吴恩达深度学习笔记-机器学习策略(第8课)
机器学习策略
- 一、进行误差分析
- 二、清除标注错误的数据
- 三、快速搭建你的第一个系统,并进行迭代
- 四、在不同的划分上进行训练并测试
- 五、不匹配数据划分的偏差和方差
- 六、解决数据不匹配
- 七、迁移学习
- 八、多任务学习
- 九、什么是端到端的深度学习
- 十、是否使用端到端的深度学习
一、进行误差分析
- 当我们的模型还没有达到人类水平,可以人工检查一下你的算法犯的错误,也许能让我们知道下一步能做什么,这个过程就叫做误差分析。
- 例如在猫分类器中,我们达到了90%的正确率和10%的错误率;接下来可以对错误样本进行分析,发现分类器会将一些狗的照片分类成猫;解决这个问题可以通过扩大狗类样本或者单独制作一个狗分类器。但这么做值得吗,这时候就需要进行误差分析,即分析改善将狗分类成猫的这个问题对模型的正确率有多大的提升。
首先先分析错误分类样本中狗类样本所占的比例,根据比例来觉得是否需要解决这个问题。例如狗类样本在错误样本中占了5%,那么花费大量时间解决这个问题会提升10%*5%=0.5%的正确率,并没有显著的改善。若狗类样本占错误样本的50%,那么花时间去解决狗的问题效果就会很好,错误率将从10%降到5%。 - 简单的人工统计步骤,即错误分析,可以节省大量时间,可以迅速决定什么是最重要的,或者最有希望的方向。
- 当然可以同时进行多项误差分析:如
(1)解决小狗被分类成猫问题
(2)解决狮子、老虎被分类成猫问题
(3)图片模糊的问题
接下来要使用误差分析来评估这三个想法,可以使用表格来进行辅助分析:
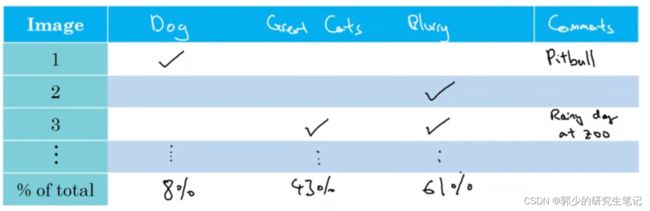
表格进行统计的过程发现的问题也可以添加到表格中去。最后根据误差分析结果对不同的问题分配不同的精力。
二、清除标注错误的数据
在数据集中原本就可能存在错误标记的样本,该怎么办呢?
-
首先,
深度学习算法对于训练集中的随机错误是相当健壮的,只要这些错误标记的例子离随机错误不太远,即不是有意而为之,那么放着这些错误不管可能也没问题。 -
但是深度学习对系统性的错误就没那么健壮了。例如将白色的狗狗一直分类成猫,那么在学习之后,分类器就会把所以白色的狗都分类为猫。
-
若担心开发集或者测试集中的错误样本带来的影响,可以通过错误分析列表格的方式来进行判断。如在表格中添加标签错误一栏:
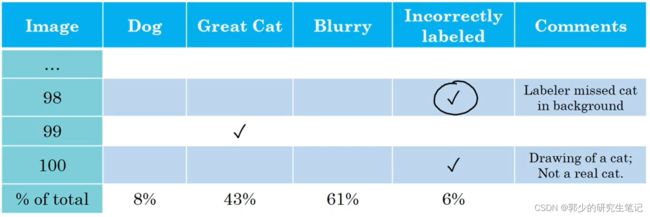
若这些错误样本严重的影响了在开发集上评估算法的能力,那么就应该花时间修正错误的标签。 -
在修正开发集时,有下面几点建议:
(1)对测试集和验证集同时进行修正,确保dev和test来自相同的分布。
(2)考虑检查一下算法正确和错误的例子【不容易实施,分析错误样本不难,但分析正确样本很难】
(3)train和dev/test可以来自不同的分布。即对开发集修正后,可以不对训练集进行修正。
三、快速搭建你的第一个系统,并进行迭代
在搭建系统时,应该:
(1)先建立dev、test数据集和评估指标。【即使指标错了后面也可以改】
(2)快速的建立初始的机器学习系统
(3)使用Bias/Variance analysis & Error analysis来确定下一步要做什么。
即先构建快速和肮脏的系统,在逐步分析进行优化。
四、在不同的划分上进行训练并测试
深度学习算法对训练数据的胃口很大,当你收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的数据量更大,甚至是大部分数据都来自和开发集、测试集不同的分布。如何处理训练集与开发集/测试集存在差异的问题呢?
假设存在两个数据集:20万份来自网上下载的高清的猫图片;1万份手机拍摄的低分辨率猫的图片。
(1)可以将两份数据合并在一起,再将数据随机分配到训练集、开发集和测试集中。
这么建立数据集的好处在于训练集、开发集和验证集均来自同一个分布;坏处在于开发集和测试集大部分图片都是来自网上的数据,但这些图片不是我们真正关心的数据分布。【所以这种方式不推荐使用】
(2)可以将手机拍摄的图片进行划分,一部分分到train里面,剩下的当作dev/test。
这样的好处是,我们在开发集瞄准(优化)的目标就是我们要处理的目标。坏处是训练集和dev/test的分布不同。
五、不匹配数据划分的偏差和方差
当train和dev/test的分布不一样时,bias和variance的分析会有所不同。
继续以猫分类器为例,假设人类水平错误率为0%。模型算法在train上有1%的错误率,dev上有10%的错误率。这个模型可能存在variance问题,不能够很好的泛化;但是如果train和dev/test的分布不一样时,就不能放心的下这个结论了。因为这9%的错误率可能来自算法本身,也可能是因为数据分布不同导致的。
为了判断是否是variance的问题,我们创造一个新的数据集:Train-dev set,训练-开发集。这是从train里划分出来的数据,与train有相同的分布,但是不会用于训练模型。
随机打散train,划分出train-dev,再用train去训练模型。为了确定是否是variance的问题,需要观察train、train-dev和开发集上的错误。

- 若train error是1%,train-dev error是9%,dev error是10%;我们就可以得出算法存在variance的问题了,因为train和train-dev是来自同一分布的,模型在训练集表现良好,但是无法泛化到相同分布的数据集中去。
- 若train error是1%,train-dev error是1.5%,dev error是10%;那么模型就是存在数据不匹配的问题了,即算法擅长处理的分布和你关心的数据的分布不一致。
- 若train error是10%,train-dev error是11%,dev error是12%;那么模型存在high bias问题。

一般情况下,人类水平 error、training error、training-dev error、dev error以及test error的数值是递增的,但是也会出现dev error和test error下降的情况。这主要可能是因为训练样本比验证/测试样本更加复杂,难以训练。
六、解决数据不匹配
如何解决数据不匹配:
(1)人工手动的做误差分析,尝试找出train set和dev/test set之间的差异。
(2)尝试使train set和dev/test set之间更加相似;或者收集更多相似的dev/test set数据。
人工合成数据需要注意:
假设我们在收集语言识别的数据样本,现在花6个消失收集了语音样本A,和花1个小时收集了噪音样本B。可以将A和B相互组合生成更多的样本,但是可能训练出来的模型对噪音B产生过拟合现象,因为A和B的组合可能只是所以样本中的一个子集。
七、迁移学习
-
深度学习最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。例如,也许你已经训练好一个神经网络,如识别猫的神经,我们可以使用这个神经网络的框架或者搭建过程中学到的知识去帮助更好地识别x射线扫描图,这就是所谓的
迁移学习。 -
例如,你训练了一个识别图片分类的神经网络;现在你想将这个神经网络投入到x射线扫描图中去使用,可以将原先的神经网络输出层去掉,加上新的输出层,之后再根据新的样本训练输入层和输出层的参数就可以识别x射线扫描图了。

经验规则是,如果你有一个小数据集,就只训练输出层前的最后一层,也许是最后一两层。但是如果你有很多数据,那么也许需要重新训练网络中的所有参数。
重新训练所有权重系数,初始始参数值由之前的模型训练得到,这一过程称为pre-training(预训练);之后,不断调试、优化的过程称为fine-tuning(微调)。
- 迁移学习起作用的场合是,在迁移来源问题中有很多数据,但迁移目标问题中没有那么多数据。
例如,图像识别任务中有1百万个样本,数据相当多,可以学习低层次特征,在神经网络的前面几层学到如何识别很多有用的特征。但是对于x射线扫描图任务,也许只有一百个样本,所以x射线扫描图问题数据很少,所以从图像识别训练中学到的很多知识可以迁移,并且真正帮你加强x射线扫描图任务的性能。 - 什么时候迁移学习是有意义的呢?如果我们要从A迁移到B:
(1)任务A和B都有相同的输入x【如图片分类和x射线扫描图输入的都是图片】
(2)任务A的数据比任务B大得多时
(3)从任务A中学习到的低层次特征对任务B有帮助
八、多任务学习
-
在迁移学习中,步骤是串行的,你从任务A里学习只是然后迁移到任务B。在多任务学习中,是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
-
例如假设我们在设计一个检测汽车图片的系统,可能需要检测出图片中的行人、汽车、交通灯和交通符号牌;

所以现在需要设计一个神经网络,输出一个思维向量,分布表示行人、汽车、交通灯和交通符号牌是否在图片中出现。

代价函数可以定义为下图的式子:

多任务学习和之前softmax 回归不同的是:softmax回归中只需要检测其中的一个是否会出现,而当前的任务四个物体会同时出现,即多任务学习的样本是multiple labels的,label中会出现多个1。
如果你训练了一个神经网络,试图最小化这个成本函数,做的就是多任务学习。因为现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉你,每张图里面有没有这四个物体。另外也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络一些早期特征,在识别不同物体时都会用到,然后你发现,训练一个神经网络做四件事情会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
多任务学习也可以学习部分标签缺失的数据集,即只要部分label被标记的数据集,在计算代价函数时,忽略未标记的部分求和即可。

-
多任务学习何时有意义:
(1)训练的一组任务可以公用低层次特征
(2)通常:每个任务的数据量非常相似。
如有A1、A2……A100个任务,每个任务只有1000个样本,多任务学习可以通过A1-A99的99000个样本进行学习,从而来帮到第100个任务A100的完成。
(3)可以训练足够大的神经网络来完成所有任务
多任务学习的替代方法是为每个任务训练一个单独的神经网络,不是训练单个神经网络同时处理行人、汽车、停车标志和交通灯检测。
九、什么是端到端的深度学习
-
什么是端到端的深度学习呢?
简单来说,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。 -
例如在语音识别任务中,先接收音频,然后使用MFCC来识别音频的一些低层次特征,再通过机器学习来找到一些音位从而识别出单词,再通过单词的组合对这段音频进行最后的翻译。

端到端的深度学习就是训练一个巨大的神经网络,输入一个音频直接输出翻译。端到端深度学习就只需要把训练集拿过来,直接学到了x和y之间的函数映射,直接绕过了其中很多步骤。 -
如果训练样本足够大,神经网络模型足够复杂,那么end-to-end模型性能比传统机器学习分块模型更好。当数据量不够大时,可以将端到端问题分解成几个子问题,若这几个子问题的数据量足够大,会比存粹的端到端深度学习方法表现得更好。
十、是否使用端到端的深度学习
端到端深度学习的优点和缺点:
优点:
(1)仅让数据说话
【即不像传统流水线机器学习那样加入人的主观想法,如通过音位去识别单词】
(2)所需组件的手工设计更少
缺点:
(1)可能需要大量数据
(2)丢弃了潜在有用的手工设计
是否使用端到端的深度学习需要思考的问题是:
是否有足够的数据样本去学习一个x映射到y的复杂函数