ML-Agents 创建一个新的训练环境 【ML-Agents 官方文档翻译(ML-Agent 1.9.1,Unity 2018-2020)】
Making a New Learning Environment
本教程将从头开始创建一个 Unity Environment,以用于训练 Reinforcement Learning(强化学习)Agent。
建议先阅读Getting Started,以便理解构建 Environment 用到的原理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZA9IexFG-1637221255733)(images/mlagents-NewTutSplash.png)]
在本节示例中,我们将创建一个 Agent 控制处于平板上的小球。
训练的目标是:控制球滚动向一个随机放置的立方体,同时避免球从平台上掉落。
Overview
在 Unity 项目中使用 ML-Agents Toolkit 需遵从以下基本步骤:
- 创造一个 Environment 用于放置你的 Agent。 Environment 可以是包含一些对象的简单物理模拟,也可是一个的游戏或者生态系统。
- 实现你的 Agent 子类。 Agent 子类通过代码定义: Agent 如何观察环境(observe it’s environment)、如何执行规定的动作、以及如何计算用于训练的奖励。你还可以通过实现一些可选的方法,在 Agent 完成任务或任务失败时重置 Agent。
- 将 Agent 子类添加到适当的 GameObjects 中,通常是指场景中 Agent 所代表的对象。
**注意:**如果您不熟悉 Unity, 而本教程中对Unity Editor 的操作解释不够充分时,请参阅 Unity 手册中的 Learning the interface。
如果您尚未安装,请遵循 installation instructions
Set Up the Unity Project
首先我们要创建一个新的 Unity 项目并将 ML-Agents Assets 导入:
- 启动 Unity Hub 并创建一个名为 “RollerBall” 的 3D 项目。
- 将 ML-Agents Unity Package 添加到的项目中。(参考导入 ML-Agents Unity Package)
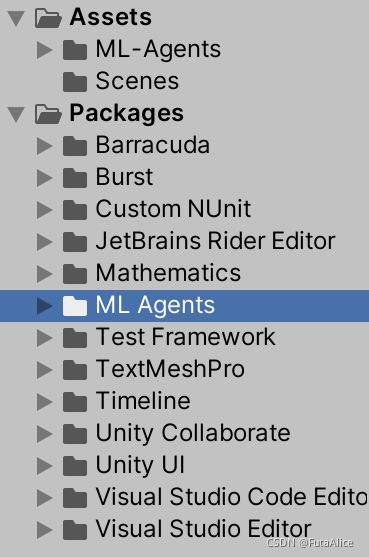
导入完成后 Unity 的 Project 窗口应包含以下 Assets:
Create the Environment
接下来,创建一个简单的场景作为 Environment,场景包含:
- 一个Plane,作为地板让 Agent 在之上移动
- 一个作为 Agent 目标的 Cube
- 以及作为 Agent 自身的 Sphere
Create the Floor Plane
- 在 Hierarchy 窗口中右键单击,选择
3D Object -> Plane。 - 将新建的 GameObject 命名为 “Floor”。
- 选中 Floor 以在 Inspector 编辑其属性。
- 设置 Position =
(0, 0, 0), Rotation =(0, 0, 0), Scale =(1, 1, 1)。

Add the Target Cube
- 在 Hierarchy 窗口中右键单击,选择
3D Object -> Cube。 - 将新建的 GameObject 命名为 “Target”。
- 选中 Target 以在 Inspector 编辑其属性。
- 设置 Position =
(3, 0.5, 3), Rotation =(0, 0, 0), Scale =(1, 1, 1)。

Add the Agent Sphere
- 在 Hierarchy 窗口中右键单击,选择
3D Object -> Sphere。 - 将新建的 GameObject 命名为 “RollerAgent”。
- 选中 Target 以在 Inspector 编辑其属性。
- 设置 Position =
(0, 0.5, 0), Rotation =(0, 0, 0), Scale =(1, 1, 1)。
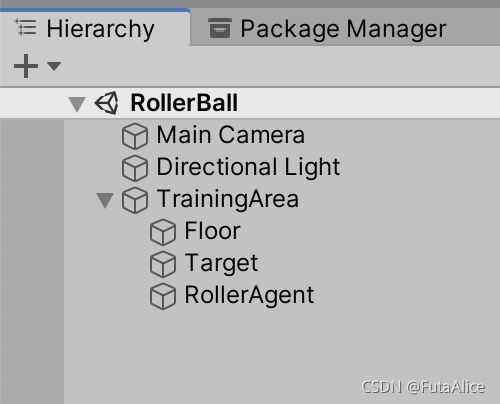
Group into Training Area
将 Floor,Target 和 RollerAgent 作为同一个空的 GameObject 的子对象。这将简化我们的一些后续步骤。
这样做:
- 在 Hierarchy 窗口中右键单击,点击
Create Empty创建一个空的 GameObject,命名为 “TrainingArea”。 - 设置 Position =
(0, 0, 0), Rotation =(0, 0, 0), Scale =(1, 1, 1)。 - 在 Hierarchy 窗口中选中 Floor、Target 和 RollerAgent,拖动到 TrainingArea 下。
Implement an Agent
先给 Agent 添加一个 Script:
- 选中 RollerAgent 查看 Inspector 窗口。
- 点击 Add Component。
- 在列表中选择 New Script (在底部)。
- 将脚本也命名为 “RollerAgent”。
- 点击 Create and Add。
然后,编辑 RollerAgent Script:
-
在 Project 窗口中双击
RollerAgent以编辑脚本。 -
通过如下代码引入 ML-Agent package:
using Unity.MLAgents; using Unity.MLAgents.Sensors; using Unity.MLAgents.Actuators;然后将基类的
MonoBehaviour替换为Agent。 -
删除用不到的
Update()函数,但需保留Start()函数。
以上时将 ML-Agents 添加到任何 Unity 项目的基本步骤。
接下来,我们将添加逻辑,使用强化学习让 Agent 学会如何滚动到 Cube。
更确切地说,我们需要从 ‘Agent’ 基类扩展三个方法:
OnEpisodeBegin()CollectObservations(VectorSensor sensor)OnActionReceived(ActionBuffers actionBuffers)
我们将在下面专门的小节中逐个解释。
Initialization and Resetting the Agent
ML-Agents ToolKit 的训练过程由控制 Agent(Sphere)解决任务的 Episode 组成。
每个 Episode 都会持续到 Agent 解决任务(即到达立方体)、失败(从平台跌落)或超时(解决任务耗时太长)。
在 Episode 开始时,OnEpisodeBegin() 将被调用以设置训练环境。
场景通常以随机的方式初始化,以使 Agent 学会在各种条件下解决任务。
在这个例子中,每当 Agent(Sphere)到达目标(Cube)时,Episode 结束,目标(Cube)被移动到一个新的随机位置。
又或者 Agent 从平台跌落,Agent 会被放回平台上。
这些都在 OnEpisodeBegin() 中处理。
为了移动目标(Cube),我们需要用到它的 Transform(存储了 GameObject 的位置、方向和缩放)。
向 RollerAgent 类添加一个类型为 Transform 的公共字段,以获得 Transform 的引用。
组件的公共字段会显示在 Inspector 窗口中,允许你在 Unity 编辑器中选择使用哪个 GameObject 作为其目标。
为了重置 Agent 的速度(以及之后会施加力推动 Agent),我们需要 Rigidbody 组件的引用。
Rigidbody 常用于 Unity 的物理模拟。(参见 Unity 的完整文档:Physics)
由于刚体 Rigidbody 组件和我们的 Agent 脚本挂在同一个 GameObject 上,所以可以通过 GameObject.GetComponent 直接获取,我们可以在脚本的 Start() 方法中调用它。
至此,我们的 RollerAgent 脚本如下:
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
public class RollerAgent : Agent
{
Rigidbody rBody;
void Start () {
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
public override void OnEpisodeBegin()
{
// If the Agent fell, zero its momentum
if (this.transform.localPosition.y < 0)
{
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3( 0, 0.5f, 0);
}
// Move the target to a new spot
Target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
}
}
接下来,让我们实现 Agent.CollectObservations(VectorSensor sensor) 方法。
Observing the Environment
Agent 把我们收集到的信息发送给“脑”(神经网络),“脑”根据信息做出决策。
当训练 Agent(或使用训练过的模型) 时,数据被作为特征向量被送入神经网络。
要想 Agent 成功学习一个任务,我们需要提供正确的信息。
决定要收集什么信息的一个很好的经验法则是:考虑解决问题的需要什么信息。
本例中,Agent 所收集的信息包括目标的位置、Agent 自身的位置和速度。
Agent 用这些信息学习控制自身的速度,以免跌落平台。
Agent 观测的特征向量总共包含8个浮点值,实现如下:
public override void CollectObservations(VectorSensor sensor)
{
// Target and Agent positions
sensor.AddObservation(Target.localPosition);
sensor.AddObservation(this.transform.localPosition);
// Agent velocity
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
Taking Actions and Assigning Rewards
Agent 代码的最后一部分是 Agent.OnActionReceived() 方法,它接收动作并给出奖励。
Actions
为了解决向目标移动的任务,Agent(Sphere)需要能够在 x 和 z 方向上移动。
因此,Agent 动作需包含 2 个值:施加在 x 轴上的力和施加在 z 轴上的力。
(依次类推,如果我们允许 Agent 在三维空间中移动,那么动作需包含第三个值。)
RollerAgent 从 actions.ContinuousActions 数组中获取到“脑”做出的决策(要施加xy轴上的力),并调用 Rigidbody.AddForce() 两个力作用到它的 Rigidbody 组件 rBody 上:
Vector3 controlSignal = Vector3.zero;
controlSignal.x = action[0];
controlSignal.z = action[1];
rBody.AddForce(controlSignal * forceMultiplier);
Rewards
强化学习需要奖励(Reward)来表明哪些决策的优劣。
学习算法使用奖励来判断 Agent 是否做了最优的行动。
对于能够完成指定任务的 Agent,我们应该给予它奖励。
在本例中,Agent 每次到达目标(Cube)都将得到值为 1.0 的奖励。
奖励在 OnActionReceived() 中分配。
计算 Agent 和 Cube 的距离判断是否抵达目标。
当到达目标时,调用 Agent.SetReward() 分配值为 1.0 的奖励,同时调用 Agent.EndEpisode() 来标记当前 Episode 已经结束。
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition);
// Reached target
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
EndEpisode();
}
最后,如果 Agent 从平台跌落,结束当前 Episode,Agent 将在下一个 Episode 开始时重置自身:
// Fell off platform
if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
OnActionReceived()
根据上述操作和奖励逻辑,OnActionReceived() 函数的最终版本如下:
public float forceMultiplier = 10;
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// Actions, size = 2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actionBuffers.ContinuousActions[0];
controlSignal.z = actionBuffers.ContinuousActions[1];
rBody.AddForce(controlSignal * forceMultiplier);
// Rewards
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition);
// Reached target
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
EndEpisode();
}
// Fell off platform
else if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
}
注意 forceMultiplier 是类的成员变量,是在方法定义之前定义的。
forceMultiplier 是公有的,可以从 Inspector 窗口设置它的值。
Final Agent Setup in Editor
现在所有的 GameObject 和 ML-Agent 组件都已经准备就绪,是时候在 Unity Editor 中将所有内容连接起来了。
这涉及到添加和设置一些 Agent 组件的属性,以便它们与我们的 Agent 脚本兼容。
- 选中 RollerAgent GameObject 查看它的 Inspector 窗口。
- 将 Target GameObject 拖拽到 RollerAgent 脚本的
Target字段。 - 点击 Add Component 按钮,添加一个
Decision Requester脚本。
将 Decision Period 值设为10。(关于 Decision 的更多详细信息,参考 the Agent documentation) - 点击 Add Component 按钮,添加一个
Behavior Parameters脚本,并给字段赋值:Behavior Name: RollerBallVector Observation -> Space Size= 8Actions -> Continuous Actions= 2
RollerAgent 的 Inspector 窗口现在应该是这样的:

现在可以在训练之前测试环境了。
Testing the Environment
接着来测试一下我们搭建的环境,使用键盘控制 Agent 是个不错的办法。
为此,需要扩展 RollerAgent 类中的 Heuristic() 方法。
本例中,Heuristic 读取键盘方向键。
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
为了让 Agent 受键盘输入控制,需要在 RollerAgent 的 Behavior Parameters 中将 Behavior Type 设置为 Heuristic Only。(测试完成后记得改回 Default)
按下 Play 运行场景,并使用方向键移动 Agent。
确保 Unity Editor Console 窗口中没有报错,并且 Agent 在达到目标或从平台坠落时被正确的重置。
Training the Environment
训练过程与 Getting Started Guide 的讲解相同。
训练的超参数(Hyperparameter)在需要在配置文件中指定,并将该配置文件传递给 mlagents-learn 程序。
在 config/ 目录下创建一个新的 rollerball_config.yaml,并包含以下超参数值:
behaviors:
RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
超参数的配置说明见 [the training configuration file documentation](Training Configuration-File.md)。
由于本例训练环境非常简单的,只有少量的输入和输出,所以使用很小的 batch_size 和 buffer_size 大大加快了训练速度。
然而,如果给环境引入更多的复杂性或改变奖励或 Observation 函数,您可能还会发现训练在不同的超参数值下表现得更好。
除了设置这些超参数值,Agent 的 DecisionFrequency 参数对训练时间和是否能训练成功也有很大的影响。
更大的 Decision Period 值减少了训练算法需要考虑的决策数量,在当前的简单环境,可以加快训练速度。
命令行启动 mlagents-learn:
mlagents-learn config/rollerball_config.yaml --run-id=RollerBall
待看到提示 Start training by pressing the Play button in the Unity Editor 后,点击 Unity Editor 的 Play 按钮开始训练。
要在训练期间监视 Agent 表现的统计数据,可以使用 TensorBoard。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MqKWxrdV-1637221255734)(images/mlagents-RollerAgentStats.png)]
特别是,cumulative_reward 和 value_estimate 统计数据代表 Agent 完成任务的情况。
本例中,Agent 可以获得的最大奖励是1.0,所以当 Agent 总能成功解决问题时,这些统计数据就会趋近于这个值。
Optional: Multiple Training Areas within the Same Scene
在 example environments 中,TrainingArea 在场景中实例化了有多个副本。
这是为了加速训练,允许环境同时收集更多的经验。
这可以通过实例化许多具有相同 Behavior Name 的 Agent 来实现。
注意,我们已经已经创建的 TrainingArea 游戏对象,RollerAgent.cs 中采集的特征向量不依赖世界坐标,这简化了将 TrainingArea 并行化的操作。
使用以下步骤实例化多个并行的 RollerBall 环境:
- 将 TrainingArea GameObject 及其子对象拖到 Assets 浏览器中,将其变成一个 Prefab。
- 将 Prefab 拖到场景中,实例化多个副本,调整定位,使它们不会相互重叠。