深度学习之 RPN(RegionProposal Network)- 区域候选网络
anchor boxes基本概念与作用:
feature map 上的一个点可以映射回输入图片上的一个点,以特征图上这个点为中心,预先人为设定 k 个 boxes,这些 boxes 就称为在这个点上生成的 k 个 anchor boxes(所有anchor boxes的中心点坐标是一样的)。一个 m ∗ n m*n m∗n 的特征图就有 m ∗ n ∗ k m*n*k m∗n∗k 个 anchor boxes。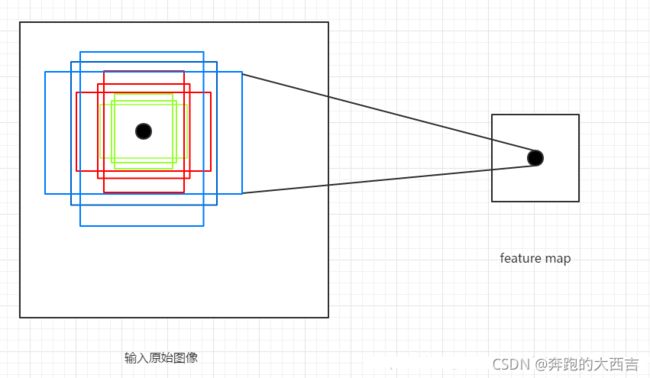
anchor boxes 的作用是将 boxes 传给 RPN, 让 RPN 判断其中哪些 anchor boxes 可能存在目标,并进一步回归坐标,得到 proposals 输给后面的网络。模型回归的目标是真实 boxes 与 anchor boxes 之间坐标的偏置。将偏置和 anchor boxes 的坐标带入预先设定的公式中,就得到了最终预测的boxes坐标。
RPN
RPN的本质是 “ 基于滑窗的无类别obejct检测器 ”。
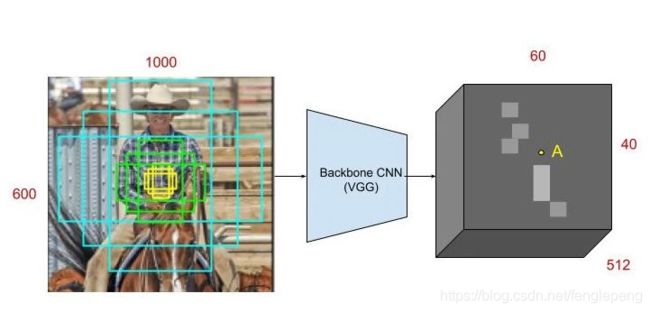
对于提取候选框最常用的 SelectiveSearch 方法,提取一副图像大概需要2s的时间,改进的 EdgeBoxes 算法将效率提高到了0.2s,但是这还不够。候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设,MSRA的任少卿等人提出RPN(RegionProposal Network, 区域候选网络),完美解决了这个问题,它的主要功能是生成区域候选(Region Proposal)(可以看做是许多潜在的边界框,也叫 anchor,它是包含4个坐标的矩形框),如上所示。
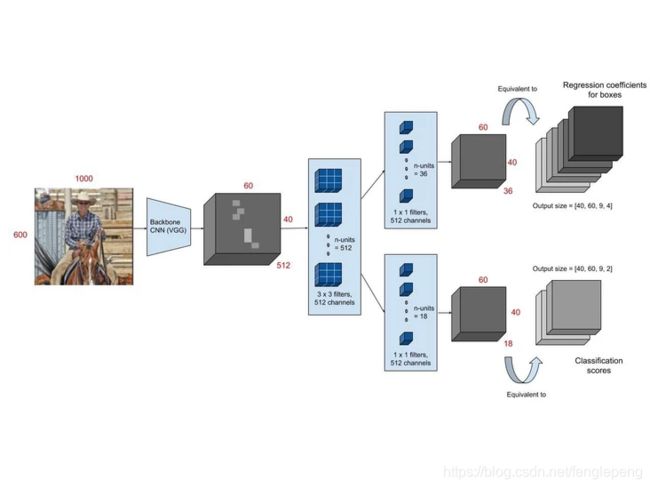
RPN简单来说就是:假设输入一张图片,经过前面骨干网络的一系列的卷积或者池化之后之后,得到一个尺寸 m ∗ n m*n m∗n 的特征图(暂且不说通道),对应将原图划分为 m ∗ n m*n m∗n 个区域,原图的每个区域的中心由这个特征图上的一个像素点坐标表示。通过anchor机制,可以在每个像素点对应原图的区域生成k个可能存在目标的候选框(称为anchor box),如上图所示(k=9)。RPN就是用来判断每个像素点对应的k个区域是不是包含目标,如果包含(那么先根据输出的坐标偏置修正box位置)则输给后面的RCNN做进一步判断。(意思就是要从mn9个候选框中做筛选,提取proposals)
RPN 的结构如下图所示,backbone 输出的特征图经过一个 3 ∗ 3 3 * 3 3∗3 卷积之后分别进入了不同的分支,对应不同的 1 ∗ 1 1 * 1 1∗1 卷积。第一个卷积为定位层,输出 anchor 的4个坐标偏移。第二个卷积为分类层,输出anchor的前后景概率。
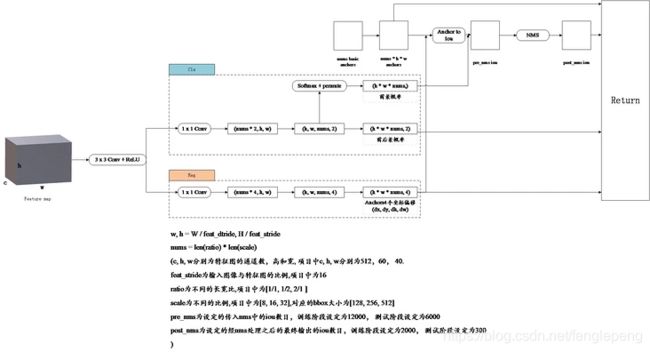
看完了rpn的大致结构,下面来看rpn的详细过程。主要看一下,rpn是如何生成以及处理anchor的。下图表示了rpn网络的详细结构。
第一步,生成基础 anchor(base_anchor),基础 anchor 的数目 = 长宽比的数目 * anchor 的缩放比例数目, 即 a n c h o r s n u m = l e n ( r a t i o s ) ∗ l e n ( s c a l e s ) anchors_num = len(ratios) * len(scales) anchorsnum=len(ratios)∗len(scales)。这里,设置了3种长宽比(1:1, 1:2,2:1)和3种缩放尺度(8, 16, 32),因此 anchor_num = 9. 下图表示了其中一个位置对应的9个尺寸的 anchor。
第二步,根据 base_anchor,对特征图上的每一个像素,都会以它为中心生成9种不同尺寸的边界框,所以总共生成 60 × 40 × 9 = 21600 60 \times 40 \times 9 = 21600 60×40×9=21600 个anchor。需要注意的是,所有生成的 anchor 都是相对于原图的。
牢记:特征图上的每个点生成一个Anchors,Anchors 可以理解成9个不同的框(框的属性是长宽了,再进一步是四个点的坐标)。这个框的数据(框的左上角坐标(x0,y0),右下角坐标(x1,y1))这四个值都是对应于原图的。下面这个就是原图,红色点就是特征图上的点对应于原图的位置。每一个位置使用 9 个锚点,每个位置会生成 2×9 个目标分数和 4×9 个坐标分数。显然,通过一个中心定义9个不同的框,就是为实现多尺度这个想法。当然这样做获得检测框很不准确,后面会做2次 bounding box regression 修正检测框位置。
第三步,anchor的筛选。首先将定位层输出的坐标偏移应用到所有生成的 anchor,然后将所有 anchor 按照 前景概率/得分 从高到低进行排序。只取前 pre_nms_num 个 anchor(训练阶段),最后 anchor 通过 nms 筛选得到 post_nms_num(训练阶段)个anchor,也称作 roi。
下面是卷积的具体过程

a.conv fetaure map 到 intermediate layer 的卷积过程
RPN网络前面是一个提特征的网络,比如VGG,Res等,传给RPN网络的是一个特征图,其实也就是一个 tensor,比如用ZF网络(论文里面用的)
输入特征图: 13 ∗ 13 ∗ 256 13*13*256 13∗13∗256
拿到模型的特征,RPN网络首先加了一个 3 ∗ 3 ∗ 256 ∗ 256 3*3*256*256 3∗3∗256∗256 步长为 1 的卷积层(可能是为了扩大感受野)
这样就会得到 11 ∗ 11 ∗ 256 11*11*256 11∗11∗256 的输出,前面 11 ∗ 11 11*11 11∗11 是图形矩阵,其中每一个点在原图中都是一个很大的区域,256表示这个区域的特征。
在这个区域内可能有目标,为了能更能逼近目标,我们需要3种尺度,和3种形状,就是图中的那9种物体框。假设原图中有一个物体,那我们通过在原图上平移框,就总能找到一个颜色框能正好把物体框在里面(真是厉害这想法),而且尺度啊形状最接近。
那么如何平移的呢?在原图上你一个像素一个像素平移没意义啊,难道要重复提取特征?所以平移必须在特征图上平移,因为特征图最后总能映射回原图。 11 ∗ 11 11*11 11∗11 的特征图区域,在原图中就表示 11 ∗ 11 11*11 11∗11 个大黑框,每个大黑框里面又有9个小颜色框,这样就会产生 11 ∗ 11 ∗ 9 11*11*9 11∗11∗9 个不同位置,不同尺度,不同形状的物体框,基本足够框出所有物体了。
b.intermediate layer 的256维向量后面对应两条分支
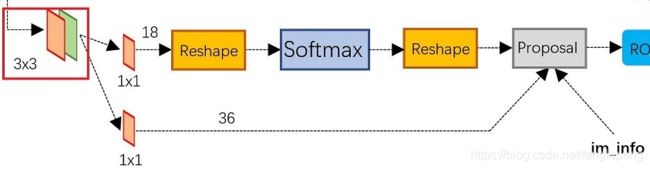
- cls layer 分支是目标和背景的二分类(classification),因为k等于9,所以通过 1 × 1 × 256 × 18 1×1×256×18 1×1×256×18 的卷积核得到 2 × 9 = 18 2×9 = 18 2×9=18 个分数,分别是目标和背景的评分。
- reg layer分支。如果候选框是目标区域,就去判断该目标区域的候选框位置在哪,这个时候另一条分支就过 1 × 1 × 256 × 36 1×1×256×36 1×1×256×36 的卷积得到 4 × 9 4×9 4×9 个值,每个框包含4个值(x,y,w,h),就是9个候选区域对应的框应该偏移的具体位置 Δ x c e n t e r , Δ y c e n t e r , Δ w i d t h , Δ h e i g h t Δxcenter,Δycenter,Δwidth,Δheight Δxcenter,Δycenter,Δwidth,Δheight。如果候选框不是目标区域,就直接将该候选框去除掉,不再进行后续位置信息的判断操作。这里预测的值都是通过模型不断训练得到的。
c. proposals layer
proposals layer 3个输入:一个是分类器结果 foreground softmax scores,一个是 anchor 回归 regression: [ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)] ,还有一个是 im-info,包含图像缩放的信息。proposal layer 步骤:
- 生成 anchors(anchors 的坐标是相对于原图的坐标),然后利用 [ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)] 对所有的 anchors 做 bbox regression 回归(这里的 anchors 生成和训练时完全一致)
- 按照输入的 foreground softmax scores 由大到小排序 anchors,提取前pre_nms_topN(e.g. 6000) 个anchors,即提取修正位置后的 foreground anchors。
- 判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors,剔除非常小(width
- 进行 nms,按照 nms 后的 foreground softmax scores 由大到小排序fg anchors,提取前 post_nms_topN(e.g. 300) 结果作为 proposal 输出。
总结起来就是:生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals。
anchors的标定规则
- 如果 Anchor 对应的 refrence box 与 ground truth 的 IoU 值最大,标记为正样本;
- 如果 Anchor 对应的 refrence box 与 ground truth 的 IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的 Anchor 对应的 reference box 与 groud truth 的 IoU 不大于0.7,可以采用第一种规则生成.
- 负样本标定规则:如果 Anchor 对应的 reference box 与 ground truth 的 IoU<0.3,标记为负样本。
- 剩下的既不是正样本也不是负样本,不用于最终训练。
- 训练 RPN 的Loss是有 classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
- 丢弃跨越边界的 anchor;
Loss
计算 softmax loss 需要的是 anchors 对应的 ground truth 标定结果和预测结果,计算regression loss 需要三组信息:
- 预测框,即 RPN 网络预测出的 proposal 的中心位置坐标x,y和宽高w,h;
- 锚点 reference box:之前的9个锚点对应9个reference boxes,每一个reference boxes都有一个中心点位置坐标 x a , y a x_a,y_a xa,ya 和宽高 w a , h a w_a,h_a wa,ha;
- ground truth:标定的框也对应一个中心点位置坐标x,y和宽高w,h.因此计算regression loss和总Loss方式如下:
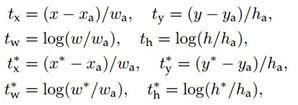
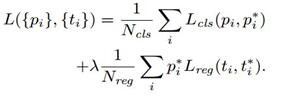
note
- 只有在train时,cls+reg 才能得到强监督信息(来源于ground truth)。即ground truth会告诉 cls+reg 结构,哪些才是真的前景,从而引导cls+reg结构学得正确区分前后景的能力;在 reference 阶段,就要靠 cls+reg 自力更生了。
- 在train阶段,会输出约2000个proposal,但只会抽取其中256个proposal来训练RPN的cls+reg结构;到了reference阶段,则直接输出最高score的300个proposal。此时由于没有了监督信息,所有RPN并不知道这些 proposal 是否为前景,整个过程只是惯性地推送一波无tag的proposal给后面的Fast R-CNN。
- RPN的运用使得region proposal的额外开销就只有一个两层网络。
- two stage型的检测算法在 RPN 之后还会进行再一次的分类任务和边框回归任务,以进一步提升检测精度。
- 在 RPN 末端,通过对两个分支的结果进行汇总,来实现对 anchor 的初步筛除(先剔除越界的 anchor,再根据 cls 结果通过NMS算法去重)和 初步偏移(根据 bbox reg结果),此时输出的都改头换面叫 proposal 了。
- RPN之后,proposal 成为 RoI (感兴趣区域) ,被输入 RoIPooling 或 RoIAlign 中进行 size上的归一化。当然,这些都是 RPN网络 之后的操作了,严格来说并不属于 RPN 的范围了。
- 但是如果只在最后一层 feature map 上映射回原图像,且初始产生的 anchor 被限定了尺寸下限,那么低于最小 anchor 尺寸的小目标虽然被 anchor 圈入,在后面的过程中依然容易被漏检。
- 但是FPN的出现,大大降低了小目标的漏检率,使得RPN如虎添翼。
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为: 1)根据现有网络初始化权值w,训练RPN; 2)用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w; 3)重复1、2,直到收敛。
参考:
- https://blog.csdn.net/ying86615791/article/details/72788414
- https://www.cnblogs.com/chaofn/p/9310912.html
- ttps://blog.csdn.net/sinat_33486980/article/details/81099093#commentBox