python中numpy.random.choice()函数
numpy.random.choice
- 菜鸟教程
-
- 描述
- 语法
- 参数
- 返回值
- 实例
- 官方文档
-
- 介绍
- 参数
- 实例
- 扩展阅读
-
- 先看numpy中choice()
- 再看random中choice()和choices()
- 最后看下random.sample()
菜鸟教程
描述
choice() 方法返回一个列表,元组或字符串的随机项。
语法
以下是 choice() 方法的语法:
import random
random.choice( seq )
注意:choice()是不能直接访问的,需要导入 random 模块,然后通过 random 静态对象调用该方法。
参数
seq -- 可以是一个列表,元组或字符串。
返回值
返回随机项。
实例
以下展示了使用 choice() 方法的实例:
#!/usr/bin/python
import random
print "choice([1, 2, 3, 5, 9]) : ", random.choice([1, 2, 3, 5, 9])
print "choice('A String') : ", random.choice('A String')
以上实例运行后输出结果为:
choice([1, 2, 3, 5, 9]) : 2
choice('A String') : n
官方文档
介绍
random.choice()函数:从给定的1维数组中随机采样的函数。
参数
numpy.random.choice(a, size=None, replace=True, p=None)
-
a: 如果是一维数组,就表示从这个一维数组中随机采样;如果是int型,就表示从0到a-1这个序列中随机采样。 -
size:采样结果的数量,默认为1.可以是整数,表示要采样的数量;也可以为tuple,如(m, n, k),则要采样的数量为m *n *k, size为(m, n, k)。 -
replace: boolean型,采样的样本是否要更换?这个地方我不太理解,测了一下发现replace指定为True时,采样的元素会有重复;当replace指定为False时,采样不会重复。 -
p: 一个一维数组,制定了a中每个元素采样的概率,若为默认的None,则a中每个元素被采样的概率相同。
注意:
replace代表的意思是抽样之后还放不放回去,如果是False的话,那么出来的三个数都不一样,如果是True的话,有可能会出现重复的,因为前面的抽的放回去了。
p中值的个数必须和a中数据的个数一致。
返回值:samples : single item or ndarray(The generated random samples)
ValueError:
If a is an int and less than zero, if a or p are not 1-dimensional, if a is an array-like of size 0, if p is not a vector of probabilities, if a and p have different lengths, or if replace=False and the sample size is greater than the population size
实例
从大小为3的np.arange(5)生成一个均匀(p=None)的随机样本:
>>> np.random.choice(5, 3)
array([0, 3, 4])
>>> #This is equivalent to np.random.randint(0,5,3)
从大小为3的np.arange(5)生成一个非均匀(p有值)的随机样本:
>>> np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0])
array([3, 3, 0])
从大小为3的np.arange(5)生成一个均匀的随机样本,没有替换(重复):
>>> np.random.choice(5, 3, replace=False)
array([3,1,0])
>>> #This is equivalent to np.random.permutation(np.arange(5))[:3]
从大小为3的np.arange(5)生成一个非均匀的随机样本,没有替换(重复):
>>> np.random.choice(5, 3, replace=False, p=[0.1, 0, 0.3, 0.6, 0])
array([2, 3, 0])
上面例子中第一个参数都可以用一个任意的数组来代替,而不仅仅是整数。例如:
>>> aa_milne_arr = ['pooh', 'rabbit', 'piglet', 'Christopher']
>>> np.random.choice(aa_milne_arr, 5, p=[0.5, 0.1, 0.1, 0.3])
array(['pooh', 'pooh', 'pooh', 'Christopher', 'piglet'],
dtype='|S11')
实际使用中,首先创建一个mask变量,然后通过mask来对需要采样的数据进行采样:
mask = np.random.choice(split_size, batch_size)
captions = data['%s_captions' % split][mask]
image_idxs = data['%s_image_idxs' % split][mask]
扩展阅读
python中choice对比(在numpy和random中均出现过)外加sample()函数对比
先看numpy中choice()
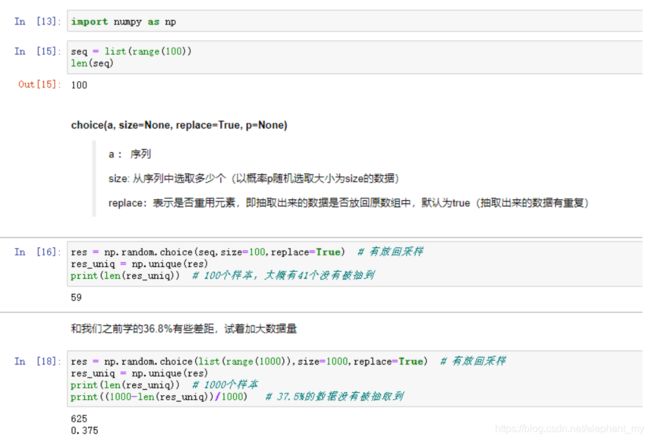
再看random中choice()和choices()

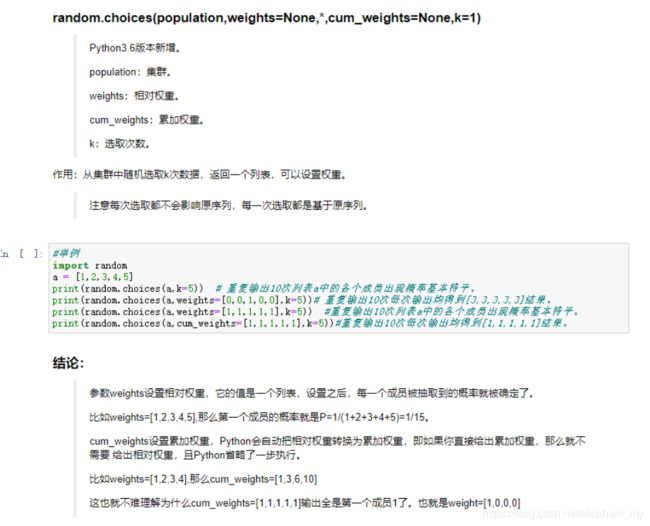
最后看下random.sample()
