Transformer浅析
原论文地址:
https://arxiv.org/abs/1706.03762
原解析地址:
https://jalammar.github.io/illustrated-transformer/
代码地址:
https://github.com/tensorflow/tensor2tensor
一、概述
本文内容是对《Attention Is All You Need》所提出的Transformer模型进行的简单梳理。Transformer的基础即是注意力机制(Attention),该模型由Google主导提出,起初的目的是使用注意力机制来改善NMT(Neural Machine Translation)模型,后来发现transformer在某些特定的任务场景下甚至超越了NMT的性能,因此论文取名《Attention Is All You Need》,意为仅使用Attention模块便足够了,不再需要使用RNN、CNN等复杂结构或搭配混合使用。在transformer之后,基于transformer的BERT模型在NLP领域也得到了很好的发展。本文将穿插记录《Attention Is All You Need》和《The Illustrated Transformer》两篇文章来对transformer模型进行一个简单梳理。
二、Transformer优点
- transformer相对于拥有残差结构和卷积结构的深度学习模型来说,其网络结构更加简单,并且训练和推理速度更快。(仅在P100GPUs上训练了12个小时就达到了SOTA水平)。
- 仅使用transformer在一些特定的任务上能取得更好的测试效果(语言建模,机器翻译等)。
- transformer拥有更高的并行度,并作为了谷歌云推荐的TPU(Tensor Processing Unit)推导模型。
三、Transformer结构
1.整体结构
从最高层面来看,Transformer最为一个深度学习的映射函数,接收一个输入,经过transformer进行转换,给出一个输出。(如果将其用作机器翻译功能,则是根据一种语言的输入翻译到另一种语言)。

稍微深入一些,可以看到transformer内部由两大部分组成,分别为编码器组(Encoders)和解码器组(Decoders),这一点和之前的Seq2Seq2模型保持一致。

在transformer中,编码器组包含了6个重复的编码器(Encoder),解码器组包含了6个重复的解码器(Decoder)

2.Encoder结构
在一个Encoder之中,模型结构又可拆分为两部分,一部分是自注意力机制模块(Self-Attention),另一块是前馈神经网络部分(FNN),同时也有两部分输出,分别送往下一个Encoder或者Decoder作为输入。Encoder在编码某一个特定的词时,会通过self-attention层关注(注意力)其他词给当前词的带来的影响。

3.Decoder结构
在Decoder之中,除了Encoder所具有的两层之外,还有一个Encoder-Decoder Attention层用于关注当前词的相关部分。

四、Transformer工作机制
1、首先使用词嵌入算法(embedding algorithm),将单词编码为向量形式。

只有模型最底层Encoder的self-attention模块使用了词向量嵌入编码,其他Encoder中的self-attention均是上一个Encoder的输出。

从上图可以看到,两个不同的向量x1,x2经过的是同一个Self-Attention网络,因为我们要通过Self-Attention来寻找不同的输入之间的联系。但是数据在经过FFN时只是对Self-Attention提取出的关系进行组合,因此不同的输入数据之间没有相互的依赖关系,所以经过了不同的FFN网络,这也是模型能并行执行快速训练的原因。
五、注意力机制
1.自注意力机制(self-attention)
自注意力机制即自己注意自己,在机器翻译中,即根据输入的一整段话,来发现这一段话与其中某一个词之间的联系。例如“The animal didn’t cross the street because it was too tired”这一句中的it指的是The animal还是the street呢?对于人来说很容易,对于机器来说这就是一个难题。自注意力机制就是用来解决这种问题,来确定哪些词与it具有较强的联系。下图中左边颜色越深的部分,即表示注意力机制认为的与it关联更紧密的部分。

那么自注意力机制如何能做到上述功能呢?
自注意力机制的向量解释
这一部分并不是直接对照《The Illustrated transformer》的原文进行翻译,感觉直译起来并不是那么容易理解,笔者按照自己的思路进行了解释,如有错误希望指正。
首先,为了简单起见,先从单个向量(一个单词)的自注意力机制进行理解。每一个单词首先编码成向量表示,然后分别与训练好的三个权重矩阵WQ,WK,WV相乘(在神经网络中体现为全连接层),得到各自的q,k,v向量表示(Q是Query,K是key,V是value,笔者认为K是词的特征,而V是词的权重,而Q则是需要进行翻译的那个词的特征,故后面对Q和K作矩阵相乘即寻找需要翻译的词与当前词的相互关系)。

每个词得到q,k,v向量后 ,便相互使用q与k做内积运算,得到一个得分。为了方便模型训练需要进行归一化操作,然后再进行softmax根据得分获得一个累加和为1的概率表示,最后将该概率和v向量相乘,再将所有的v向量求和,得到最后self-attention的最后输出z1向量(一个已经包含了当前词与其他词的相互关系的向量)。

自注意力机制的矩阵解释
上述向量解释是为了方便理解,实际的使用是使用矩阵完成的(其实就是多个词的向量按照行合并在一起,单个向量是一个词,而一个矩阵就是很多词的组合),因为矩阵计算比单个词和向量速度更快,和上述向量解释其实是一个原理。

向量解释中的步骤通过矩阵运算可以表示为下式一步到位:
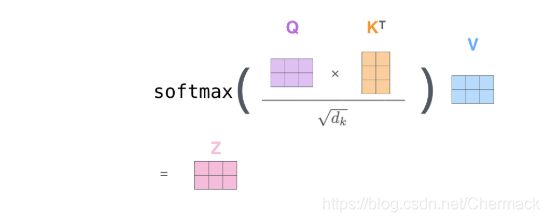
2.多头注意力(multi-head attention)
除了自注意力机制,文章还提出了多头注意力机制,即有多组WQ,WK,WV权重矩阵。这样做的好处是希望注意力机制能够注意到更多不同的地方(transformer给出了8组不同的权重矩阵,下图以两组为例):

最后,为了整合这8组权重矩阵给出的结果(z0,z1…z8),需要将这8组单独得出的结果进行拼接,再乘以一个W0来获取最后的结果表示(z),即W0决定了每一组注意力机制所占的权重。

故多头注意力的工作机制总结如下:获得多个自注意力机制的Q,K,V矩阵,送入自注意力层获得各自的输出z0-z7,通过一个W0矩阵组合多个注意力机制的结果为最终结果z。

3.Encoder和Decoder中的self-attention中的区别
- Encoder中的self-attention关注的是一句话中的所有词与当前词的关联关系。Decoder中的self-attention关注的是当前词之前的词与当前词的关联关系,而与当前词之后的词并没有关系。即Encoder中的self-attention的关注是双向的,而Decoder中的关注是往前单向的,因为在机器翻译任务中Decoder是一个词接着一个词进行单个翻译的。

六、其它技巧
1.位置编码
为了使得语句中的词体现出顺序,在做好词的向量编码工作后,还需要在此基础上加上位置向量来编码词的顺序(在transformer中词向量和位置向量都是512维的向量,直接相加即可)。

2.残差连接
因为Encoders有6个重复的Encoder结构,原始的输入x1向量在后几层Encoder已经起不到很大的影响。为了解决模型过深的为题,引入了残差结构,将原始输入的词向量经过位置编码后,留出一条连接不经过self-attention,直接与self-attention的结果求和,解决模型过深的问题。

关于后面的线性分类器和损失函数(交叉熵)在深度学习基础中都会有详细的介绍,这里不再解释。
参考文献
https://jalammar.github.io/illustrated-transformer/
https://arxiv.org/abs/1706.03762