【项目实战】使用PyTorch预测汽车从A点到B点的消耗,在 PyTorch 中构建完整的深度学习管道
新人博主,多多支持
本文由 EasyAI 原创,首发于 CSDN
⌚️ 欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
未来很长,值得我们全力奔赴更美好的生活✋
了解如何在 PyTorch 中构建完整的深度学习管道
介绍
近期国际油价油价飞涨,国内成品油零售价格也将再创新高,当你抬头看的油价时候,你有没有注意到在网上,您的汽车从 A 点到 B 点应该花多少油费,这些数字几乎与现实不符?
在本文中,我想开发一个简单的模型,该模型可以预测汽车的效率(或消耗),以单加仑 (MPG) 行驶的英里数来衡量。
这些都将使用 PyTorch 在 Python 中完成。
数据集
我们将在这个项目中使用的数据集是一个里程碑式的数据集,来自 UCI 存储库的 Auto MPG 数据集。它由 9 个特征组成,包含 398 条记录。具体而言,变量名称及其类型如下:
- mpg: continuous
- cylinders: multi-valued discrete
- displacement: continuous
- horsepower: continuous
- weight: continuous
- acceleration: continuous
- model year: multi-valued discrete
- origin: multi-valued discrete
- car name: string (unique for each instance)
开始
首先,我们加载数据集并适当地重命名列,na_values 属性用于让pandas识别‘?’类型的数据应该被视为null。
import pandas as pd
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
col_names = ['MPG','Cylinders','Displacement','Horsepower','Weight','Acceleration','Model_Year','Origin']
df = pd.read_csv(url, names = col_names, na_values = '?', comment = '\t', sep = ' ', skipinitialspace = True)
现在使用 df.head() 显示数据集。
| index | MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model_Year | Origin |
|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130.0 | 3504.0 | 12.0 | 70 | 1 |
| 1 | 15.0 | 8 | 350.0 | 165.0 | 3693.0 | 11.5 | 70 | 1 |
| 2 | 18.0 | 8 | 318.0 | 150.0 | 3436.0 | 11.0 | 70 | 1 |
| 3 | 16.0 | 8 | 304.0 | 150.0 | 3433.0 | 12.0 | 70 | 1 |
| 4 | 17.0 | 8 | 302.0 | 140.0 | 3449.0 | 10.5 | 70 | 1 |
使用 df.describe() 函数,我们可以显示数据集的一些基本统计信息,以开始了解我们将找到哪些值。
| index | MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model_Year | Origin |
|---|---|---|---|---|---|---|---|---|
| count | 398.0 | 398.0 | 398.0 | 392.0 | 398.0 | 398.0 | 398.0 | 398.0 |
| mean | 23.514572864321607 | 5.454773869346734 | 193.42587939698493 | 104.46938775510205 | 2970.424623115578 | 15.568090452261307 | 76.01005025125629 | 1.5728643216080402 |
| std | 7.815984312565782 | 1.7010042445332119 | 104.26983817119591 | 38.49115993282849 | 846.8417741973268 | 2.757688929812676 | 3.697626646732623 | 0.8020548777266148 |
| min | 9.0 | 3.0 | 68.0 | 46.0 | 1613.0 | 8.0 | 70.0 | 1.0 |
| 25% | 17.5 | 4.0 | 104.25 | 75.0 | 2223.75 | 13.825000000000001 | 73.0 | 1.0 |
| 50% | 23.0 | 4.0 | 148.5 | 93.5 | 2803.5 | 15.5 | 76.0 | 1.0 |
| 75% | 29.0 | 8.0 | 262.0 | 126.0 | 3608.0 | 17.175 | 79.0 | 2.0 |
| max | 46.6 | 8.0 | 455.0 | 230.0 | 5140.0 | 24.8 | 82.0 | 3.0 |
否则,我们可以使用 df.info() 来查看是否有空值,并找出我们变量的类型。
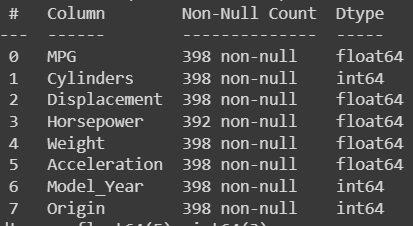
我们首先看到 Horsepower 特征包含空值,因此我们可以开始从数据集中删除与那些值对应的记录并重置数据帧索引,如下所示。
df = df.dropna()
df = df.reset_index(drop = True)
现在如果我们去打印 l e n ( d f ) → 392 len(df) → 392 len(df)→392,因为我们已经消除了行。
接下来要做的是将数据集拆分为训练集和测试集。我们使用一个非常有用的 sklearn 函数来执行此操作。然后让我们保存 df_train.describe().transpose() 表,因为我们需要一些统计员对某些特征进行预处理。
from sklearn import model_selection
df_train, df_test = model_selection.train_test_split(df, train_size = 0.8, random_state = 42)
train_stats = df_train.describe().transpose()
train_stats
train_stats :
| index | count | mean | std | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|---|---|---|
| MPG | 313.0 | 23.599361022364217 | 7.956254569198131 | 9.0 | 17.0 | 23.0 | 30.0 | 46.6 |
| Cylinders | 313.0 | 5.482428115015974 | 1.700446165652984 | 3.0 | 4.0 | 4.0 | 8.0 | 8.0 |
| Displacement | 313.0 | 195.51757188498402 | 103.76656731106247 | 70.0 | 105.0 | 151.0 | 302.0 | 455.0 |
| Horsepower | 313.0 | 104.59424920127796 | 38.28366917886364 | 46.0 | 76.0 | 95.0 | 129.0 | 230.0 |
| Weight | 313.0 | 2986.1246006389774 | 841.1339570983296 | 1613.0 | 2234.0 | 2855.0 | 3645.0 | 5140.0 |
| Acceleration | 313.0 | 15.544089456869008 | 2.8178640105078543 | 8.0 | 13.5 | 15.5 | 17.3 | 24.8 |
| Model_Year | 313.0 | 76.2076677316294 | 3.6301363246299334 | 70.0 | 73.0 | 76.0 | 79.0 | 82.0 |
| Origin | 313.0 | 1.5559105431309903 | 0.8071625783380045 | 1.0 | 1.0 | 1.0 | 2.0 | 3.0 |
数值特征
我们现在要处理一些特征。我们经常将数值变量与分类变量区别对待。
要对特征进行归一化,我们需要做的就是减去特征的平均值,然后除以标准差,为此我们需要之前提取的统计数据。
numeric_cols = ['Cylinders', 'Displacement','Horsepower','Weight','Acceleration']
#Let's make a copy of original dataframe, so we dont affect original data
df_train_norm , df_test_norm = df_train.copy(), df_test.copy()
for col in numeric_cols:
mean = train_stats.loc[col,'mean']
std = train_stats.loc[col,'std']
df_train_norm.loc[:, col] = ( df_train_norm.loc[:, col] - mean) /std
df_test_norm.loc[:, col] = ( df_test_norm.loc[:, col] - mean) /std
如果我们现在将归一化特征与原始数据集中的特征进行对比,您会注意到值如何因标准化而发生变化。
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
sns.set(rc={'figure.figsize':(15.7,5.27)})
for col in numeric_cols:
fig, ax =plt.subplots(1,2)
sns.kdeplot(data=df_train_norm, x=col, ax=ax[0])
sns.kdeplot(data=df_train, x=col, ax=ax[1])
fig.show()
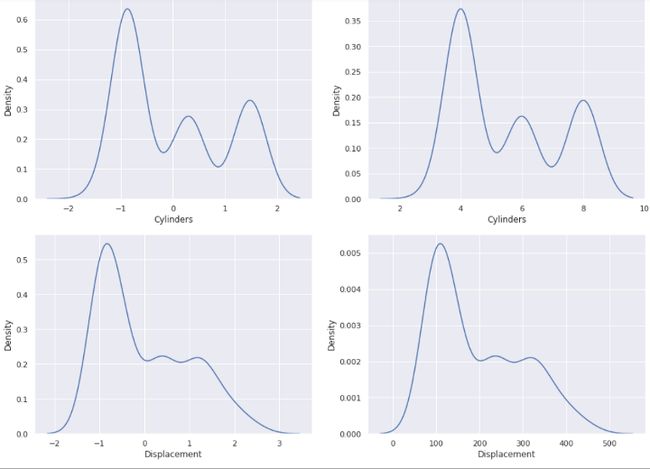
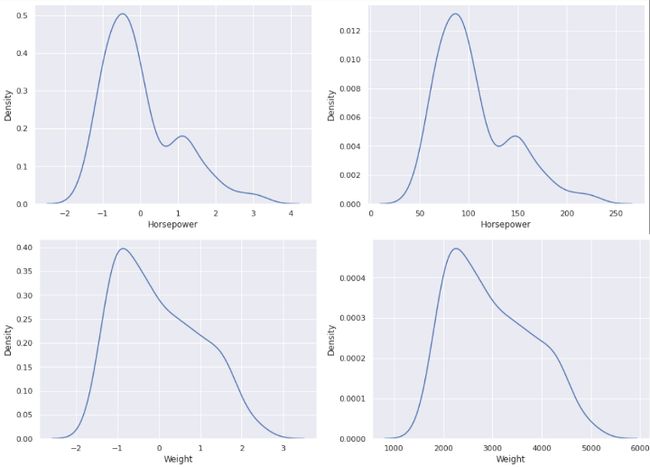
现在关于 Model_Year 特征,我们对知道特定汽车型号是哪一年制造的不感兴趣。但也许我们对间隔或箱更感兴趣。例如,如果模型是在 73’ 和76’。这些范围有点随意,您可以尝试更多,看看哪些效果最好。
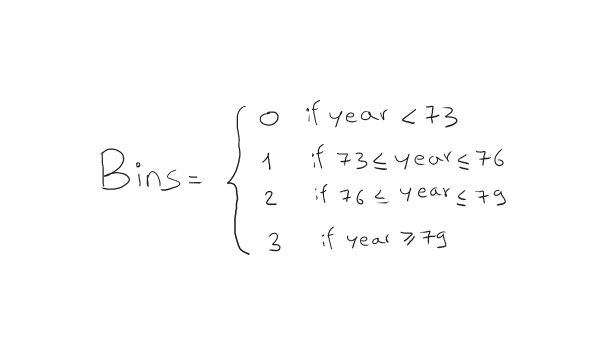
import torch
ranges = torch.tensor([73, 76, 79])
values = torch.tensor(df_train_norm['Model_Year'].values)
df_train_norm['Model_Year_Bins'] = torch.bucketize(values, ranges, right = True)
test_values = torch.tensor(df_test_norm['Model_Year'].values)
df_test_norm['Model_Year_Bins'] = torch.bucketize(test_values, ranges, right = True)
numeric_cols.append('Model_Year_Bins')
分类特征
就分类特征而言,我们基本上有两种主要做法,第一种是使用 one-hot 向量将类别(字符串)转换为只包含一个 1 的二进制向量,例如零类别将被编码为 [1 ,0,0,0],类别 1 为 [0,1,0,0] 等。
否则,我们可以使用一个嵌入层将每个类别映射到一个可以训练的“随机”向量,这样我们就可以得到一个类别的向量表示,它可以管理大量信息。
当类别的数量很大时,使用有限大小的嵌入可以有很大的优势。
在这种情况下,我们使用 one-hot 编码。
from torch.nn.functional import one_hot
n_categories = len(set(df_train_norm['Origin'])) # 获取类别数
origin_encoded = one_hot(torch.from_numpy(df_train_norm['Origin'].values % n_categories))
x_train_numeric = torch.tensor(df_train_norm[numeric_cols].values)
x_train = torch.cat([x_train_numeric, origin_encoded], 1).float()
# 测试集上的相同
origin_encoded = one_hot(torch.from_numpy(df_test_norm['Origin'].values % n_categories))
x_test_numeric = torch.tensor(df_test_norm[numeric_cols].values)
x_test = torch.cat([x_test_numeric, origin_encoded], 1).float()
让我们也提取我们必须预测的标签。
y_train = torch.tensor(df_train_norm['MPG'].values).float()
y_test = torch.tensor(df_test_norm['MPG'].values).float()
PyTorch 数据集
现在我们的数据已经准备就绪,我们创建了一个数据集,以便在训练期间更好地管理我们的批次。
from torch.utils.data import Dataset, TensorDataset, DataLoader
train_ds = TensorDataset(x_train, y_train)
batch_size = 16
torch.manual_seed(42)
train_dl = DataLoader(train_ds, batch_size, shuffle = True)
模型创建
我们构建了一个带有两个隐藏层的小型网络,一个是 8 个神经元,一个是 4 个神经元。
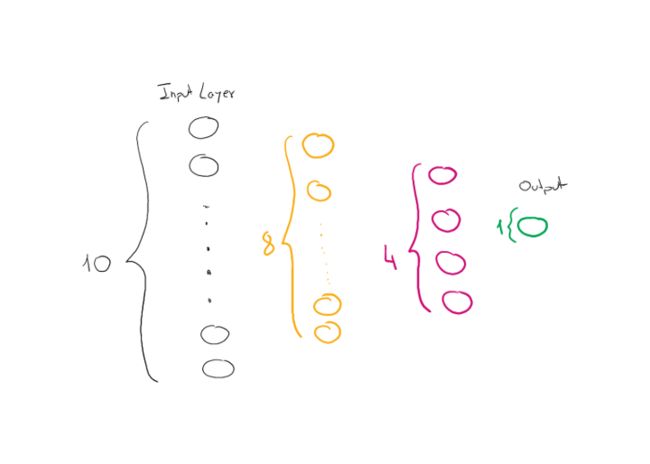
import torch.nn as nn
hidden_units = [8,4]
input_size = x_train.shape[1]
all_layers = []
for hidden_unit in hidden_units:
layer = nn.Linear(input_size, hidden_unit)
all_layers.append(layer)
all_layers.append(nn.ReLU())
input_size = hidden_unit
all_layers.append(nn.Linear(hidden_units[-1], 1))
model = nn.Sequential(*all_layers)
model
训练
现在我们定义损失函数,我们将使用 MSE 和随机梯度下降作为优化器。
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.001)
torch.manual_seed(1)
num_epochs = 200
log_epochs = 20
for epoch in range(num_epochs):
loss_hist_train = 0
for x_batch, y_batch in train_dl:
pred = model(x_batch)[:,0]
loss = loss_fn(pred, y_batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_hist_train += loss.item()
if epoch % log_epochs == 0:
print(f'Epoch {epoch} Loss {loss_hist_train/len(train_dl):.4f}')
为了预测新的数据点,我们可以将测试数据提供给模型。
with torch.no_grad():
pred = model(x_test.float())[:,0]
loss = loss_fn(pred, y_test)
print(f'Test MSE: {loss.item():.4f}')
print(f'Test MAE: {nn.L1Loss()(pred,y_test).item():.4f}')
最后的想法
在这篇简短的文章中,我们看到了如何使用 PyTorch 来解决现实生活中的问题。我们首先进行了一些 EDA 以了解我们手头上有什么样的数据集。然后我向您展示了如何区别对待数字变量和分类变量预处理阶段的变量。将列值拆分为 bin 的技术被广泛使用。然后我们看到 PyTorch 如何允许我们用很少的步骤创建自定义数据集,我们可以逐批迭代。模型层数很少,但是使用正确的损失函数和适当的优化器使我们能够快速地训练我们的网络。我希望你发现这篇文章对发现(或审查)一些 PyTorch 特性很有用。