深度学习10-CNN的例子
补充:CNN(卷积神经网络)介绍 - 知乎 (zhihu.com)
卷积神经网络示例
构建完整卷积神经网络的构造模块我们已经掌握得差不多了,下面来看个例子。
假设,有一张大小为32×32×3的输入图片,这是一张RGB模式的图片,你想做手写体数字识别。32×32×3的RGB图片中含有某个数字,比如7,你想识别它是从0-9这10个数字中的哪一个,我们构建一个神经网络来实现这个功能。

这里我用的这个网络模型和经典网络LeNet-5非常相似,灵感也来源于此。LeNet-5是多年前Yann LeCun创建的,我所采用的模型并不是LeNet-5,但是受它启发,许多参数选择都与LeNet-5相似。输入是32×32×3的矩阵,假设第一层使用过滤器大小为5×5,步幅是1,padding是0,过滤器个数为6,那么输出为28×28×6。我们将这层标记为CONV1,它用了6个过滤器,增加了偏差,应用了非线性函数,也可能是ReLU非线性函数,最后输出CONV1的结果。
然后构建一个池化层,这里我选择用最大池化(max pooling),参数 f = 2, s = 2。接下来如果没有写padding,就意味着 p = 0。现在开始构建池化层,最大池化使用的过滤器为2×2,步幅为2,那么原有的高度和宽度会减少一半。因此,28×28变成了14×14,通道数量保持不变,所以最终输出为14×14×6,将该输出标记为POOL1。
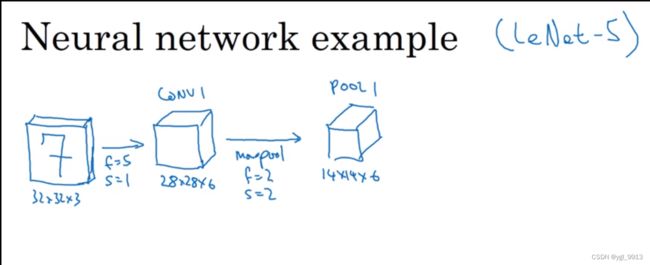
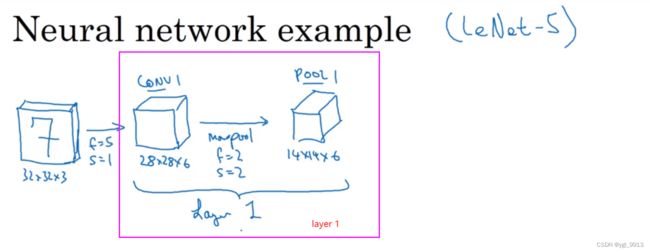
人们发现在卷积神经网络文献中有两种关于层的说法,二者有细微的差别。一种说法:一个卷积层和一个池化层一起作为一层, 那么这两个单元在一起组成神经网络的第一层 Layer 1;另一种说法:卷积层为一层,池化层单独为一层。人们在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。我会使用CONV1和POOL1共同作为一个卷积,并标记为Layer 1。所以当你在阅读网络文章或研究报告时,你可能会看到卷积层和池化层各为一层的情况,这只是两种不同的标记术语。一般我在统计网络层数时,只计算具有权重的层,也就是把CONV1和POOL1作为Layer1。
ps:最大池化层没有任何可训练的权重。它只有超参数,但它们是不可训练的。最大池化过程计算过滤器的最大值,其中不包含权重和偏差。这纯粹是一种将数据缩小到较小维度的方法。
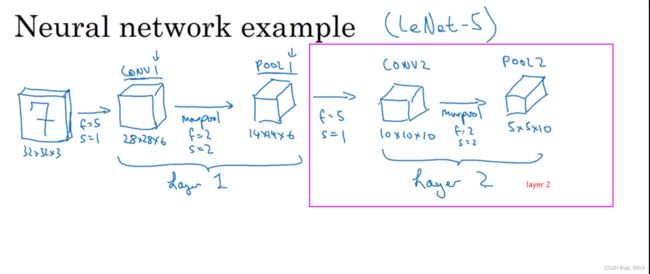
接下来在得到14×14×6基础上,让我们在做一层卷积,这次使用过滤器大小为5×5,步幅为1,这次我们用10个过滤器,最后输出一个10×10×10的矩阵,标记为CONV2。
然后继续做最大池化,超参数 f = 2,s = 2。你大概可以猜出结果,在这个此参数下,输出的高度和宽度会减半。最后输出为5×5×10,标记为POOL2,这就是神经网络的第二个卷积层,即Layer2。
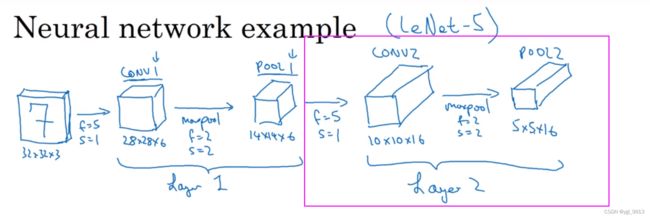
如果对Layer1应用另一个卷积层 ,过滤器为5x5,即 f = 5,步长s = 1,padding = 0(以下同理不提就0)。使用16个过滤器,所以CONV2输出为10×10×16。接着继续执行做大池化计算,参数 f = 2,s = 2,你能猜到结果吗?答案是:高度和宽度减半,结果为5×5×16。通道数和之前一样,把它标记为POOL2。按照之前的说法,CONV2 和 POOL2 在一起被称为 Layer2(由于只有Conv2有权重)。
接着上面,这里5×5×16矩阵包含400个元素,现在将POOL2(池化层2)展开为一个大小为400的一维向量。把它想象成如图所示的一组展开的神经元,然后利用这400个单元作为输入,创建一个有120个单元的下一层。这实际上就是我们第一个全连接层,标记为FC3(称之为)。因为这400个输入单元与120个输出单元紧密相连,这就是全连接层。它很像我们在第一和第二门课中讲过的单神经网络层。这是一个标准的神经网络。它的权重矩阵为W[ 3 ],维度为120×400。因为这400个输入单元与这120个输出单元的每一项相连,所以被称为全连接网,并且这里还有一个偏差参数b [ 3 ],偏差参数b [ 3 ]大小也是120个向量(因为有120个输出)。
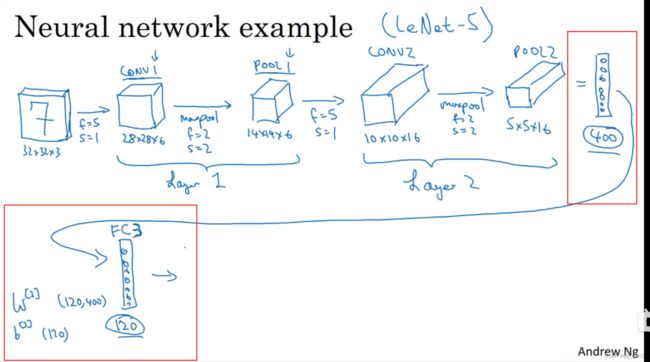
最后一步让我们在120个单元的基础上再加一层(全连接层),让它变得更小。假设它含有84个单元,标记为FC4。最后,用这84个单元填充一个softmax层。如果我们想通过手写数字识别来识别手写0-9这10个数字,这个softmax层就会有10个输出。这是一个相对典型的例子。
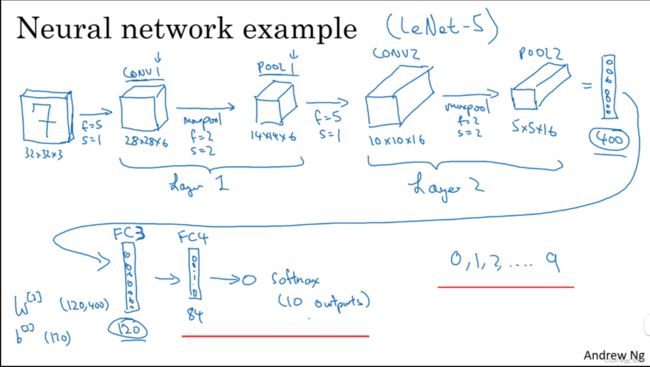
这是一个相对典型的例子,它展示了一个卷积神经网络的大致构成。看上去它有很多超参数,关于如何选定这些参数,后面我提供更多建议。常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序,这块下周我会细讲。
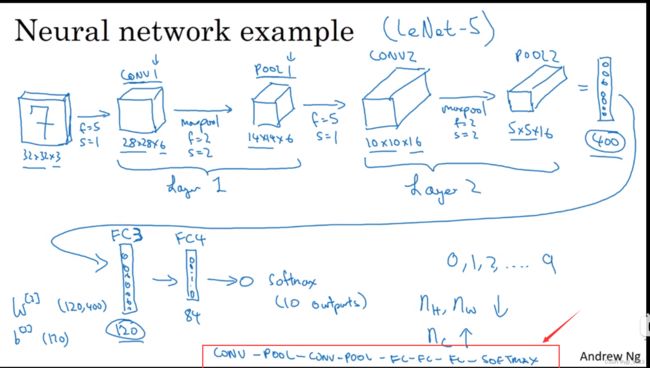
现在,我只是想指出的是,随着神经网络深度的加深,高度n_H 和宽度 n_W 通常会减少,如之前所示,从32×32到28×28,到14×14,到10×10,再到5×5。因此当你深入下去通常高度和宽度会减小,而通道数量会增加,从3到6到16不断增加,然后得到一个全连接层。

另一类常见的神经网络模型是一个或多个卷积层后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后再叠加几个全连接层,也许最后还叠加一个softmax层。如上所述,这是神经网络常见的另一种模式。
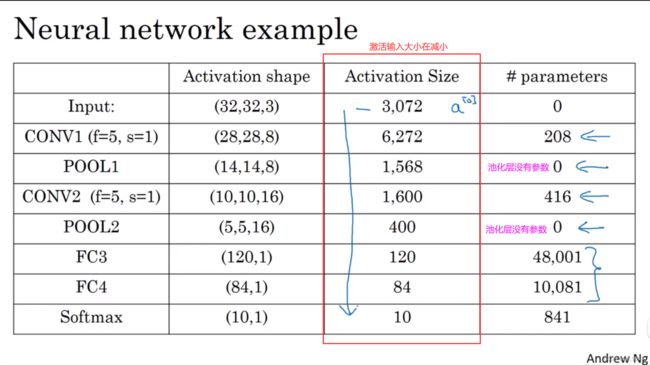
那么让我们再回顾一下,神经网络的一些细节。比如神经网络的激活值形状,激活值大小和参数数量。输入为32×32×3,这些数做乘法,结果为3072,所以激活值 a[0] 有3072维(实际尺寸32×32×3),(我们认为)输入层没有参数。下面看一下不同层的数据。

有几点要注意,第一,池化层和最大池化层没有参数;第二,卷积层的参数相对较少,前面课上我们提到过,其实许多参数都存在于神经网络的全连接层。观察可发现,随着神经网络的加深,激活输入大小(激活值尺寸)会逐渐变小,如果激活输入大小(激活值尺寸)下降太快,也会影响神经网络性能。示例中,激活值尺寸(输入大小)在第一层为6000,然后减少到1600,慢慢减少到84,最后输出softmax结果。我们发现,许多卷积网络都具有这些属性,模式上也相似。
神经网络的基本构造模块我们已经讲完了,一个卷积神经网络包括卷积层、池化层和全连接层。许多计算机视觉研究正在探索如何把这些基本模块整合起来,构建高效的神经网络,整合这些基本模块确实需要深入的理解。根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例。下周我会演示一些整合基本模块,成功构建高效神经网络的具体案例。我希望下周的课程可以帮助你找到构建有效神经网络的感觉,或许你也可以将别人开发的框架应用于自己的应用程序,这是下周的内容。下节课,也是本周最后一节课,我想花点时间讨论下,为什么大家愿意使用卷积,使用卷积的好处和优势是什么,以及如何整合多个卷积,如何检验神经网络,如何在训练集上训练神经网络来识别图片或执行其他任务,我们下节课继续讲。
学习笔记
如有错请指正!谢谢