自动机器学习AutoML:Auto-Sklearn
(自己对网上的一些资料做的总结,仅想记录下来用来之后方便自己查找)
链接: Auto-Sklearn.
将系统全面的介绍自动机器学习的其中一个常用框架: Auto-Sklearn,介绍安装及使用,分类和回归小案例,以及一些用户手册的介绍。
AutoML全称是Automated Machine Learning,是2014年以来,机器学习和深度学习领域最炙手可热的领域之一。它主要将机器学习中所有耗时过程自动化,如数据预处理、最佳算法选择、超参数调整等,这样可节约大量时间在建立机器学习模型过程中。

AutoML,是为数据集发现数据转换、模型和模型配置的最佳性能管道的过程。
AutoML 通常涉及使用复杂的优化算法(例如贝叶斯优化)来有效地导航可能模型和模型配置的空间,并快速发现对给定预测建模任务最有效的方法。它允许非专家机器学习从业者快速轻松地发现对于给定数据集有效甚至最佳的方法,而技术背景或直接输入很少。
使用过 sklearn 的话,对于上面定义应该不难理解。下面再结合一个流程图来进一步理解一下;

Auto-Sklearn
Auto-Sklearn是一个开源库,用于在 Python 中执行 AutoML。它利用流行的 Scikit-Learn 机器学习库进行数据转换和机器学习算法。
它是由Matthias Feurer等人开发的。
并在他们 2015 年题为“efficient and robust automated machine learning [1]”的论文中进行了描述。

Auto-Sklearn 的好处在于,除了发现为数据集执行的数据预处理和模型之外,它还能够从在类似数据集上表现良好的模型中学习,并能够自动创建性能最佳的集合作为优化过程的一部分发现的模型。

Auto-Sklearn 是改进了一般的 AutoML 方法,自动机器学习框架采用贝叶斯超参数优化方法,有效地发现给定数据集的性能最佳的模型管道。
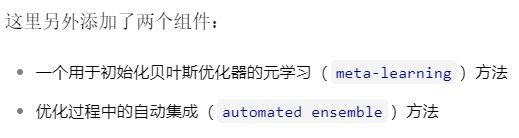
这种元学习方法是贝叶斯优化的补充,用于优化 ML 框架。对于像整个 ML 框架一样大的超参数空间,贝叶斯优化的启动速度很慢。通过基于元学习选择若干个配置来用于种子贝叶斯优化。这种通过元学习的方法可以称为热启动优化方法。再配合多个模型的自动集成方法,使得整个机器学习流程高度自动化,将大大节省用户的时间。从这个流程来看,让机器学习使用者可以有更多的时间来选择数据以及思考要处理的问题本身。
贝叶斯优化
贝叶斯优化的原理是利用现有的样本在优化目标函数中的表现,构建一个后验模型。该后验模型上的每一个点都是一个高斯分布,即有均值和方差。若该点是已有样本点,则均值就是该点的优化目标函数取值,方差为0。而其他未知样本点的均值和方差是后验概率拟合的,不一定接近真实值。那么就用一个采集函数,不断试探这些未知样本点对应的优化目标函数值,不断更新后验概率的模型。由于采集函数可以兼顾Explore/Exploit,所以会更多地选择表现好的点和潜力大的点。因此,在资源预算耗尽时,往往能够得到不错的优化结果。即找到局部最优的优化目标函数中的参数。

上图是在一个简单的 1D 问题上应用贝叶斯优化的实验图,这些图显示了在经过四次迭代后,高斯过程对目标函数的近似。我们以 t=3 为例分别介绍一下图中各个部分的作用。
上图 2 个 evaluations 黑点和一个红色 evaluations,是三次评估后显示替代模型的初始值估计,会影响下一个点的选择,穿过这三个点的曲线可以画出非常多条。黑色虚线曲线是实际真正的目标函数 (通常未知)。黑色实线曲线是代理模型的目标函数的均值。紫色区域是代理模型的目标函数的方差。绿色阴影部分指的是acquisition function的值,选取最大值的点作为下一个采样点。只有三个点,拟合的效果稍差,黑点越多,黑色实线和黑色虚线之间的区域就越小,误差越小,代理模型越接近真实模型的目标函数。
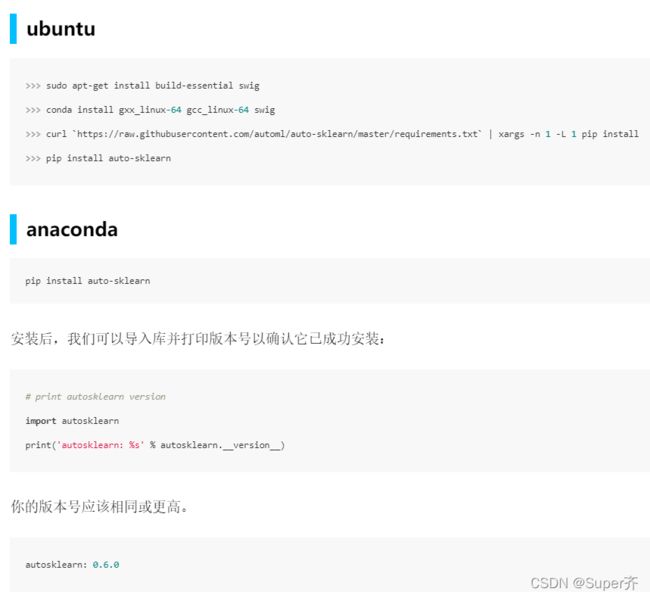
安装和使用 Auto-Sklearn
Auto-sklearn 提供了开箱即用的监督型自动机器学习。从名字可以看出,auto-sklearn 是基于机器学习库 scikit-learn 构建的,可为新的数据集自动搜索学习算法,并优化其超参数。因此,它将机器学习使用者从繁琐的任务中解放出来,使其有更多时间专注于实际问题。
这里可以参考auto-sklearn官方文档[2]。
根据预测任务的不同,是分类还是回归,可以创建和配置 AutoSklearnClassifier[3] 或 AutoSklearnRegressor[4]类的实例,将其拟合到数据集上,仅此而已。然后可以使用生成的模型直接进行预测或保存到文件(使用pickle)以供以后使用。
AutoSklearn类参数
AutoSklearn 类提供了大量的配置选项作为参数。
默认情况下,搜索将在搜索过程中使用数据集的train-test拆分,为了速度和简单性,这里建议使用默认值。
参数n_jobs可以设置为系统中的核心数,如有 8 个核心,则为n_jobs=8。
一般情况下,优化过程将持续运行,并以分钟为单位进行测量。默认情况下,它将运行一小时。
这里建议将time_left_for_this_task参数此任务的最长时间(希望进程运行的秒数)。例如,对于许多小型预测建模任务(少于 1,000 行的数据集)来说,不到 5-10 分钟可能就足够了。如果没有为此参数指定任何内容,则该过程将优化过程将持续运行,并以分钟为单位进行测量,将运行一小时,即60分钟。本案例通过 per_run_time_limit 参数将分配给每个模型评估的时间限制为 30 秒。例如:

另外还有其他参数,如ensemble_size、initial_configurations_via_metalearning,可用于微调分类器。默认情况下,上述搜索命令会创建一组表现最佳的模型。为了避免过度拟合,我们可以通过更改设置 ensemble_size = 1 和initial_configurations_via_metalearning = 0来禁用它。我们在设置分类器时排除了这些以保持方法的简单。
在运行结束时,可以访问模型列表以及其他详细信息。sprint_statistics()函数总结了最终模型的搜索和性能。
