论文解读 TOOD: Task-aligned One-stage Object Detection

github: https://github.com/fcjian/TOOD
paper: https://arxiv.org/pdf/2108.07755.pdf
关键点
思考起点
指出传统one-stage算法在在优化目标分类和定位问题中的不足(DecoupledHead分离了分类任务和回归任务[yolox表示解耦这是优点,yolo1-5都是使用yolohead统一输出位置和置信度]),最佳分类点与最佳位置回归点可能不一样。具体如下图所示,这种情况下正常的nms会选出高score的点,抑制低score的精准锚框。

解决方案
设计出Task-aligned One-stage Object Detection(TOOD),提出任务对齐头部(T-Head)和任务对齐学习(TAL)。T-head在学习任务交互特征和任务特定特征之间提供了更好的平衡,并通过任务对齐预测器学习对齐的灵活性提高,TAL通过设计的样本分配方案和任务对齐损失,明确地拉近(甚至统一)两个任务的最优锚点
T-head:其主干部分设计了channel attention,对输入进行channel进行调整(使区分出P[分类概率]和B[box尺寸]),然后使用sigmoid_conv(两个分支)初步预测数P和B;在主干支路上再使用类似channel attention的gap_sigmoid_conv得到B的偏移量O,P的偏移量M,计算O|M更新B与P,使这两个的最优质值逐步靠近。
TAL:包含任务对齐指标、正样本选择标准,并将任务对齐指标与原先的的分类损失、回归损失进行联立[其本质就是根据任务对齐指标调节不同样本在反向传播时loss的权重]。
- 定义了任务对齐指标 t = s α × u β t=s^{\alpha} \times u^{\beta} t=sα×uβ,其中s指score,u指iou;
- 定义了正样本选择标准 选择m个t值最大的的锚点做正样本(有点类似于simOTA);
- 定义了新的分类损失 将任务对齐指标融入BCE loss中;先对t进行归一化,然后设计为类focal的格式
L c l s = ∑ i = 1 N pos ∣ t ^ i − s i ∣ γ B C E ( s i , t ^ i ) + ∑ j = 1 N neg s j γ BCE ( s j , 0 ) L_{c l s}=\sum_{i=1}^{N_{\text {pos }}}\left|\hat{t}_{i}-s_{i}\right|^{\gamma} B C E\left(s_{i}, \hat{t}_{i}\right)+\sum_{j=1}^{N_{\text {neg }}} s_{j}^{\gamma} \operatorname{BCE}\left(s_{j}, 0\right) Lcls=∑i=1Npos t^i−si γBCE(si,t^i)+∑j=1Nneg sjγBCE(sj,0) - 定义了新的回归损失 将任务对齐指标融入GIOU loss中;先对t进行归一化,然后与GIOU相乘
L r e g = ∑ i = 1 N pos t ^ i L G I o U ( b i , b i ‾ ) L_{r e g}=\sum_{i=1}^{N_{\text {pos }}} \hat{t}_{i} L_{G I o U}\left(b_{i}, \overline{b_{i}}\right) Lreg=∑i=1Npos t^iLGIoU(bi,bi)
摘要
One-stage目标检测通常是通过优化目标分类和定位两个子任务来实现的,使用具有两个并行分支的头部,这可能导致两个任务之间的预测存在一定程度的空间错位。在这项工作中,我们提出了一个任务对齐的单阶段对象检测(TOOD),它以基于学习的方式明确地对齐了两个任务。首先,我们设计了一种新的任务对齐头部(T-Head),它在学习任务交互特征和任务特定特征之间提供了更好的平衡,并通过任务对齐预测器学习对齐的灵活性提高。其次,我们提出了任务对齐学习(TAL),通过设计的样本分配方案和任务对齐损失,明确地拉近(甚至统一)两个任务的最优锚点。在MS-COCO上进行了广泛的实验,其中TOOD在单模型单尺度测试中实现了51.1 AP。这在很大程度上超过了最近的单级探测器,如ATSS [31](47.7 AP)、GFL [14](48.2 AP)和PAA [9](49.0 AP),其参数和FLOPs更少。定性结果也证明了TOOD在更好地对齐对象分类和定位任务方面的有效性。代码在:https://github.com/fcjian/TOOD.
1. Introduction
目标检测是指从自然图像中定位和识别感兴趣的目标,是计算机视觉中一项基本但具有挑战性的任务。通过联合优化目标分类和定位[4,6,7,16,22,33],它通常被表述为一个多任务学习问题。分类任务旨在学习专注于物体的关键或显著部分的区别特征,而定位任务则是为了精确地定位整个对象及其边界。由于分类和定位的学习机制不同,两个任务的学习特征的空间分布可能会不同,当使用两个独立的分支进行预测时,会导致一定程度的错位。
最近的One-stage目标探测器试图通过关注目标[3,10,27,31]的中心来预测两个独立任务的一致输出。他们假设物体中心的锚(即无锚检测器的anchor-point,或基于锚的检测器的anchor-box)可能对分类和定位给出更准确的预测。例如,最近的FCOS [27]和ATSS [31]都使用了中心性分支提高目标中心附近的锚点预测的分类得分,并为相应锚的定位损失分配更大的权重。此外,FoveaBox [10]将物体预定义的中心区域内的锚点视为阳性样本。这种启发式设计已经取得了良好的结果,但这些方法可能有两个局限性:
(1) Independence of classification and localization. 最近的One-stage检测器通过并行使用两个独立的分支(即头部)来独立地执行对象分类和定位。这种双分支设计可能会导致两个任务之间缺乏交互,导致执行任务时预测不一致。如图1中的“Result”列所示,ATSS检测器识别一个“餐桌”的对象(用红色斑块表示锚点),结果定位到了“披萨”上(红色边界框)。
(2) Task-agnostic sample assignment. 大多数无锚检测器使用基于几何的分配方案来选择对象中心附近的锚点来进行分类和定位[3,10,31],而基于锚的检测器通常通过计算锚盒和GT[22,23,31]之间的IoUs来分配锚盒。然而,用于分类和定位的最佳锚点往往是不一致的,并且可能根据物体的形状和特征而有很大的差异。通用的样本分配方案是任务无关的,因此可能很难对这两个任务做出准确而一致的预测,如图1中ATSS的“Score”和“IoU”分布所示。“Result”列还说明了最佳定位锚(绿色斑块)的空间位置可能不在对象的中心,并且它与最佳分类化锚(红色斑块)不能很好地对齐。因此,在非最大抑制(NMS)期间,一个精确的边界框可能会被一个较不精确的边界框所抑制。
为了解决这些限制,我们提出了一种任务对齐的单阶段对象检测(TOOD),旨在通过设计一种新的面向对齐的头部结构的学习方法来更准确地对齐两个任务:
Task-aligned head. 与传统的单阶段目标检测中分类和定位分别使用两个分支并行实现不同,我们设计了一个任务对齐的头部(T-head)来增强两个任务之间的交互。这使得这两个任务更容易协作,从而更准确地使他们的预测保持一致。T-head在概念上很简单:它计算任务交互式特征,并通过一种新的任务对齐预测器(TAP)进行预测。然后,它根据任务对齐学习提供的学习信号,对齐两个预测的空间分布。
Task alignment learning. 为了进一步克服错位问题,我们提出了一个任务对齐学习(TAL)来明确地拉近这两个任务的最优锚点。它是通过设计一个样本分配方案和一个任务对齐的损失来实现的。样本分配通过计算每个锚点上的任务对齐程度来收集训练样本(即正或负),而任务对齐的损失逐渐统一了在训练过程中预测分类和定位的最佳锚点。因此,在推理时,可以保留一个分类得分最高并共同具有最精确定位的边界框。
所提出的T-head和学习策略可以在分类和定位方面协同做出高质量的预测。这项工作的主要贡献可以总结如下: (1)我们设计了一个新的T-head,同时保持分类和定位的特性,并进一步调整两个任务的预测;(2)我们提出TAL明确地对齐两个任务在确定的任务对齐锚点,并为提出的预测器提供学习信号;(3)我们在MSCOCO [17]上进行了广泛的实验,我们的TOOD实现了51.1 AP,大大超过了最近的一期探测器,如ATSS [31],GFL [14]和PAA [9]。定性结果进一步验证了我们的任务协调方法的有效性。
2. Related Work
One-stage detectors. OverFeat [25]是最早的基于cnn的单级探测器之一。随后,YOLO [22]被提出,用于直接预测边界框和分类分数,它不需要一个额外的阶段来生成区域建议。SSD [18]引入了具有来自多层卷积特征的多尺度预测的锚点,并提出了焦点损失[16]来解决RetinaNet等单级检测器的类不平衡问题。基于关键点的检测方法,如[3,11,34],通过识别和分组一个边界框中的多个关键点来解决检测问题。最近,FCOS [27]和FoveaBox [10]被开发出来,通过锚点和点到边界的距离来定位感兴趣的对象。大多数主流的单阶段检测器都是由两个基于FCN的分支组成,用于分类和定位,这可能会导致两个任务之间的错位。在本文中,我们通过一种新的头部结构和一种面向对齐的学习方法来增强这两个任务之间的对齐。
Training sample assignment. 大多数基于锚框的检测器,如[22,31],通过计算预测框和GT之间的IoU来生成正样本,而无锚检测器将物体中心区域内的锚点视为正样本[3,10,27]。为了更有效地训练检测器,最近的研究试图通过使用输出结果收集信息更丰富的训练样本。例如,FSAF [36]根据计算出的损失从特征金字塔中选择有意义的样本,类似地,SAPD [35]通过设计一个元选择网络,提供了FSAF的软选择版本。FreeAnchor[32]和MAL [8]通过计算损失来确定最佳锚盒,以努力改善锚和物体之间的匹配。PAA [9]通过拟合锚点分数的概率分布,自适应地将锚定划分为正样本和负样本。Mutual Guidance[29]通过考虑对另一个任务的预测质量,改进了对其中一个任务的锚定分配。与正/负样本分配不同,PISA [1]根据输出的精度秩对训练样本进行重加权。Noisy Anchor[12]为训练样本分配软标签,并使用清洁度评分重新对锚盒进行加权,以减轻二进制标签产生的噪声。GFL [14]用IoU评分替换二进制分类标签,将定位质量整合到分类化中。这些优秀的方法激发了当前的工作,从任务对齐的角度开发一种新的分配机制。
3. Task-aligned One-stage Object Detection
概述 类似于最近的一级探测器,如[14,31],所提出的TOOD有一个“backbone-FPN-head”的整体结构。此外,考虑到高效和简洁,TOOD在每个位置使用单个锚框(与ATSS[31]相同,其中“锚”指无锚检测器的锚点,或基于锚的检测器的锚盒)。如前所述,现有的任务检测器存在分类和定位之间的任务失调,这通常使用两个独立的头部分支来实现。在这项工作中,我们建议使用所设计的与任务对齐的头部(T-head)和一个新的任务对齐学习(TAL)来更明确地对齐这两个任务。如图2所示,T-head和TAL可以协同改进两个任务的对齐方式。具体来说,T-head首先对FPN特征的分类和定位进行预测。然后TAL基于一种新的任务对齐度量计算任务对齐信号,它度量两个预测之间的对齐程度。最后,T-head利用在反向传播过程中从TAL计算出的学习信号,自动调整其分类概率和定位预测。
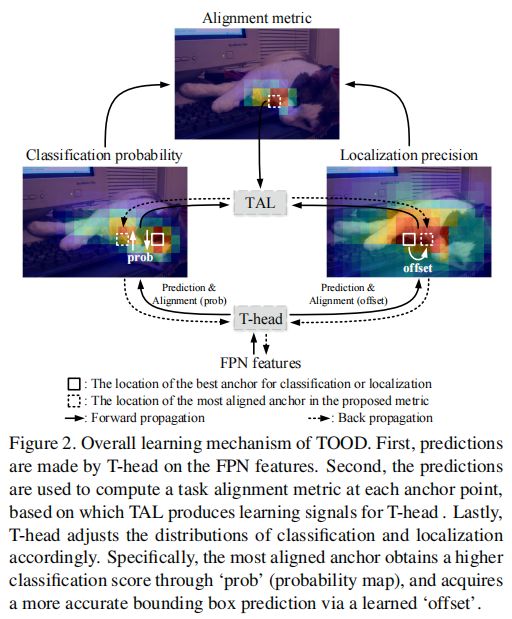
3.1. Task-aligned Head
我们的目标是设计一个高效的头部结构,以改进在单级检测器中的传统头部设计(如图3(a)所示)。在这项工作中,我们通过考虑两个方面来实现这一点: (1)增加两个任务之间的交互作用,以及(2)提高探测器学习对齐的能力。建议的T-head如图3(b)所示,其中它有一个简单的特征提取器和两个任务对齐预测器(TAP)。

为了增强分类和定位之间的交互作用,我们使用特征提取器从多个卷积层中学习task-interactive特征堆栈,如图3(b)中的蓝色部分所示,这种设计不仅促进了任务的交互,而且为两个任务在多尺度感受野上提供了多尺度特征。公式上,让 X f p n ∈ R H × W × C X^{fpn}∈R^{H×W×C} Xfpn∈RH×W×C表示FPN特征,其中H、W和C分别表示通道的高度、宽度和通道的数量。特征提取器使用N个连续的具有激活函数的conv层来计算task-interactive特征:
X k inter = { δ ( conv k ( X f p n ) ) , k = 1 δ ( conv k ( X k − 1 inter ) ) , k > 1 , ∀ k ∈ { 1 , 2 , … , N } (1) X_{k}^{\text {inter }}=\left\{\begin{array}{l} \delta\left(\operatorname{conv}_{k}\left(X^{f p n}\right)\right), k=1 \\ \delta\left(\operatorname{conv}_{k}\left(X_{k-1}^{\text {inter }}\right)\right), k>1 \end{array}, \forall k \in\{1,2, \ldots, N\}\right. \tag{1} Xkinter ={δ(convk(Xfpn)),k=1δ(convk(Xk−1inter )),k>1,∀k∈{1,2,…,N}(1)
其中, conv k \operatorname{conv}_{k} convk和 δ \delta δ分别表示第k个conv层和relu函数。因此,我们使用头部的单个分支从FPN特征中提取出丰富的多尺度特征。然后,将计算出的任务交互特征输入两个TAP,进行对齐分类和定位。
Task-aligned Predictor (TAP). 我们对计算出的任务交互特征进行对象分类和定位,其中这两个任务可以很好地感知彼此的状态。然而,由于单分支设计,任务交互特征不可避免地会在两个不同任务之间引入一定程度的特征冲突,这在[26,28]中有讨论。直观地看,对象分类和定位的任务有不同的目标,因此专注于不同类型的特征(例如,不同的层次或接受域)。因此,我们提出了一种层注意机制,通过在层级动态计算这些任务特定的特征来鼓励任务分解。如图3©所示,对每个分类或定位任务分别计算任务特定的特征:
X k task = w k ⋅ X k inter , ∀ k ∈ { 1 , 2 , … , N } (2) X_{k}^{\text {task }}=\boldsymbol{w}_{k} \cdot X_{k}^{\text {inter }}, \forall k \in\{1,2, \ldots, N\} \tag{2} Xktask =wk⋅Xkinter ,∀k∈{1,2,…,N}(2)
其中 w k w_k wk是学习层注意的第k个元素。W是从跨层的任务交互特性中计算出来的,并且能够捕获各层之间的依赖关系:
w = σ ( f c 2 ( δ ( f c 1 ( x inter ) ) ) ) (3) \boldsymbol{w}=\sigma\left(f c_{2}\left(\delta\left(f c_{1}\left(\boldsymbol{x}^{\text {inter }}\right)\right)\right)\right) \tag{3} w=σ(fc2(δ(fc1(xinter ))))(3)
其中,fc1和fc2为两个完全连接的层。σ是一个sigmoid函数, x i n t e r x^{inter} xinter是通过对 X i n t e r X^{inter} Xinter应用平均池化得到的,这是 X k i n t e r X^{inter}_k Xkinter的连接特征。最后,从每个 X t a s k X^{task} Xtask中预测分类或定位的结果:
Z task = conv 2 ( δ ( conv 1 ( X task ) ) ) (4) Z^{\text {task }}=\operatorname{conv}_{2}\left(\delta\left(\operatorname{conv}_{1}\left(X^{\text {task }}\right)\right)\right) \tag{4} Ztask =conv2(δ(conv1(Xtask )))(4)
其中, X t a s k X^{task} Xtask是 X k t a s k X^{task}_k Xktask的连接特征,conv1是一个1×1的conv降维层。然后使用sigmoid函数将 Z t a s k Z^{task} Ztask转换为分类分数 P ∈ R H × W × 80 P∈R^{H×W×80} P∈RH×W×80,或使用[27,31]中应用的 distance-to-bbox转换为对象边界框 B ∈ R H × W × 4 B∈R^{H×W×4} B∈RH×W×4
Prediction alignment. 在预测步骤,我们通过调整两个的空间分布预测:P和B,进一步对齐两个任务。不同于之前的工作使用centerness分支[27]或IOU分支[9]只能基于分类特征或定位调整分类预测。我们通过使用计算出的task-interactive特征来共同考虑这两个任务来对齐这两个预测。值得注意的是,我们在这两个任务上分别执行对齐方法。如图3©所示,我们使用空间概率图 M ∈ R H × W × 1 M∈R^{H×W×1} M∈RH×W×1来调整分类预测
P a l i g n = P × M (5) P^{a l i g n}=\sqrt{P \times M} \tag{5} Palign=P×M(5)
其中M是从交互特征计算出来的,它在每个空间位置学习两个任务之间一定程度的一致性。
同时,为了对定位预测进行对齐,我们从交互特征中进一步学习空间偏移图 O ∈ R H × W × 8 O∈R^{H×W×8} O∈RH×W×8,用于调整每个位置的预测边界框。具体来说,学习到的空间偏移量使最对齐的锚点能够识别其周围的最佳边界预测:
B align ( i , j , c ) = B ( i + O ( i , j , 2 × c ) , j + O ( i , j , 2 × c + 1 ) , c ) (6) B^{\text {align }}(i, j, c)=B(i+O(i, j, 2 \times c), j+O(i, j, 2 \times c+1), c) \tag{6} Balign (i,j,c)=B(i+O(i,j,2×c),j+O(i,j,2×c+1),c)(6)
其中,下标(i,j,c)表示张量中第c通道处的(i,j)个空间位置。公式(6)采用双线性插值实现,由于B的chanel维度很小,其计算开销可以忽略不计。值得注意的是,每个chanel的偏移量都是独立学习的,这意味着对象的每个边界都有自己的学习偏移量。这允许对四个边界进行更准确的预测,因为每个边界都可以分别从其附近最精确的锚点学习。因此,我们的方法不仅对两个任务进行对齐,而且通过识别每边精确的锚点来提高定位精度。
对齐映射M和O是自动从交互特征堆栈中学习出来的:
M = σ ( conv 2 ( δ ( conv 1 ( X inter ) ) ) ) (7) M=\sigma\left(\operatorname{conv}_{2}\left(\delta\left(\operatorname{conv}_{1}\left(X^{\text {inter }}\right)\right)\right)\right) \tag{7} M=σ(conv2(δ(conv1(Xinter ))))(7) O = conv 4 ( δ ( conv 3 ( X inter ) ) ) (8) O=\operatorname{conv}_{4}\left(\delta\left(\operatorname{conv}_{3}\left(X^{\text {inter }}\right)\right)\right) \tag{8} O=conv4(δ(conv3(Xinter )))(8)
其中conv1和conv3是两个用于降维的1×1conv。M和O的学习是通过使用提出的任务对齐学习(TAL)来完成的。请注意,我们的T-head是一个独立的模块,没有TAL也可以很好地工作。它可以很容易地即插即用地应用于各种单级目标检测器,以提高检测性能。
3.2. Task Alignment Learning
我们进一步介绍了一个任务对齐学习(TAL),它进一步指导我们的T-head做出任务对齐的预测。TAL与以往的方法[1,8,9,12,14,29,32]有两个方面的不同。首先,从任务对齐的角度来看,它基于设计的度量,动态地选择高质量的锚点。其次,它同时考虑锚点分配和权重。它包括一个样本分配策略和专门为调整这两个任务而设计的新损失。
3.2.1 Task-aligned Sample Assignment
为了应对NMS,训练实例的锚框分配应满足以下规则:
- (1)排列良好的锚定应能够通过精确定位联合预测较高的分类分数;
- (2)错位的锚应具有较低的分类分数,随后被抑制。
对于这两个目标,我们设计了一个新的锚对齐度量来明确地度量anchor级别上的任务对齐程度。对齐度量被集成到样本分配和损失函数中,以动态地细化每个锚点上的预测。
Anchor alignment metric. 考虑到预测的边界框和GT之间的分类得分和IoU表明了两个任务的预测质量,我们使用分类得分和IoU的高阶组合来衡量任务对齐的程度。具体来说,我们设计了以下度量标准来计算每个实例的锚定级对齐:
t = s α × u β (9) t=s^{\alpha} \times u^{\beta} \tag{9} t=sα×uβ(9)
其中s表示分类分数,u表示iou,${\alpha} \text{和} {\beta} $用于控制Anchor alignment metric中两个任务的对齐程度。值得注意的是,t在两个任务的联合优化任务对齐的目标中起着至关重要的作用。它鼓励网络从联合优化的角度动态地关注高质量(即任务)锚点。
Training sample assignment. 正如在[31,32]中所讨论的,训练样本分配对于目标检测器的训练是至关重要的。为了改进两个任务的对齐,我们关注任务对齐的锚点,并采用简单的分配规则来选择训练样本:对于每个实例,我们选择t值最大的m个锚点作为正样本,而其余的锚点作为负样本。同样,训练是通过计算专门为调整分类和定位任务而设计的新的损失函数来实现的。
3.2.2 Task-aligned Loss
Classification objective. 为了明确地增加对齐锚的分类分数,同时,减少不对齐锚的分数(即,有一个小的t),我们在训练期间使用t来替换一个正锚的二进制标签。然而,我们发现,随着α和β的增加,当正锚点的标签(即t)变得较小时,网络不能收敛。因此,我们使用一个归一化t,即tˆ,来替换正锚的二进制标签,其中tˆ通过以下两个属性进行归一化:
- (1)确保硬实例的有效学习(通常对所有对应的正锚都有一个小的t);
- (2)基于预测边界盒的精度保持实例之间的秩。
因此,我们采用一个简单的实例级归一化来调整tˆ的规模:tˆ的最大值等于每个实例内的最大IoU值(u)。然后,在分类任务的正锚点上计算出的Binary Cross Entropy(BCE)可以重写为:
L c l − pos = ∑ i = 1 N pos B C E ( s i , t ^ i ) (10) L_{c l_{-} \text {pos }}=\sum_{i=1}^{N_{\text {pos }}} B C E\left(s_{i}, \hat{t}_{i}\right) \tag{10} Lcl−pos =i=1∑Npos BCE(si,t^i)(10)
其中,i表示与一个实例对应的 N p o s N_{pos} Npos正锚中的第i个锚。在[16]之后,我们采用focal loss进行分类,以减轻训练过程中负样本和正样本之间的不平衡。在正锚点上计算的焦点损失可以用等式重新计算(10),该分类任务的最终损失函数定义如下:
L c l s = ∑ i = 1 N pos ∣ t ^ i − s i ∣ γ B C E ( s i , t ^ i ) + ∑ j = 1 N neg s j γ BCE ( s j , 0 ) (11) L_{c l s}=\sum_{i=1}^{N_{\text {pos }}}\left|\hat{t}_{i}-s_{i}\right|^{\gamma} B C E\left(s_{i}, \hat{t}_{i}\right)+\sum_{j=1}^{N_{\text {neg }}} s_{j}^{\gamma} \operatorname{BCE}\left(s_{j}, 0\right) \tag{11} Lcls=i=1∑Npos t^i−si γBCE(si,t^i)+j=1∑Nneg sjγBCE(sj,0)(11)
其中j为 N n e g N_{neg} Nneg负锚的第j个锚,γ为focusing参数。
Localization objective. 一个对齐良好的锚(即大t)预测的边界框通常具有大的分类分数和精确的定位,这样的边界框更有可能在NMS期间被保留。此外,t还可以通过更仔细地加权损失来选择高质量的边界框,以提高训练水平。正如在[21]中所讨论的,从高质量的边界框中学习有利于模型的性能,而低质量的边界框往往会产生大量信息较少和冗余的信号来更新模型,从而对训练产生负面影响。在我们的例子中,我们应用t值来测量边界框的质量。因此,我们通过关注良好对齐的锚点(大t)来提高任务对齐和回归精度,同时减少在边界框回归过程中不对齐的锚点(有一个小的t)的影响。与分类目标类似,我们基于tˆ对每个锚点计算的边界盒回归损失进行重新加权,一个GIoU损失(LGIoU)[24]可以重新表述如下:
L r e g = ∑ i = 1 N pos t ^ i L G I o U ( b i , b i ‾ ) L_{r e g}=\sum_{i=1}^{N_{\text {pos }}} \hat{t}_{i} L_{G I o U}\left(b_{i}, \overline{b_{i}}\right) Lreg=i=1∑Npos t^iLGIoU(bi,bi)
其中b和¯b表示预测的边界框和相应的地面真实框。TAL的总训练损失是Lcls和Lreg的总和。
4. Experiments and Results
Dataset and evaluation protocol. 所有实验均在大规模检测基准MSCOCO 2017 [17]上实现。按照[15,16]的标准实践,我们使用trainval135k集(115K图像)进行训练和使用小训练集(5K图像)作为我们的消融研究的验证。我们报告了我们在测试开发集上的主要结果,以便与最先进的探测器进行比较。该性能由COCO平均精度(AP)[17]来测量。
Implementation details. 与大多数单级探测器[10,16,27]一样,我们使用“backbone-FPN-head”的检测管道,具有不同的骨干,包括在ImageNet[2]上预训练的ResNet-50、ResNet-101和ResNeXt-101-64×4d。与ATSS [31]类似,TOOD在每个位置上设置一个锚。除非特别说明,我们报告一个anchor-free的TOOD(基于锚的TOOD可以实现类似于表3所示的性能)的实验结果。交互层数N设置为6,使T头具有与传统平行头相似的参数数,focal参数γ设置为[14,16]中使用的2。更多的实验细节详见补充材料。
4.1. Ablation Study
对于消融研究,我们使用ResNet-50主干,并对模型进行12个epoch的训练,除非有特别说明。性能报告在COCO minival集。
On head structures 我们将表1中我们的T-head与传统的平行头进行了比较。它可以在各种即插即用的单级检测器中采用,并在更少的参数和FLOPs下,始终比传统的Parallel head高出0.7到1.9 AP。这验证了我们设计的有效性,并证明了T-head通过引入任务交互和预测对齐,可以更有效地以更高的性能工作。

On sample assignments. 为了证明TAL的有效性,我们将TAL与其他使用不同样本分配方法的学习方法进行了比较,如表2所示。训练样本分配根据是否为基于学习的方法,可以分为固定分配和自适应分配。与现有的分配方法不同,TAL自适应地分配正锚点和负锚点,同时更仔细地计算正锚点的权重,从而获得更高的性能。与PAA(+IoU pred.)进行比较。它有一个额外的预测结构,我们将TAP合并进了TAL,使AP更高为42.5。在补充材料中进一步的描述了实验细节。

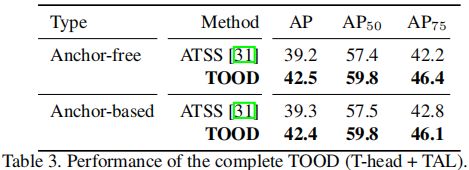
TOOD 我们评估了完整的TOOD(T-head + TAL)的性能。如表3所示,无锚框的TOOD和基于锚框的TOOD可以达到类似的性能,即42.5 AP和42.4 AP。与ATSS相比,TOOD提高了∼3.2AP的性能。更具体地说,AP75的改进是显著的,这使得TOOD中的∼高3.8个点。这验证了对齐这两个任务可以提高检测性能。值得注意的是,TOOD比T-head+ATSS(T-head+1.9AP)和平行头+ TAL(+1.1 AP)带来了更高的改进(+3.3 AP),如表6所示。这表明Thead和TAL可以强烈地相互补偿。
On hyper-parameters. 我们首先使用不同的α和β值来研究TAL的性能,它们通过t来控制分类置信度和定位精度对anchor对齐度量的影响。通过表4所示的粗搜索,我们采用了α=1和β=6。然后我们进行了一些实验来研究超参数m的稳健性,超参数m用于选择正锚。我们在[5,9,13,17,21]中使用了不同的m值,并在42.0∼42.5AP的范围内得到了结果,这表明性能对m不敏感(按t值排序,top m个预测框作为正样本)。因此,我们在所有的实验中都采用了m = 13。

4.2. Comparison with the State-of-the-Art
我们将我们的TOOD与表5中其他one-stage探测器在COCO test-dev上进行了比较。模型采用尺度抖动(480-800)和2个×学习计划(24个epoch)进行训练。为了进行公平的比较,我们报告了单模型和单尺度测试的结果。使用ResNet-101和ResNeXt-101-64×4d,TOOD实现了46.7 AP和48.3 AP,超过了目前的one-stage探测器,如ATSS[31](∼3AP)和GFL[14](∼2AP)。此外,ResNet-101-DCN和ResNeXt-101-64×4d-DCN与其他探测器相比,TOOD带来了更大的改进。例如,它获得了2.8AP(48.3→51.1AP)的改进,而ATSS有2.1AP(45.6→47.7AP)的改进。这验证了TOOD可以通过自适应地调整与可学习卷积网络(DCN)[37]更有效地合作,通过学习特征的空间分布进行任务对齐。请注意,在TOOD中,DCN应用于T-head的前两层。如表5所示,TOOD在一期目标检测中使用51.1 AP获得了一个新的最先进的结果。

4.3. Quantitative Analysis for Task-alignment
我们定量地分析了所提出的方法对两个任务对齐的影响。在没有NMS的情况下,我们通过为每个实例的前50个自信预测,计算分类和定位排名[20]之间的皮尔逊相关系数(PCC),以及前10个自信预测的平均IoU。如表6所示,使用T-head和TAL改善了平均PCC和IoU。同时,在NMS中,使用T-head和TAL时,正确的盒数(IoU>=0.5)数量增加,而冗余盒(IoU>=0.5)和错误盒(0.1
5. Conclusion
在这项工作中,我们说明了在现有的one-stage检测器中分类和定位之间的错位,并提出了TOOD来对齐这两个任务。特别是,我们设计了一个任务对齐的头部来增强两个任务的交互作用,然后提高其学习对齐的能力。此外,通过引入样本分配方案和新的损失函数,提出了一种新的任务对齐学习策略,两者都是通过锚对齐度量计算的。通过这些改进,TOOD在MS-COCO上实现了51.1 AP,大大超过了最先进的单级探测器。
Supplementary material
1. Implementation details
在本节中,我们将更详细地描述网络优化和推理的过程。
Optimization 我们的实现是基于MMdetection[2]和Pytorch [7]。使用主干ResNet-50的模型使用4个GPU和每个GPU的4个小批进行训练,而其他的模型使用8个GPU和每个GPU的2个小批进行训练。我们使用了随机梯度下降(SGD)优化器,其权重衰减为0.0001,动量为0.9。除非具体说明,模型被训练为12个epochs(1个×学习计划),初始学习率被设置为0.01,然后在第8个epochs和第11个epoch减少10倍。输入图像的大小被调整为有一个较短的边为800,而较长的边保持在小于1333以内。具体来说,如果一个锚被分配给多个对象的正样本,我们只将这个锚分配给具有最小面积的对象。对于与最先进的检测器进行比较的实验,我们训练模型在24个epochs下训练并设置了尺度抖动。
Inference 推理阶段与ATSS [9]的推理阶段相同。也就是说,我们以与训练阶段相同的方式调整输入图像的大小(即将较短的一侧调整到800,而较长的一侧保持小于1333),然后将其通过检测网络的forword,获得具有预测类的预测边界盒。然后,我们使用0.05的置信度阈值来过滤掉低置信度的预测,然后从每个特征金字塔中选择前1000个评分框。最后,我们采用非最大抑制(NMS),每个类的IoU阈值为0.6,以生成每幅图像最终的前100个可信预测。
2. Discussion
Differences between TAL and previous works. 如前所述,所提出的TAL是一种基于学习的锚点选择和加权方法。在这里,我们讨论了我们的TAL和最近的几种方法在锚点选择和加权方面的差异。如本文所述,自适应方法可分为两类: (1)正/负锚集合,如FreeAnchor[10]、PAA [4]和Mutual Guidance[8];(2)锚权重,如PISA [1]、NoisyAnchor [5]和GFL[6](例如,通过修改损失函数)。这些方法自适应地执行锚收集或锚加权。
我们建议TAL同时考虑这两个方面,允许它更准确地测量信息丰富或高质量的锚点。具体来说,TAL被设计为从任务对齐的角度动态收集正/负锚,并根据每个位置的任务对齐程度进一步仔细地加权正锚。与当前的分配方法如ATSS [6]和PAA [4]首先选择一组候选锚基于单位得分,然后分析锚的分布特征分配样本,目标的设计更简单但更有效的直接分配样本基于提出的对齐指标。
特别是,最近的Mutual Guidance[8]通过根据预定义的锚和对另一个任务的预测质量为一个任务分配正/负锚来解决任务-错位问题。与Mutual Guidance不同的是,TAL基于两个任务之间的对齐方式为每个任务分配正/负锚,并且完全独立于预定义的锚。此外,GFL [6]试图在ATSS的基础上,通过用IoU分数替换二进制分类标签来对齐任务。TAL与GFL不同,通过使用所提出的任务对齐度量来设计样本分配和锚定权重,这允许它显式地学习以协调的方式细化分类和定位。