R语言logistic回归交互项(交互作用)的可视化分析2
交互作用效应(p for Interaction)在SCI文章中可以算是一个必杀技,几乎在高分的SCI中必出现,因为把人群分为亚组后再进行统计可以增强文章结果的可靠性,不仅如此,交互作用还可以使用来进行数据挖掘。在既往文章中,我们已经介绍了怎么使用R语言可视化visreg包对交互作用进行可视化分析(见下图),
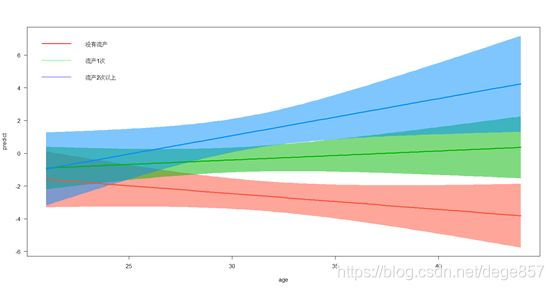
但是使用visreg包后我们对图形的细节掌控力不够,今天我们使用重新绘制手动图形,这在SCI论文中非常实用,几乎可以做出所有的交互可视化,也有利于我们了解制图原理。
废话不多说,我们实操一下。我们使用人流后导致不孕的数据集(关注公众号后回复:不孕症,可以获得数据),我们先导入看一下
library(rms)
bc<-read.csv("E:/r/test/buyunzheng.csv",sep=',',header=TRUE)

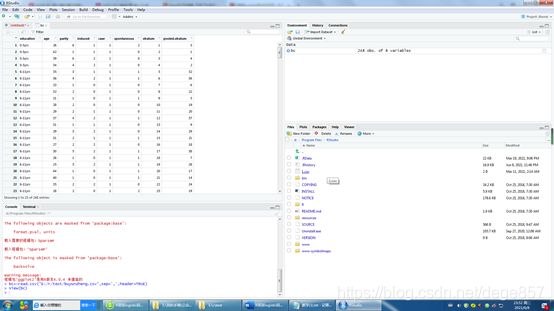
数据有8个指标,最后两个是PSM匹配结果,我们不用理他,其余六个为:
Education:教育程度,age:年龄,parity产次,induced:人流次数,case:是否不孕,这是结局指标,spontaneous:自然流产次数。
有一些变量是分类变量,我们需要把它转换一下
bc$education<-ifelse(bc$education=="0-5yrs",0,ifelse(bc$education=="6-11yrs",1,2))
bc$spontaneous<-as.factor(bc$spontaneous)
bc$case<-as.factor(bc$case)
bc$induced<-as.factor(bc$induced)
bc$education<-as.factor(bc$education)
建立模型,假如我们想知道流产(包括人流和自然流产)和年龄这两个指标是不是存在交互影响
f1<- glm(case ~ age + education + parity + induced+spontaneous+age*induced*spontaneous,
family = binomial(link = logit), data = bc)
summary(f1)
我们看到自然流产和年龄之间可能存在交互(下图)
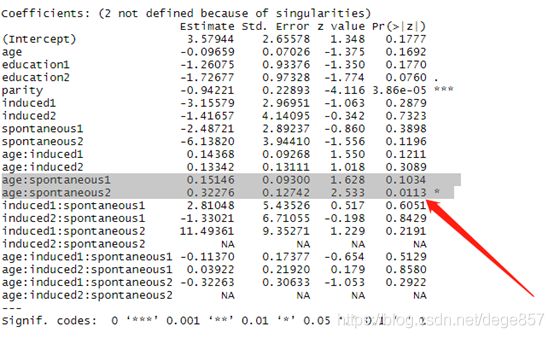
重新建立模型
f1<- glm(case ~ age + parity +spontaneous+age:spontaneous,
family = binomial(link = logit), data = bc)
建立新数据集
attach(bc)
newdata2<-data.frame(age,spontaneous,parity=mean(parity))
把模型带入新数据集
newdata3<-data.frame(newdata2,predict(f1,newdata = newdata2,type = "link",se =T))
生成预测值
newdata4<-within(newdata3,{
pre<-plogis(fit)
ll<-plogis(fit-(1.96*se.fit))
ul<-plogis(fit+(1.96*se.fit))
})
最后绘图
ggplot(newdata4,aes(x=age,y=pre))+
geom_line(aes(col=spontaneous),size=1)

最后对图形进行修饰
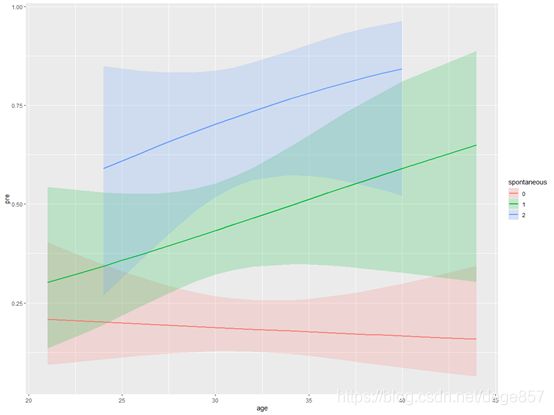
最后得出和visreg包同样的结果,随着年龄增长,自然流产2次以上的患者不孕的概率比没有自然流产的患者明显增高。
我们还可以在细节和年龄范围进一步修饰,这里就不多说了,总之,数据交互可视化是一项非常实用的技能,不仅可以用于数据分析,还可以用于数据挖掘。
