python利用selenium/requests/bs4/xpath爬虫知网8516本学术期刊具体概要
作业描述
基于requests爬虫模块库, 把所有学术期刊的简介信息爬取下来
导航页网址: https://navi.cnki.net/knavi/Journal.html
要求:
- 爬取所有学术期刊的简介信息
- 每一个具体期刊页面中,从网页上抽取的保存的内容包括 所有 概要 描述元素
如:
URL,期刊名称,期刊数据库(上方所有红色图标后的文字描述)
基本信息: 主办单位,出版周期,。。。。。。。
出版信息: 专辑名称,。。。。。。
评价信息: 复合影响因子,综合影响因子。。。。。
示例如下:

将这些元素存储在文件中(举例:csv,xlsx等文件)
因为这是python数据分析课的附加作业,所以想拿到分,历时好几天,解决了好多好多好多问题,终于按照老师要求爬出来了。
先上效果图:
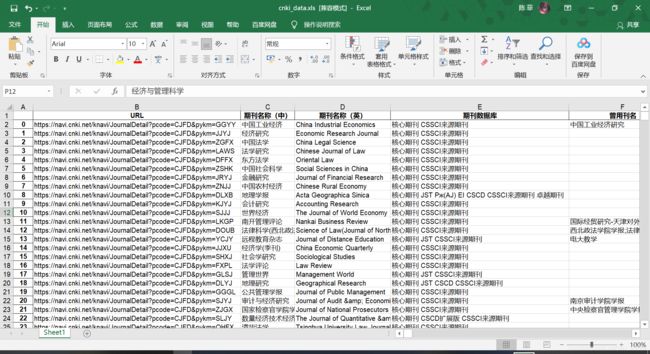
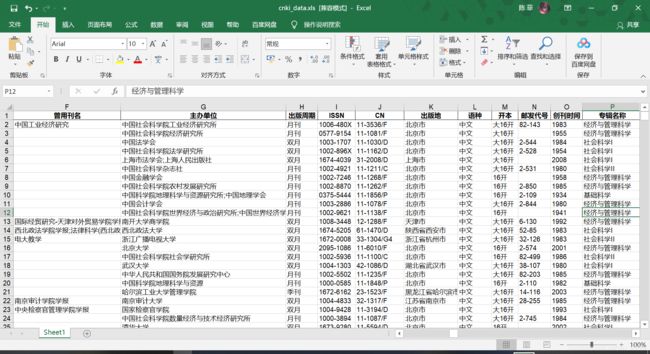
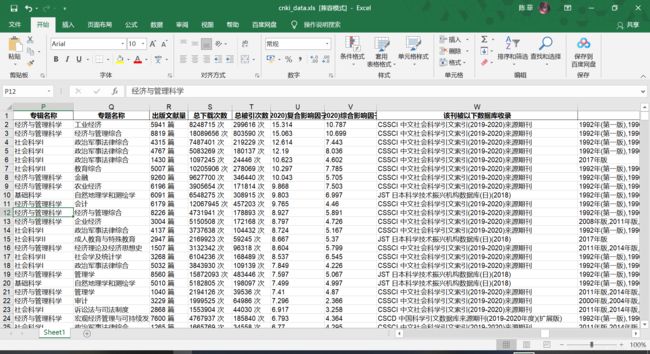
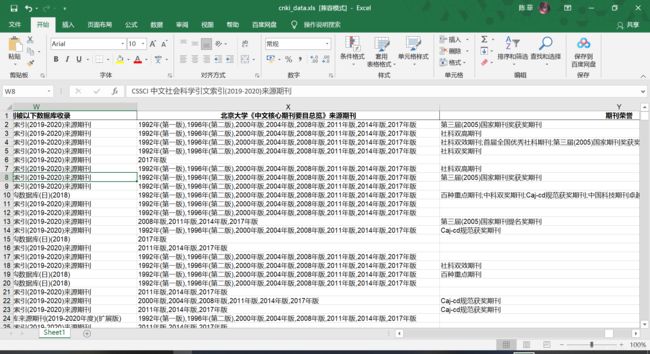
之前爬虫纯小白的我,了解并尝试了requests→scrapy→selenium→selenium+requests→requests,最后发现这种作业级别的确实只用requests就够了。
无数次处在崩溃边缘,无数次觉得自己差一点就能成功……
刚开始因为什么都不懂,查到了这篇文章https://codingdict.com/blog/509。然后感觉自己似乎有点懂了,就很天真的打算用webdriver模拟点击八千多页来爬取每一页的详情概要,具体的代码写出来之后才发现每次爬几百页一两千页就会出现很奇怪的问题,而下一次到这里的时候并不会出现问题,就感觉其实是模拟点击不太合适,页数少一点或许还可以凑合,不过代码还是可以参考的。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import multiprocessing
import random
import csv
import pandas as pd
# 设置谷歌驱动器的环境
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') #浏览器在后台运行
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu') #禁用gpu
chrome_options.add_argument('--disable-dev-shm-usage')
# browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置chrome不加载图片,提高速度
chrome_options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(executable_path = r'C:\Program Files\Google\Chrome\Application\chromedriver', options = chrome_options)
browser.maximize_window()
url = 'https://navi.cnki.net/knavi/Journal.html'
def start_spider(start_page, end_page):
try:
curr_page = start_page
data_list = []
browser.get(url)
time.sleep(2)
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.LINK_TEXT, '学术期刊')
)
)
browser.find_element_by_link_text('学术期刊').click()
# 显示等待页码数量加载完成
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.ID, 'lblPageCount')
)
)
# pages = int(browser.find_elements_by_id('lblPageCount')[0].text)
# print(pages)
for i in range(start_page):
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.LINK_TEXT, '下一页')
)
)
time.sleep(2)
browser.find_element_by_link_text('下一页').click()
curr_page += 1
for i in range(start_page, end_page):
# 显示等待所有期刊加载完成
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'lazy')
)
)
divs_count = len(browser.find_elements_by_class_name('lazy'))
start_time = time.time()
for i in range(divs_count):
# time.sleep(2)
# link = browser.find_elements_by_xpath('//a[contains(@href,"/KNavi")]')[i].get_attribute("href")
# js = 'window.open("%s");' % link
# 每次访问链接的时候适当延迟
time.sleep(random.uniform(1, 2))
# browser.execute_script(js)
browser.find_elements_by_class_name('lazy')[i].click()
# 切换句柄
browser.switch_to.window(browser.window_handles[1])
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.ID, 'J_sumBtn-stretch')
)
)
browser.find_element_by_id('J_sumBtn-stretch').click()
data_dict = {}
data_dict['URL'] = browser.current_url
data_dict['期刊名称'] = browser.find_element_by_class_name('titbox').text
data_dict['期刊数据库'] = browser.find_element_by_class_name('journalType').text
try:
data_dict['曾用刊名'] = browser.find_element_by_xpath("//p[contains(text(),'曾用刊名')]").text.split(':')[
-1]
except:
data_dict['曾用刊名'] = ''
try:
data_dict['主办单位'] = browser.find_element_by_xpath("//p[contains(text(),'主办单位')]").text.split(':')[
-1]
except:
data_dict['主办单位'] = ''
try:
data_dict['出版周期'] = browser.find_element_by_xpath("//p[contains(text(),'出版周期')]").text.split(':')[
-1]
except:
data_dict['出版周期'] = ''
try:
data_dict['ISSN'] = browser.find_element_by_xpath("//p[contains(text(),'ISSN')]").text.split(':')[
-1]
except:
data_dict['ISSN'] = ''
try:
data_dict['CN'] = browser.find_element_by_xpath("//p[contains(text(),'CN')]").text.split(':')[-1]
except:
data_dict['CN'] = ''
try:
data_dict['出版地'] = browser.find_element_by_xpath("//p[contains(text(),'出版地')]").text.split(':')[-1]
except:
data_dict['出版地'] = ''
try:
data_dict['语种'] = browser.find_element_by_xpath("//p[contains(text(),'语种')]").text.split(':')[-1]
except:
data_dict['语种'] = ''
try:
data_dict['开本'] = browser.find_element_by_xpath("//p[contains(text(),'开本')]").text.split(':')[-1]
except:
data_dict['开本'] = ''
try:
data_dict['邮发代号'] = browser.find_element_by_xpath("//p[contains(text(),'邮发代号')]").text.split(':')[
-1]
except:
data_dict['邮发代号'] = ''
try:
data_dict['创刊时间'] = browser.find_element_by_xpath("//p[contains(text(),'创刊时间')]").text.split(':')[
-1]
except:
data_dict['创刊时间'] = ''
try:
data_dict['专辑名称'] = browser.find_element_by_xpath("//p[contains(text(),'专辑名称')]").text.split(':')[
-1]
except:
data_dict['专辑名称'] = ''
try:
data_dict['专题名称'] = browser.find_element_by_xpath("//p[contains(text(),'专题名称')]").text.split(':')[
-1]
except:
data_dict['专题名称'] = ''
try:
data_dict['出版文献量'] = browser.find_element_by_xpath("//p[contains(text(),'出版文献量')]").text.split(':')[
-1]
except:
data_dict['出版文献量'] = ''
try:
data_dict['总下载次数'] = browser.find_element_by_xpath("//p[contains(text(),'总下载次数')]").text.split(':')[
-1]
except:
data_dict['总下载次数'] = ''
try:
data_dict['总被引次数'] = browser.find_element_by_xpath("//p[contains(text(),'总被引次数')]").text.split(':')[
-1]
except:
data_dict['总被引次数'] = ''
try:
data_dict['(2020)复合影响因子'] = \
browser.find_element_by_xpath("//p[contains(text(),'(2020)复合影响因子')]").text.split(':')[-1]
except:
data_dict['(2020)复合影响因子'] = ''
try:
data_dict['(2020)综合影响因子'] = \
browser.find_element_by_xpath("//p[contains(text(),'(2020)综合影响因子')]").text.split(':')[-1]
except:
data_dict['(2020)综合影响因子'] = ''
# print(data_dict)
data_list.append(data_dict)
browser.close()
browser.switch_to.window(browser.window_handles[0])
time.sleep(1)
end_time = time.time()
end = time.asctime()
curr_page = int(browser.find_elements_by_id('txtPageGoToBottom')[0].text)
print('在' + end + '爬完第%d页' % curr_page)
print('已花' + str(end_time - start_time) + '秒爬完第%d页' % curr_page)
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.LINK_TEXT, '下一页')
)
)
time.sleep(1)
browser.find_element_by_link_text('下一页').click()
except Exception as e:
print(e)
pass
browser.quit()
return curr_page, data_list
def main():
# 开始爬虫
start_page = 0
end_page = start_page + 10
csv_name = 'C:\学习资料\大二下\python数据分析\爬虫\cnki_data' + str(start_page) + '-' + str(end_page) + '.csv'
xls_name = 'C:\学习资料\大二下\python数据分析\爬虫\cnki_data' + str(start_page) + '-' + str(end_page) + '.xls'
curr_page, data_list = start_spider(start_page, end_page)
# 将数据写入csv文件
with open(csv_name, 'w', encoding='utf-8', newline='') as f:
title = data_list[0].keys()
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(data_list)
print('csv文件写入完成')
df = pd.read_csv(csv_name)
df = df.to_excel(xls_name)
print('excel文件写入完成')
df = pd.read_excel(xls_name)
print(df.shape[0] / 21)
if __name__ == '__main__':
main()
上面这份代码,其实要写的话遇到的问题也很多很多,比如说如何设置不要太快模拟点击而被服务器识别,爬取的数据不存在所以用了很多白痴的try catch模块,等等问题。
因为作业要求里,老师提到可以用url,但是我又发现,在导航页,和后面四百多个学术期刊的导航页的url都是一样的,所以不知道这种情况用requests.get该怎么弄。但后面在无意间跟同学交流的过程中,听到同学根本没有用到selenium,而是只用了requests库,我自己琢磨了下,打算用webdriver模拟点击406页爬下8516条url,然后用requests.get方法对八千多条url进行访问。
from selenium import webdriver
import requests
from lxml import etree
import time
import csv
import pandas as pd
# 设置谷歌驱动器的环境
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
# browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置chrome不加载图片,提高速度
chrome_options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(executable_path = r'C:\Program Files\Google\Chrome\Application\chromedriver', options = chrome_options)
url = 'https://navi.cnki.net/knavi/Journal.html'
def get_urls(total_page_num):
urls = []
browser.get(url)
time.sleep(2)
WebDriverWait(browser, 100).until(
EC.presence_of_all_elements_located(
(By.LINK_TEXT, '学术期刊')
)
)
browser.find_element_by_link_text('学术期刊').click()
time.sleep(2)
for i in range(total_page_num):
time.sleep(2)
divs = browser.find_elements_by_xpath('//a[contains(@href,"/KNavi")]')
for j in divs:
urls.append(j.get_attribute("href"))
time.sleep(2)
browser.find_element_by_link_text('下一页').click()
print('已爬完%d页所有url' % total_page_num)
browser.quit()
return urls
urls = get_urls(406)
print('共爬到%d本期刊的url' % (len(urls)))
file = pd.DataFrame(data = urls)
file.to_csv(r'C:\学习资料\大二下\python数据分析\爬虫\urls.csv')
print('urls文件写入完成')
已爬完406页所有url
共爬到8516本期刊的url
urls文件写入完成
def get_details(urls, headers):
try:
data_list = []
count = 0
for url in urls:
html = requests.get(url=url, headers=headers).text # 发起请求
root = etree.HTML(html)
data_dict = {}
data_dict['URL'] = url
data_dict['期刊名称'] = root.xpath("//h3[@class='titbox']")[0].text.split('\r\n ')[1]
data_dict['期刊数据库'] = " ".join(root.xpath("//p[@class='journalType']/span/text()"))
data_dict['曾用刊名'] = root.xpath("//p[contains(text(),'曾用刊名')]//text()")[1] if len(root.xpath("//p[contains(text(),'曾用刊名')]//text()"))==2 else ''
data_dict['主办单位'] = root.xpath("//p[contains(text(),'主办单位')]//text()")[1] if len(root.xpath("//p[contains(text(),'主办单位')]//text()"))==2 else ''
data_dict['出版周期'] = root.xpath("//p[contains(text(),'出版周期')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版周期')]//text()"))==2 else ''
data_dict['ISSN'] = root.xpath("//p[contains(text(),'ISSN')]//text()")[1] if len(root.xpath("//p[contains(text(),'ISSN')]//text()"))==2 else ''
data_dict['CN'] = root.xpath("//p[contains(text(),'CN')]//text()")[1] if len(root.xpath("//p[contains(text(),'CN')]//text()"))==2 else ''
data_dict['出版地'] = root.xpath("//p[contains(text(),'出版地')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版地')]//text()"))==2 else ''
data_dict['语种'] = root.xpath("//p[contains(text(),'语种')]//text()")[1] if len(root.xpath("//p[contains(text(),'语种')]//text()"))==2 else ''
data_dict['开本'] = root.xpath("//p[contains(text(),'开本')]//text()")[1] if len(root.xpath("//p[contains(text(),'开本')]//text()"))==2 else ''
data_dict['邮发代号'] = root.xpath("//p[contains(text(),'邮发代号')]//text()")[1] if len(root.xpath("//p[contains(text(),'邮发代号')]//text()"))==2 else ''
data_dict['创刊时间'] = root.xpath("//p[contains(text(),'创刊时间')]//text()")[1] if len(root.xpath("//p[contains(text(),'创刊时间')]//text()"))==2 else ''
data_dict['专辑名称'] = root.xpath("//p[contains(text(),'专辑名称')]//text()")[1] if len(root.xpath("//p[contains(text(),'专辑名称')]//text()"))==2 else ''
data_dict['专题名称'] = root.xpath("//p[contains(text(),'专题名称')]//text()")[1] if len(root.xpath("//p[contains(text(),'专题名称')]//text()"))==2 else ''
data_dict['出版文献量'] = root.xpath("//p[contains(text(),'出版文献量')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版文献量')]//text()"))==2 else ''
data_dict['总下载次数'] = root.xpath("//p[contains(text(),'总下载次数')]//text()")[1] if len(root.xpath("//p[contains(text(),'总下载次数')]//text()"))==2 else ''
data_dict['总被引次数'] = root.xpath("//p[contains(text(),'总被引次数')]//text()")[1] if len(root.xpath("//p[contains(text(),'总被引次数')]//text()"))==2 else ''
data_dict['(2020)复合影响因子'] = root.xpath("//p[contains(text(),'(2020)复合影响因子')]//text()")[1] if len(root.xpath("//p[contains(text(),'(2020)复合影响因子')]//text()"))==2 else ''
data_dict['(2020)综合影响因子'] = root.xpath("//p[contains(text(),'(2020)综合影响因子')]//text()")[1] if len(root.xpath("//p[contains(text(),'(2020)综合影响因子')]//text()"))==2 else ''
data_list.append(data_dict)
count += 1
# print('已爬完第%d本期刊的所有概要' % count)
except Exception as e:
print(e)
pass
return data_list
f = open(r'C:\学习资料\大二下\python数据分析\爬虫\urls.csv')
next(f)
reader = csv.reader(f)
urls = []
for url in reader:
urls.append(url[1])
f.close()
print('已成功读取%d条url' % (len(urls)))
headers = {'User-Agent': ''}
# 开始爬取每个页面具体信息
data_list = get_details(urls, headers)
csv_name = 'C:\学习资料\大二下\python数据分析\爬虫\cnki_data.csv'
xls_name = 'C:\学习资料\大二下\python数据分析\爬虫\cnki_data.xls'
# 将数据写入csv文件
with open(csv_name, 'w', encoding='utf-8', newline='') as f:
title = data_list[0].keys()
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(data_list)
print('csv文件写入完成')
df = pd.read_csv(csv_name)
df = df.to_excel(xls_name)
print('excel文件写入完成')
csv文件写入完成
excel文件写入完成
这个运行出来的结果其实是可以的,前面爬url那块大概半个小时,后面用requests.get(url)八千多个页面爬取+解析大概两个小时不到,可把我高兴的,之前纯用webdriver再不出错的情况下,我算过了,要十几个小时。本来以为能交作业了,但是自己漏解析了期刊的英文名称和影响因子下面的其他评价信息。
后来有个同学找我聊这个作业,我们探讨了发现,其实前面爬取url也并不需要用到webdriver,只需要用到requests.post(url, header, data)这个函数就行,更快了。
def save_urls(page_nums, urls_path):
urls = []
for page in range(page_nums):
data = {
'SearchStateJson': '{"StateID":"","Platfrom":"","QueryTime":"","Account":"knavi","ClientToken":"","Language":"","CNode":{"PCode":"CJFQ","SMode":"","OperateT":""},"QNode":{"SelectT":"","Select_Fields":"","S_DBCodes":"","QGroup":[],"OrderBy":"OTA|DESC","GroupBy":"","Additon":""}}',
'displaymode': '1',
'pageindex': str(page+1),
'pagecount': '21',
'index': '1'
}
html = requests.post(url = 'https://navi.cnki.net/knavi/Common/Search/Journal', data = data, headers = headers).text # 发起请求
# 若触发反爬虫,则继续请求该网页
while html=="":
html = requests.post(url = 'https://navi.cnki.net/knavi/Common/Search/Journal', data = data, headers = headers).text
print('开始爬第%d页的url' % (page+1))
soup = BeautifulSoup(html, 'html.parser')
x = soup.find_all(attrs={"target": "_blank"})
for i in x:
link = 'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=GGYY'
new_link = re.sub('GGYY', i['href'][-4:], link)
urls.append(new_link)
with open(urls_path,'w',newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(urls) #多行写入
print('已存下%d条url' % (len(urls)))
但是但是但是!因为已经对着八千多页爬了好多次,可能触发了好几层反爬虫机制,所以根本没法爬了。试过朋友的useragent不行,查到了这个库,可以提供随机的useragent:https://blog.csdn.net/qq_38251616/article/details/86751142,但是其实还是不太行,经常会断连。只能借同学的电脑把八千多页的源代码爬下来存在本地,直接解析本地的html,不过这样快很多,而且就算解析下来漏了什么也很方便重新解析。下面是完整代码。
from bs4 import BeautifulSoup
import requests
import re
import csv
from lxml import etree
import pandas as pd
headers = {'User-Agent' : ''} #这里填自己浏览器的User-Agent
def save_urls(page_nums, urls_path):
urls = []
for page in range(page_nums):
data = {
'SearchStateJson': '{"StateID":"","Platfrom":"","QueryTime":"","Account":"knavi","ClientToken":"","Language":"","CNode":{"PCode":"CJFQ","SMode":"","OperateT":""},"QNode":{"SelectT":"","Select_Fields":"","S_DBCodes":"","QGroup":[],"OrderBy":"OTA|DESC","GroupBy":"","Additon":""}}',
'displaymode': '1',
'pageindex': str(page+1),
'pagecount': '21',
'index': '1'
}
html = requests.post(url = 'https://navi.cnki.net/knavi/Common/Search/Journal', data = data, headers = headers).text # 发起请求
# 若触发反爬虫,则继续请求该网页
while html=="":
html = requests.post(url = 'https://navi.cnki.net/knavi/Common/Search/Journal', data = data, headers = headers).text
print('开始爬第%d页的url' % (page+1))
soup = BeautifulSoup(html, 'html.parser')
x = soup.find_all(attrs={"target": "_blank"})
for i in x:
link = 'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=GGYY'
new_link = re.sub('GGYY', i['href'][-4:], link)
urls.append(new_link)
with open(urls_path,'w',newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(urls) #多行写入
print('已存下%d条url' % (len(urls)))
def read_urls(urls_path):
urls = []
f = open(urls_path, 'r', encoding='utf-8')
reader = csv.reader(f)
for i in reader:
for url in i:
urls.append(url)
f.close()
return urls
def save_htmls(urls, html_path):
count = 0
try:
for url in urls:
headers = {'User-Agent' : ''}
html = requests.get(url=url, headers=headers).text
while html=="":
html = requests.get(url=url, headers=headers).text
with open(html_path + '/%d.html'% count,'w',encoding='utf-8') as f:
f.write(html)
count += 1
print('已存下第%d本期刊的html' % count)
except Exception as e:
print(e)
print('htmls.csv文件写入完成')
def get_details(url, html):
root = etree.HTML(html)
data_dict = {}
data_dict['URL'] = url
data_dict['期刊名称(中)'] = root.xpath("//h3[@class='titbox']//text()")[0].split('\n ')[1]
en_name = re.findall(re.compile('(.*?)
(.*?)
(.*?)',re.DOTALL), html)
data_dict['期刊名称(英)'] = en_name[0][1] if len(en_name)!=0 else ''
data_dict['期刊数据库'] = " ".join(root.xpath("//p[@class='journalType']/span/text()"))
data_dict['曾用刊名'] = root.xpath("//p[contains(text(),'曾用刊名')]//text()")[1] if len(root.xpath("//p[contains(text(),'曾用刊名')]//text()"))==2 else ''
data_dict['主办单位'] = root.xpath("//p[contains(text(),'主办单位')]//text()")[1] if len(root.xpath("//p[contains(text(),'主办单位')]//text()"))==2 else ''
data_dict['出版周期'] = root.xpath("//p[contains(text(),'出版周期')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版周期')]//text()"))==2 else ''
data_dict['ISSN'] = root.xpath("//p[contains(text(),'ISSN')]//text()")[1] if len(root.xpath("//p[contains(text(),'ISSN')]//text()"))==2 else ''
data_dict['CN'] = root.xpath("//p[contains(text(),'CN')]//text()")[1] if len(root.xpath("//p[contains(text(),'CN')]//text()"))==2 else ''
data_dict['出版地'] = root.xpath("//p[contains(text(),'出版地')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版地')]//text()"))==2 else ''
data_dict['语种'] = root.xpath("//p[contains(text(),'语种')]//text()")[1] if len(root.xpath("//p[contains(text(),'语种')]//text()"))==2 else ''
data_dict['开本'] = root.xpath("//p[contains(text(),'开本')]//text()")[1] if len(root.xpath("//p[contains(text(),'开本')]//text()"))==2 else ''
data_dict['邮发代号'] = root.xpath("//p[contains(text(),'邮发代号')]//text()")[1] if len(root.xpath("//p[contains(text(),'邮发代号')]//text()"))==2 else ''
data_dict['创刊时间'] = root.xpath("//p[contains(text(),'创刊时间')]//text()")[1] if len(root.xpath("//p[contains(text(),'创刊时间')]//text()"))==2 else ''
data_dict['专辑名称'] = root.xpath("//p[contains(text(),'专辑名称')]//text()")[1] if len(root.xpath("//p[contains(text(),'专辑名称')]//text()"))==2 else ''
data_dict['专题名称'] = root.xpath("//p[contains(text(),'专题名称')]//text()")[1] if len(root.xpath("//p[contains(text(),'专题名称')]//text()"))==2 else ''
data_dict['出版文献量'] = root.xpath("//p[contains(text(),'出版文献量')]//text()")[1] if len(root.xpath("//p[contains(text(),'出版文献量')]//text()"))==2 else ''
data_dict['总下载次数'] = root.xpath("//p[contains(text(),'总下载次数')]//text()")[1] if len(root.xpath("//p[contains(text(),'总下载次数')]//text()"))==2 else ''
data_dict['总被引次数'] = root.xpath("//p[contains(text(),'总被引次数')]//text()")[1] if len(root.xpath("//p[contains(text(),'总被引次数')]//text()"))==2 else ''
data_dict['(2020)复合影响因子'] = root.xpath("//p[contains(text(),'(2020)复合影响因子')]//text()")[1] if len(root.xpath("//p[contains(text(),'(2020)复合影响因子')]//text()"))==2 else ''
data_dict['(2020)综合影响因子'] = root.xpath("//p[contains(text(),'(2020)综合影响因子')]//text()")[1] if len(root.xpath("//p[contains(text(),'(2020)综合影响因子')]//text()"))==2 else ''
try:
more = ''
for i in root.xpath("//ul[@id='evaluateInfo']//text()")[2:]:
if '\n' not in i and '影响因子' not in i and '.' not in i:
more += i+'\n'
data_dict['该刊被以下数据库收录'] = re.findall(re.compile('该刊被以下数据库收录:\n(.*?)\n'), more)[0] if len(re.findall(re.compile('该刊被以下数据库收录:\n(.*?)\n'), more)) != 0 else ''
data_dict['北京大学《中文核心期刊要目总览》来源期刊'] = re.findall(re.compile('北京大学《中文核心期刊要目总览》来源期刊: \n(.*?);\n', re.DOTALL), more)[0] if len(re.findall(re.compile('北京大学《中文核心期刊要目总览》来源期刊: \n(.*?);\n', re.DOTALL), more)[0])!= 0 else ''
data_dict['期刊荣誉'] = re.findall(re.compile('期刊荣誉:\n(.*?);\n', re.DOTALL), more)[0] if len(re.findall(re.compile('期刊荣誉:\n(.*?);\n', re.DOTALL), more)) != 0 else ''
except:
data_dict['该刊被以下数据库收录'] = ''
data_dict['北京大学《中文核心期刊要目总览》来源期刊'] = ''
data_dict['期刊荣誉'] = ''
return data_dict
def parse_htmls(html_path, urls):
data_list = []
for i in range(len(urls)):
soup = BeautifulSoup(open(html_path + '\\' + str(i) + '.html',encoding='utf-8'),features='html.parser')
html = str(soup)
data_list.append(get_details(urls[i], html))
print('已解析完第%d本期刊的所有概要信息' % (i+1))
print('已解析完%d本期刊的所有概要信息' % len(urls))
return data_list
def save_file(data_list, csv_name, xls_name):
with open(csv_name, 'w', encoding='utf-8', newline='') as f:
title = data_list[0].keys()
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(data_list)
print('csv文件写入完成')
df = pd.read_csv(csv_name)
df = df.to_excel(xls_name)
print('excel文件写入完成')
def main():
urls_path = 'C:\\学习资料\\大二下\\python数据分析\\spider\\urls.csv'
save_urls(406, urls_path) #存下406页中8516条url
urls = read_urls(urls_path) #读取本地所有url
html_path = 'C:\\学习资料\\大二下\\python数据分析\\spider\\htmls'
save_htmls(urls, html_path) #存下8516本期刊的源代码
data_list = parse_htmls(html_path, urls) #从本地读取每一本期刊的源代码并解析想要的概要信息
csv_name = 'C:\\学习资料\\大二下\\python数据分析\\spider\\cnki_data.csv'
xls_name = 'C:\\学习资料\\大二下\\python数据分析\\spider\\cnki_data.xls'
save_file(data_list, csv_name, xls_name) #将解析完的信息存入本地
if __name__ == '__main__':
main()
最后放几个写作业时候的参考资料:
xpath:https://www.cnblogs.com/jpfss/p/10410506.html
bs4:https://cuiqingcai.com/1319.html
正则表达式:https://blog.csdn.net/c20081052/article/details/80920073