2)映射到两个基底的向量维度上: 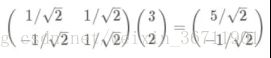
可以发现,经过这样的矩阵乘积运算,我们将(3,2)映射到了新基底组成的空间中,其坐标为(5/2(1/2),-1/2(1/2))。
那如果我有多组数据,乘以这个基底矩阵,就可以得到这些数据分别在新基底向量空间中的映射了: 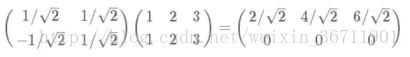
如果扩展一下,其实就是这样的: 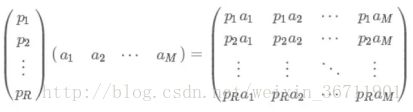
那么接下来问题来了,该如何选择基底呢?接下来由一个列子展开。假设我们有五条数据: 
按照我们之前约定的每一列为一条数据,每一行为数据的一个维度。为了处理方便,我们每条数据的每个维度减去各个维度相应的均值,这样分布集中一些,否则会比较稀疏,同时后面方便方差运算。第一个维度均值为2,第二个维度均值为3,所以变换后: 
在坐标系中的位置:
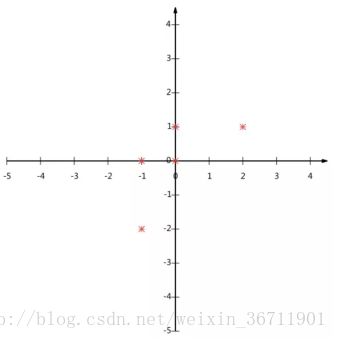
那么如果我们希望用一维数据来表示他们,并且又希望尽量保留原始信息,我们该怎么做?(这时我们可以联想一下SVM是怎么做的,SVM是投影到一个平面上,目标是类间距大,类内距小)
联想到分散程度我们不由自主想到用方差来表示这个问题。
每个维度的方差如下: ![]()
因为我们之前已经减过均值了,所以可以直接用: 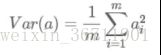
我们希望投影后的数据越发分散,所以方差越大越好。
假设我们只有a,b两个维度: 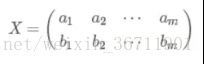
我们用X乘以XT,并乘以系数1/m,得到协方差矩阵: 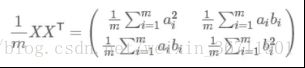
可以看到,对角线上得到的就是每个维度的方差,同时我们还得到了不同维度的协方差,而数学上我们用协方差衡量变量间的相关性。
所以我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
设C为原始矩阵X的协方差矩阵,D为Y矩阵的协方差矩阵,原始矩阵X经过基底矩阵P的映射后得到Y矩阵,那么我们可以得到如下关系: 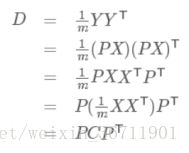
所以发现我们要寻找的P矩阵正是能让原始协方差矩阵对角化的P矩阵,所以现在的优化目标变成了:寻找一个矩阵P,满足D是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
由C矩阵的推倒我们知道C矩阵是一个实对称矩阵,实对称矩阵具有1)实对称矩阵不同特征值对应的特征向量必然正交。2)设特征向量λ重数为r那么必然存在r个线性无关的特征向量(并且单位正交化)。
所以也就有如下结论: 
其中E代表是C矩阵的单位正交特征向量矩阵,Λ代表对角矩阵,对角线上是各个特征向量对应的特征值,那么我们只要求解P=E的矩阵就可以了,然后按照特征值由高到低的排序,选定我们需要的k维主成分。
3.实战
3.1. Scikit-learn中PCA实战
Sklearn是机器学习的一个非常棒的库,里面实现了各种机器学习的算法API供我们使用,其中就包括PCA,关于sklearn中PCA的API的介绍及参数使用可以到官网上看,网址如:http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html#sklearn.decomposition.PCA
使用的工具是anaconda的jupyter notebook。
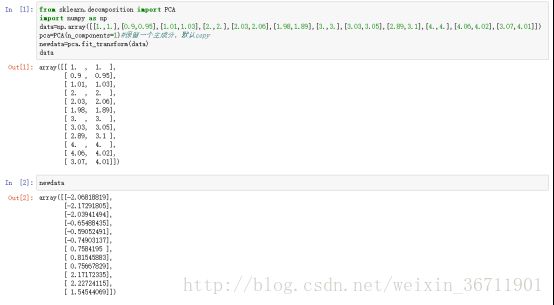
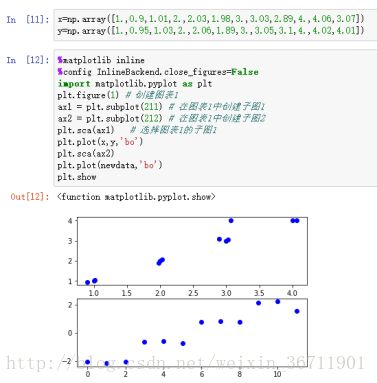
可以明显的看到,对于原始数据,通过PCA将数据降到了一维(用二维显示的目的是更好的可视化),并且自动的分成了四个类别。
其中PCA还带了几个其他的函数及参数,具体可以到官网文档上学习,根据需要取用。
3.2. Matlab中的PCA实战
%该部分转载自【CSDN】http://blog.csdn.net/llp1992
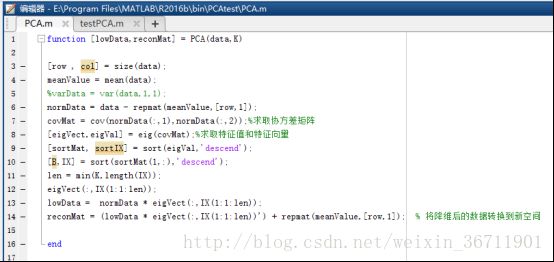
Matlab中PCA的实现使用代码实现,按照前面PCA原理分析的那样有几个实现步骤:
1) 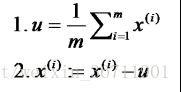
2)求协方差矩阵 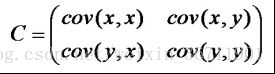
3)求协方差矩阵特征值与特征向量
4)将特征值从小到大进行排列,选择其中最大的k个,然后对应的特征向量进行排序。
注意:matlab 的 eig 函数求解协方差矩阵的时候,返回的特征值是一个特征值分布在对角线的对角矩阵,第 i 个特征值对应于第 i 列的特征向量
5)用特征向量矩阵与X矩阵相乘得到k维主成分。
代码如下:
1)function [lowData,reconMat] = PCA(data,K)
2)[row , col] = size(data);
3)meanValue = mean(data);
4)%varData = var(data,1,1);
5)
6)normData = data - repmat(meanValue,[row,1]);
7)covMat = cov(normData(:,1),normData(:,2));%求取协方差矩阵
8)[eigVect,eigVal] = eig(covMat);%求取特征值和特征向量
9)[sortMat, sortIX] = sort(eigVal,’descend’);
10)[B,IX] = sort(sortMat(1,:),’descend’);
11)len = min(K,length(IX));
12)eigVect(:,IX(1:1:len));
13)lowData = normData * eigVect(:,IX(1:1:len));
14)reconMat = (lowData * eigVect(:,IX(1:1:len))’) + repmat(meanValue,[row,1]); % 将降维后的数据转换到新空间
15)End
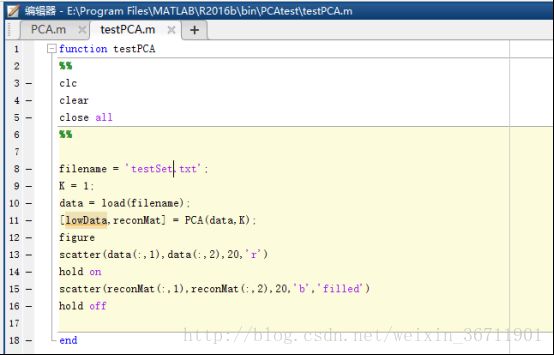
调用方式:
1)function testPCA
2)%%
3)clc
4)clear
5)close all
6)%%
7)filename = ‘testSet.txt’;
8)K = 1;
9)data = load(filename);
10)[lowData,reconMat] = PCA(data,K);
11)figure
12)scatter(data(:,1),data(:,2),5,’r’)
13)hold on
14)scatter(reconMat(:,1),reconMat(:,2),5)
15)hold off
16)end
因为没能在github上找到原数据,所以自己定义了一个数据集。
使用的数据如下: 
最终结果:

由结果可以看到将数据分成了四类。
3.3. Embedding Projector中的PCA、t-SNE及自定义线性投影实战
%以下介绍部分摘自机器之心对googleresearchblog相应博客的翻译:
近段时间以来,机器学习领域内的进展已经催生出了很多激动人心的结果,其应用已经延展到了图像识别、语言翻译、医学诊断等许多领域。对研究科学家来说,随着机器学习系统的广泛应用,理解模型解读数据的方式正变得越来越重要。但是,探索数据的一大主要难题是数据往往具有数百个乃至数千个维度,这需要我们使用特别的工具才能研究调查清楚数据空间。
为了实现一种更为直观的探索过程,谷歌今日布开源了一款用于交互式可视化和高维数据分析的网页工具 Embedding Projector,其作为 TensorFlow 的一部分,能带来类似 A.I. Experiment 的效果(参阅:业界 | 谷歌推出 A.I. Experiments:让任何人都可以轻松实验人工智能)。同时,谷歌也在 projector.tensorflow.org 放出了一个可以单独使用的版本,让用户无需安装和运行 TensorFlow 即可进行高维数据的可视化 。
Embedding Projector 地址:
https://www.tensorflow.org/versions/master/how_tos/embedding_viz/index.html
可单独使用的版本:http://projector.tensorflow.org/
相关论文地址:https://arxiv.org/pdf/1611.05469v1.pdf
Embedding Projector 提供了三种常用的数据降维(data dimensionality reduction)方法,这让我们可以更轻松地实现复杂数据的可视化,这三种方法分别是 PCA、t-SNE 和自定义线性投影(custom linear projections):
1)PCA 通常可以有效地探索嵌入的内在结构,揭示出数据中最具影响力的维度。
2)t-SNE 可用于探索局部近邻值(local neighborhoods)和寻找聚类(cluster),可以让开发者确保一个嵌入保留了数据中的所有含义(比如在 MNIST 数据集中,可以看到同样的数字聚类在一起)。
3)自定义线性投影可以帮助发现数据集中有意义的「方向(direction)」,比如一个语言生成模型中一种正式的语调和随意的语调之间的区别——这让我们可以设计出更具适应性的机器学习系统。
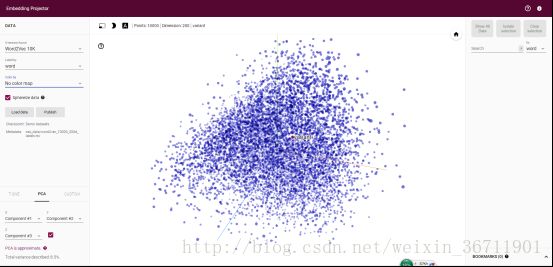
如上图所示是对其提供的10k个word2vec的词向量进行了PCA降维至三维的可视化,可以看到中间密密麻麻的点分布在了有三个坐标轴的空间上,如果放大看的话
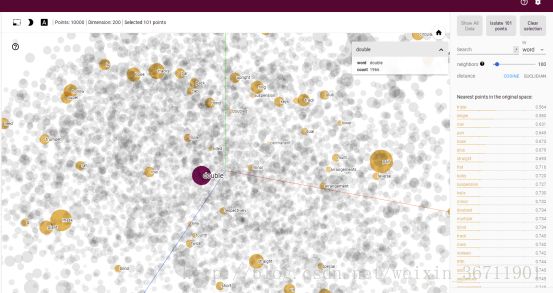
点击每个点可以显示在原语义空间中与该点距离最近的点的信息。点的大小提现的是点距离远近。

这个是降到2维后,可以看到与game原语义空间相似的单词。
这个工具可以拖拽3D效果,来回看,非常直观,而且便捷。


在word2vec提供的所有的词向量中,用PCA降到2维分析了man to woman同king to queen的关系,可以看到确实是那么回事(距离不等是因为可视化有缩放功能,看起来不等是因为缩放)。