numpy.random函数整合(部分)
在我们进行python数据分析的学习和应用过程中,经常需要用到numpy的随机函数,由于随机函数random的功能比较多,经常会混淆或记不住,下面由我进行一部分的总结
1.numpy.random.rand
numpy.random.rand(d1 , d2,…dn)
- rand函数创建一个给定类型的数组,将其填充在一个均匀分布的随机样本[0, 1)中。
a=np.random.rand(2,2)#shape:2*2
print(a)
[[0.22305618 0.64853825]
[0.11869553 0.72075008]]
2. numpy.random.randn()
numpy.random.randn(d1 , d2,…dn)
- randn函数返回一个或一组样本,具有标准正太分布
- dn表示每个维度
- 返回值为指定维度的array
a=np.random.randn(2,2)
print(a)
[[ 1.01707121 -1.1918371 ]
[ 0.13439038 -0.39383015]]
2.1 numpy.random.normal()
上述的randn描述的是一个标准正太分布,我需要描述非标准正太分布呢?就要运用这个normal函数了。对于numpy.random.normal函数,有三个参数(loc, scale, size),均值为 loc(mu),标准差为 scale(sigma),大小为 size 的数组。
mu=5
sigma=0.5
x = np.random.normal(mu, sigma, (2, 4))
print(x)
[[4.89826882 5.02645559 5.53955844 4.89905684]
[5.47951935 5.55261364 5.29582032 5.37455238]]
3.numpy.random.binomial()
numpy.random.binomial(n,p,size=None)
- n表示做了n重伯努利试验,这个n可以是整数型也可以是浮点型,但如果n是浮点型,在使用过程中会被截断。
- p表示一次实验成功的概率
- size为int或int元组,可选输出形状。如果给定的形状,如果size为(默认),则和均为标量时,将返回单个值。
3.1举例分析
从分布中抽取样本:投掷硬币10次的结果,测试了1000次。
n, p = 10, 0.5 # n样本数量, p每个样本的概率
size=1000
s = np.random.binomial(n, p, size)
print(np.sum(s==5)/size)
输出:
0.23
4.numpy.random.poisson()
泊松分布主要用于估计某个时间段某事件发生的概率。
泊松分布的数学式为:

numpy.random.poisson(lam=1,size=None)有两个参数
- lam表示一个单位内发生事件的平均值,函数的返回值表示一个单位内事件发生的次数。
- size表示采样的次数。
4.1举例
为发生次数2生成随机的1x10分布:
from numpy import random
x = random.poisson(lam=2, size=10)
print(x)
#输出:
[2 3 0 2 3 2 4 1 0 1]
5.numpy.random.hypergeometric()
在超几何分布中,各次实验不是独立的,各次实验成功的概率也不等。
超几何分布的数学式为:
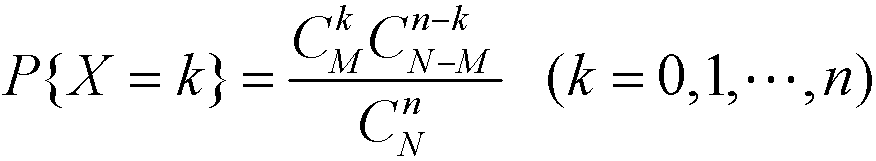
np.random.hypergeometric(ngood, nbad, nsample, size=None)有四个参数。
- ngood表示总体中代表成功的个数。
- nbad表示总数中不成功的个数。
- nsample表示抽取元素的次数(小于或等于总体样本容量)。
- size表示采样的次数。
5.1举例
【例】一共15条鱼里有7条是金鱼,抽取8条中有3条是金鱼的概率(无放回抽样)。
size = 50000
x=np.random.hypergeometric(ngood=7,nbad=15,nsample=8,size=size)
print(np.sum(x==3)/size)
#输出:
0.32696
上面是离散型随机变量,下面的是连续型随机变量。
6.numpy.random.uniform()
numpy.random.uniform(low=0.0, high=1.0, size=None) 含义为,从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high。
- low: 采样下界,float类型,默认值为0;
- high: 采样上界,float类型,默认值为1;
- size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出m *n * k个样本,缺省时输出1个值。
7.numpy.random.exponential()
指数分布用于描述直到下一个事件的时间,例如 失败/成功等
它有两个参数:
- scale为lambda的倒数,默认为1.0。
- size表示采样的次数。
其他随机函数
8. numpy.random.choice()
处理数据时经常需要从数组中随机抽取元素,这时候就需要用到np.random.choice()。然而choice用法的官方解释并不详细,尤其是对replace参数的解释,例子也不是很全面。我将通过下面的几个例子来说明choice()函数的用法。
8.1 举例说明
8.1.1产生随机数
np.random.choice(5)#从[0, 5)中随机输出一个随机数
#相当于np.random.randint(0, 5)
np.random.choice(5, 3)#在[0, 5)内输出五个数字并组成一维数组(ndarray)
#相当于np.random.randint(0, 5, 3)
而且可以从数组、列表或者元组中随机抽取,当然还有一个值得注意的地方,不管是什么类型,它必须是一维的!!!!
比如
A0 = np.arange(15).reshape(5, 3)
np.random.choice(A0, 5)#如果是二维数组,会报错
ValueError: 'a' must be 1-dimensional
8.1.2参数replace
用来设置是否可以取相同元素:True表示可以取相同数字;False表示不可以取相同数字。默认是True。
np.random.choice(5, 6, replace=True)#可以看到有相同元素
array([3, 4, 1, 1, 0, 3])
np.random.choice(5, 6, replace=False)#会报错,因为五个数字中取六个,不可能不取到重复的数字
ValueError: Cannot take a larger sample than population when 'replace=False'
8.1.3参数p
p实际是个数组,大小应该与指定的a相同,用来规定选取a中每个元素的概率,默认为概率相同。
9.numpy.random.shuffle()
shuffle直接在原来的数组上进行操作,改变原来数组的顺序,无返回值(是对列表x中的所有元素随机打乱顺序,若x不是列表,则报错)。
import numpy as np
arr = np.arange(5)
np.random.shuffle(arr)
print(arr)
# 输出:[4 3 0 2 1]
多维矩阵中,只对第一维(行)做打乱顺序操作:
arr = np.arange(9).reshape((3, 3))
np.random.shuffle(arr)
print(arr)
array([[3, 4, 5],
[6, 7, 8],
[0, 1, 2]])
10.numpy.random.permutation()
random.permutation()与random.shuffle()效果相同,可以打乱第0轴的数据,但是它不会改变原来的数组。
结语
感谢大家浏览,也希望大家批评指正。