snntorch_P3: 脉冲神经网络与其他经典算法的对比
大家好,已经近一年没有更新过了,现在已经研二啦,这一年做过横向,搞过算法,学过java,对前途也有点迷茫,就业也是真的难,但是大环境如此也没有办法。我们能做的还是要不断精进增长本事,下面我们开始正题!
我的研究方向是基于脉冲神经网络的飞行器变体控制,具体指的是飞行器在高空飞的过程中高度、速度、攻角等的变化会导致气动特性的变化,我要做的事情就是在每一个飞行状态下选择一个合适的飞行器变形率(选择的是变后掠角)。如果我们选择高度、速度、攻角作为输入,输出选择变形率,这样就可以将若干个数据扔到神经网络训练,由于变形率我看的一些论文以及考虑数据集构建的难易程度,变形率设置成了离散的值,所以归根到底是一个分类问题。
大家点进来的应该都是研究方向和脉冲神经网络相关的,脉冲神经网络的一个最大优势就是采用脉冲序列能耗低,那么跟谁比,低多少呢?所以我目前的思路是采用几种经典的网络算法实现一下,包括BP(采用遗传算法优化寻找初始好的权重)、SVM、RBF、决策树、CNN,然后和脉冲神经网络的结果作为对比,在确保脉冲神经网络性能优秀的条件下,量化的计算出能耗能少多少,这就是一个目前的思路。
目前的进度是,数据集建造好了,并用遗传算法优化的BP神经网络和支持向量机(SVM)实现了,下一步RBF、决策树、CNN,脉冲神经网络调整还差一点,这些将于近期展示,并会展示如何量化计算神经网络的能量消耗。
那么本期就展示数据集和BP、SVM的实现。
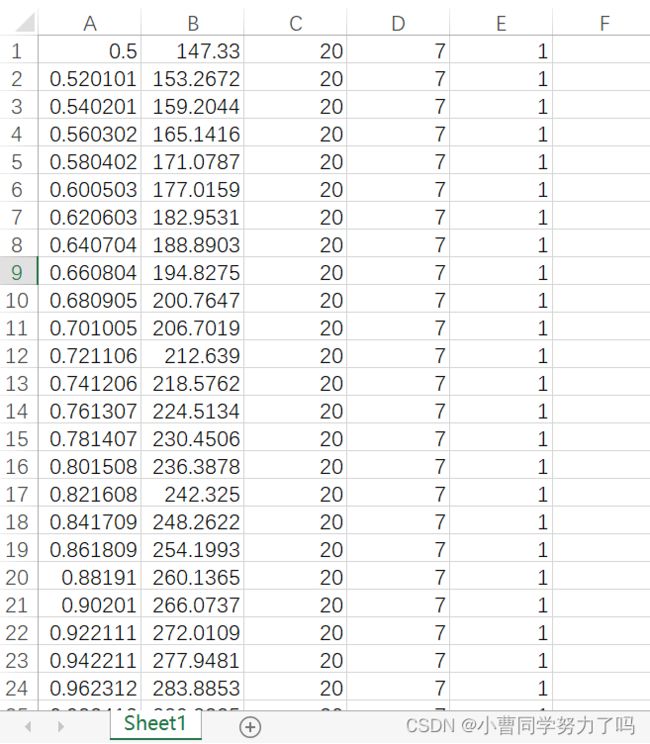
首先是数据集,每一列的数据分别是马赫数(Ma)、速度(m/s)、高度(km)、攻角(°)、变形率类别(理解为label即可,共计6类),如果对此研究感兴趣,可以联系获取数据集!目前只是一个很初步的版本。

然后是BP和SVM两种方法的实现,参考B站大佬的视频(UP主:阿飞_Y),这位大佬的代码是matlab的,主要用到了机器学习的工具箱,好久没用matlab做机器学习了,真的好用直白!后附源代码。
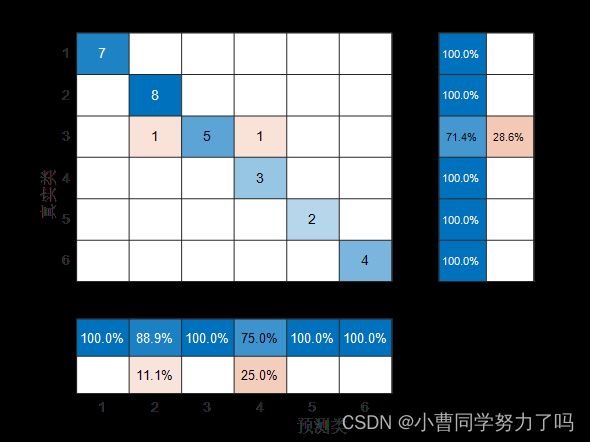
基于遗传算法优化的BP神经网络分类预测:




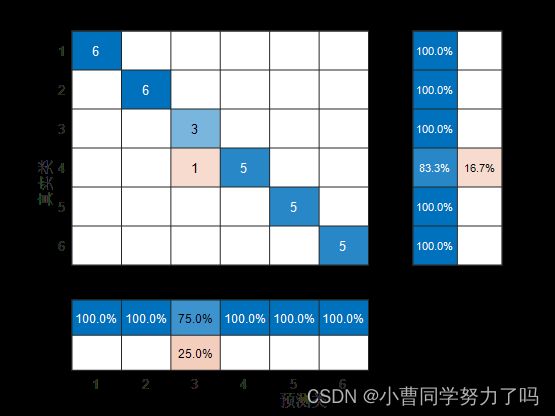
SVM分类预测:



源代码:(大家可以改为自己的数据集试一试,作为自己研究发向的结果对比)
遗传算法优化BP神经网络:
(遗传算法这块需要另外调用一个包,大家可以去github链接https://github.com/Time9Y/Matlab-Machine下载源代码)(SVM可直接运行)
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('a.xls');
%% 划分训练集和测试集
temp = randperm(200);
P_train = res(temp(1: 170), 1)';
T_train = res(temp(1: 170), 5)';
M = size(P_train, 2);
P_test = res(temp(170: end), 1)';
T_test = res(temp(170: end), 5)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
t_train = ind2vec(T_train);
t_test = ind2vec(T_test );
%% 建立模型
S1 = 5; % 隐藏层节点个数
net = newff(p_train, t_train, S1);
%% 设置参数
net.trainParam.epochs = 1000; % 最大迭代次数
net.trainParam.goal = 1e-6; % 设置误差阈值
net.trainParam.lr = 0.01; % 学习率
%% 设置优化参数
gen = 50; % 遗传代数
pop_num = 5; % 种群规模
S = size(p_train, 1) * S1 + S1 * size(t_train, 1) + S1 + size(t_train, 1);
% 优化参数个数
bounds = ones(S, 1) * [-1, 1]; % 优化变量边界
%% 初始化种群
prec = [1e-6, 1]; % epslin 为1e-6, 实数编码
normGeomSelect = 0.09; % 选择函数的参数
arithXover = 2; % 交叉函数的参数
nonUnifMutation = [2 gen 3]; % 变异函数的参数
initPop = initializega(pop_num, bounds, 'gabpEval', [], prec);
%% 优化算法
[Bestpop, endPop, bPop, trace] = ga(bounds, 'gabpEval', [], initPop, [prec, 0], 'maxGenTerm', gen,...
'normGeomSelect', normGeomSelect, 'arithXover', arithXover, ...
'nonUnifMutation', nonUnifMutation);
%% 获取最优参数
[val, W1, B1, W2, B2] = gadecod(Bestpop);
%% 参数赋值
net.IW{1, 1} = W1;
net.LW{2, 1} = W2;
net.b{1} = B1;
net.b{2} = B2;
%% 模型训练
net.trainParam.showWindow = 1; % 打开训练窗口
net = train(net, p_train, t_train); % 训练模型
%% 仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test );
%% 数据反归一化
T_sim1 = vec2ind(t_sim1);
T_sim2 = vec2ind(t_sim2);
%% 性能评价
error1 = sum((T_sim1 == T_train)) / M * 100 ;
error2 = sum((T_sim2 == T_test )) / N * 100 ;
%% 数据排序
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
%% 优化迭代曲线
figure
plot(trace(:, 1), 1 ./ trace(:, 2), 'LineWidth', 1.5);
xlabel('迭代次数');
ylabel('适应度值');
string = {'适应度变化曲线'};
title(string)
grid on
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['准确率=' num2str(error1) '%']};
title(string)
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比'; ['准确率=' num2str(error2) '%']};
title(string)
grid
%% 混淆矩阵
figure
cm = confusionchart(T_train, T_sim1);
cm.Title = 'Confusion Matrix for Train Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
figure
cm = confusionchart(T_test, T_sim2);
cm.Title = 'Confusion Matrix for Test Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
SVM:
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('a.xls');
%% 划分训练集和测试集
temp = randperm(200);
P_train = res(temp(1: 170), 1)';
T_train = res(temp(1: 170), 5)';
M = size(P_train, 2);
P_test = res(temp(170: end), 1)';
T_test = res(temp(170: end), 5)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input );
t_train = T_train;
t_test = T_test ;
%% 转置以适应模型
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
%% 创建模型
c = 10.0; % 惩罚因子
g = 0.01; % 径向基函数参数
cmd = ['-t 2', '-c', num2str(c), '-g', num2str(g)];
model = svmtrain(t_train, p_train, cmd);
%% 仿真测试
T_sim1 = svmpredict(t_train, p_train, model);
T_sim2 = svmpredict(t_test , p_test , model);
%% 性能评价
error1 = sum((T_sim1' == T_train)) / M * 100;
error2 = sum((T_sim2' == T_test )) / N * 100;
%% 数据排序
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['准确率=' num2str(error1) '%']};
title(string)
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比'; ['准确率=' num2str(error2) '%']};
title(string)
grid
%% 混淆矩阵
figure
cm = confusionchart(T_train, T_sim1);
cm.Title = 'Confusion Matrix for Train Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
figure
cm = confusionchart(T_test, T_sim2);
cm.Title = 'Confusion Matrix for Test Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';