一种基于多图注意力机制的虚假新闻检测方法
一 论文目标
对于社交媒体(推特)上发布的新闻,检测其真实性。只需要给定原始的推特文本和对应的转推用户序列,预测推特新闻是否是假的,并且同时生成做出该判断的解释(即根据那些特征断定该推特是假的)。
二 具体方法

本文提出的CGAN总共分为5个部分,分别是:1)用户特征构造;2)原始推特本文编码;3)用户传播序列表示;4)图传播表示;5)双重注意力机制
1)用户特征提取
这部分的作用是对用户进行量化,主要涉及到的特征是统计特征和一些二元特征。
| feature1 | 用户自我描述中的单词数。 |
|---|---|
| feature2 | 用户的昵称的单词数。 |
| feature3 | 用户粉丝数。 |
| feature4 | 用户的关注数。 |
| feature5 | 用户发表的文章数。 |
| feature6 | 距离用户发表第一篇文章到现在经过的时间。 |
| feature7 | 用户是否是认证的。 |
| feature8 | 用户是否允许地理定位。 |
| feature9 | 原始推文发表时间与用户转发时间的间隔。 |
| feature10 | 用户与原始推特的传播路径长度。 |
根据这10个特征构成了用户的基础特征
2)原始推特嵌入
不难理解,本文的任务是检测虚假新闻,即对应NLP中的文本分类,那这部分的作用是对原始的推特文本编码,用于后续进行分类。
首先输入使用one-hot表示。由于不同的推特长度(词数)可能不一样,因此需要把所有文本padding到相同的长度,不足的补零,长度设置为m。
E = [e1, e2, …, em] ∈ Rm
这里面em是第m个单词的独热。目标的词向量嵌入表记为
V = [v1, v2, …, vm] ∈ Rd×m
其中d是词向量维度。词向量表示生成如下:
V = tanh(WwE + bw)
其中W是学习参数,b是偏置项。
然后使用GRU根据词向量V学习单词序列表示。即
st = GRU(vt), t ∈ {1, …, m},
因此,原文档表示为
S = [s1, s2, …, sm] ∈ Rd×m.
这里面d是词向量维度,m是单词数。
3)用户传播表示
本文使用推特转发路径上的用户的特征作为依据来判断源推特是否是虚假的。其背后的思想是:真实的新闻的传播用户与虚假新闻的传播用户具有不同的用户特征。本文分别使用GRU和CNN来学习用户的传播表示。
输入是转发推特Si的用户的特征序列,记为PF(si)=
3.1)GRU的传播表示
给定传播链上用户的特征向量序列PF(Si)=<…,xt,…>,把用户传播序列当成文本序列,用GRU学习传播表示如下:
ht = GRU(xt), t ∈ {1, …, n}
对每个输出求算数平均,可以得到最终的传播表示
y h = 1n P nt=1 ht.
这里采用了文本的处理方法来学习用户的传播表示,猜想是因为判断新闻的真实性是跟传播用户的先后有关,即这是一种时间上的关系。不妨设想一下,一个虚假新闻的传播,一般最开始都是由一些有异常的用户进行转发开始的。
3.2)CNN的传播表示
这部分采用一个一维的卷积来学习传播特征PF(Si)。
每次考虑λ个连续的用户,因此用一个λ×v的卷积核(v是用户特征的维度,如前面第一部分内容所示)。
因此输出表示向量如下:
C = ReLU(Wf · Xt:t+λ−1 + bf )
其中Wf是学习参数, bf是偏置项。Xt:t+λ−1则表示从第t到第t+λ−1个用户的特征(也就是一个卷积核窗口内的用户)。
- 图感知传播表示
背后思想:用户之间带有某些特征的交互也许能够为虚假信息的检测提供线索。
因为不知道用户之间的真实关系,所以这里把全部用户看作节点,构建全连接图,边的权重设置为用户之间特征的余弦相似度(A矩阵)。然后在图上用了一个2层的GCN。
H(l+1) = ρ( ˜AH(l)Wl),
这部分其实是对转发每篇文章的用户单独构图,每个图之间的用户是全连接的,因此有n*(n-1)/2条边,但是n是有限的,所以运算量还算可控。
5)双重注意力机制
该模块是提供可解释性的关键模块。可解释性的原理其实也就是学习出注意力权重矩阵,然后看哪一部分权重较大,也就说明那一部分更大程度地促成了判断结果。本文学习了两个注意力权重,分别来观察source tweet (S=[s1,s2,…,sm])和user propagation embeddings(C=[c1,c2,…,cn−λ+1])之间的相互影响,以及source tweet 和 graph-aware interaction embeddings (G=[g1,g2,…,gn])之间的相互影响。有了source tweet 与 user propagation 和 graph-aware interaction之间的影响因子,就可以通过观察注意力权重来提供解释性。
两种注意力分别是
- source tweet 与 graph-aware interaction users (source-interaction co-attention)(也就是S与G)
- source tweet 与 propagated users (source-propagation co-attention)(也就是S与C)
由于两种注意力基本思路一致,因此稍加解释一下S&&G的注意力算法即可。
F是一个mxn的相似度矩阵,其实就是把m个单词与n个用户关联起来。Ws是kxd的矩阵,S是dxm的矩阵,那么Ws.S可以得到kxm的矩阵,相当于把原始的d维词嵌入变成k维的嵌入;同理,Wg是kxg,G是gxn,Wg.G;得到kxn,相当于g维的嵌入变成k维的;然后这部分再乘以F转置,就从kxn变成kxm了。
综上所述,通过相似度矩阵F这个特征,第一个等式Hs就是将source空间和interaction空间都变换到一个统一的source空间然后相加。
同理第二个等式Hg就是将source空间和interaction空间都变换到一个统一的interaction空间然后相加。
然后通过这两个映射关系就可以计算source words和interaction users之间的注意力权重:
这里as∈R1×m是每个单词的注意力权重,ag∈R1×n对应每个用户的注意力权重。whs,whg∈R1×k是学习参数。
最终,学到的注意力权重与原表示相乘,就得到了注意力之后的表示:
这里计算user propagation 与 source 之间的注意力,没有使用RNN-based方法学到的propagation表示(gru本身就是有长短期记忆,相当于有注意力),只用了CNN-based方法学到的propagation表示。
6)预测部分
将上述用到的各种嵌入拼接到一块,丢进MLP里面进行二分类即可,即
y = softmax(ReLU(fWf + bf ))
其中
gru-base 的表示为h,是直接拼接作为输入的。
因此最后的优化目标就是:
L(Θ) = −y log(ˆy1) − (1 − y) log(1 − yˆ0)
三 实验部分
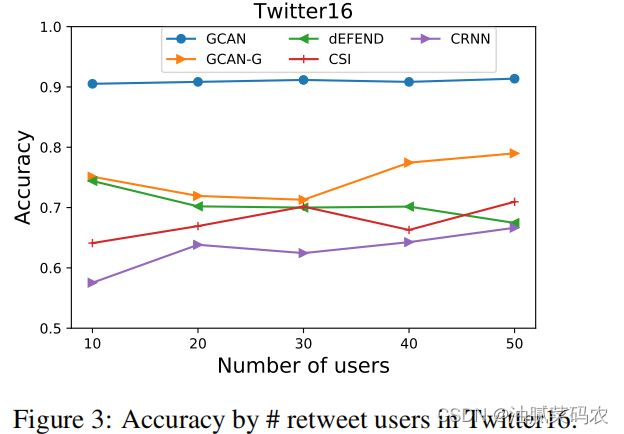
只需要用10个用户的序列即可实现90%的精度,用于早期检测,对于数据量不是很够或者实效性要求高的场景来说优势比较明显了

从图中可以看出,模型根据”breaking“,”strict“等单词判定虚假新闻,而根据”confirmed“和”irrelevant“等单词判定为真实新闻。
作者解释这符合人们的直觉,因为在现实中虚假新闻通常喜欢使用这种dramatic和obscure的单词(也就是我们常说的标题党),而真实新闻更注重于已确认的事实。
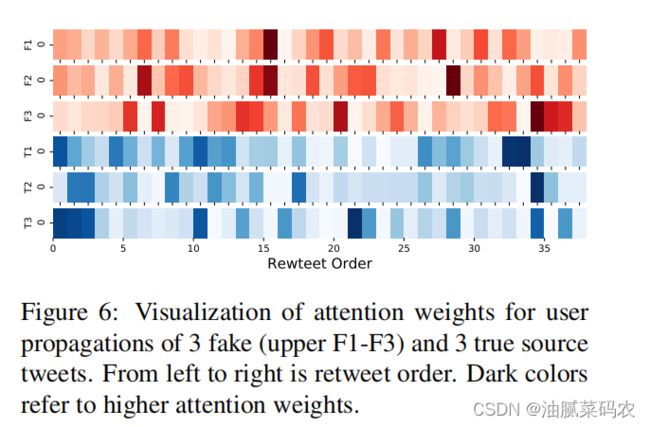
F1-F3是三个假的新闻,T1-T3是三个真的新闻。颜色越深表示注意力权重越大。横轴表示转推时序。
通过图中结果,作者得出如下分析:
结果表明,为了判断一个推特是否是假的,应该首先检验比较早传播这个消息的用户的特征。虚假新闻的用户特征方面的证据在整个传播链中可能是均匀分布的。
可以看出传播链中可疑用户的特点:没有验证的,新号,个人描述少的
四 总结与收获
- 双重注意力提供可解释性
- 模型较复杂,简单来说就是堆叠各种模型,因此在特征方面要求就少了。较少特征就可以实现不错的精度。