人脸图像质量评价:FaceQnet
人脸图像质量检测发展
第一个与面部图像质量评估相关的作品可以追溯到2000世纪初。属于研究第一阶段的研究通常集中在从人脸图像中提取手工制作的特征,并使用它们来计算一个或多个质量指标。这些特征旨在估计传统上被认为会影响识别性能的一个或各种因素的存在,例如,模糊性、非额叶姿势或低分辨率。
作者提出了第一批质量测量的汇编之一,并展示了这些措施与该公司的人脸识别器的识别性能之间的关系。他们认为所有的特征都是手工制作的,其中包括:图像的清晰度、眼睛的清晰度、姿势和眼镜的存在
将几个单独的质量措施整合到整体质量测量中。这项工作计算了各种手工制作的面部特征,如:光照、姿势、眼镜的存在和皮肤纹理的分辨率;以及一些图像的特殊特征,如:完整图像的分辨率、压缩伪影的存在,以及来自采集传感器的噪声量。作者将个体质量指标分为两种不同的一般指标:一种基于人类感知,另一种与机器识别精度相关。他们发现,与机器识别相关的质量度量可以提高识别精度,而匹配分数与人机质量度量之间的相关系数要低得多。根据作者的说法,这是因为不同的人对每个个体的质量测量都给予了不同的相关性,其中一些人对人脸识别并不重要
[34]的研究提出了一种基于对称的人脸质量评估方法,该方法依赖于人脸的不对称性。作者认为,这些不对称性可能是由对识别性能有影响的因素引起的,如不均匀的光照和非正面姿态。
在[35]中提出的工作介绍了一种质量评估算法,它检查了模糊、非均匀闪电、非正面姿态和非中性表达式等因素的存在。作者使用特征脸来开发与每个不同质量因素相关的质量函数。然而,它们并没有将质量函数集成到一个估计给定人脸的整体质量的单一指标中
这些“经典”手工制作的方法之一是[36]中提出的方法,作者研究了光照对人脸识别的影响,得出结论,在使用FRVT2006评估它们时,一些表现最好的人脸识别算法(当时)对不同的光照水平高度敏感。
作者提出了一种基于精度的人脸质量指数(FQI),它结合了从五种图像特征中提取的个体质量因素:对比度、亮度、焦距、清晰度和照明度。他们使用案例数据库,为图像添加合成效果(数据增强),能够模拟不同的真实世界的变化。在计算了每个特征的质量数值后,他们定义了面部质量指数,标准化了每个质量度量,并将质量度量的分布建模为高斯PDFs。接近每个PDF平均值的值表示高质量,而远于平均值的分数表示低质量。使用来自FOCS数据库的高质量子集获得了高质量的参考PDF。最后,他们执行了所有个体质量的平均测量来计算FQI。
在[30]中描述了另一种方法。作者提出了生物实验室-国际民航组织框架,这是一种用于自动进行国际民航组织合规性检查的评估工具。本文为每一个输入图像定义了30种不同的单独测试。输出由每个测试的分数组成,从0到100。尽管这个框架代表了开发一个自动工具来了解图像符合公共标准的水平的首次尝试之一,但它是不公开的。此外,第30个项目个人分数没有被纳入最终统一的质量测量中。
在[38]中,作者计算了12个质量特征,它们被分为三类。第一类包括图像处理和人脸识别相关特征,如边缘密度、眼距、人脸饱和度、姿势等。第二类是由与传感器相关的特征组成的,比如在图像的EXIF标头中可能遇到的特征。最后一类包括与他们所使用的比较器相关的特征,即SVM。他们根据整体识别的准确性,提取了关于哪些特征与他们使用的特定数据集(PaSC)更相关的结论。他们利用这些知识将整个数据集分为质量两类:低和高
[39]的作者捕获了一个模拟真实的自动边界控制(ABC)场景的数据库,并将面部质量评估应用于其视频序列。ABC可能是人脸识别中最相关的应用之一,而提高其健壮性对该行业和政府机构有着极大的兴趣。该项工作通过分析不同视频帧的纹理来评估它们的质量,并应用这些质量措施来提高识别精度。
在[40]中提出的工作建立了姿态和光照这两种图像特征以及最终的人脸识别精度之间的关系。他们以一种类似于[37]的方式使用PDFs开发了单独的质量指标。然而,这两种方法的主要区别在于,在[40]中,使用个别的质量测量方法来最终估计预期的精度值,即假匹配率(FMR)和假非匹配率(FNMR)。作者使用了六种不同的人脸识别系统来从数据库中提取精度值:其中两个是商用现货软件(COTS),四个是开源算法,他们将它们应用于三个不同的数据集:MultiPIE、FRGC和级联。虽然它们的质量测量捕捉到了姿态和照明之间的关系,以及人脸识别精度,但这只是现有大量图像质量变化中的两个特征。
[41]的作者提出了一种基于DCNN架构来评估给定人脸图像的光照质量值的方法。他们获得了自己的人脸图像照明质量数据库(FIIQD),并使用它来训练ResNet-50模型(为对象分类而设计)。因此,该模型能够预测与人类感知相关的质量照明分数
在[42]中,作者提出了一种基于学习的面部图像质量方法,可以应用于在视频序列中选择高质量的帧。他们训练了一个随机的森林回归器,以学习一个主观的质量函数,使用LFW数据库的一个子集手动标记,质量分数从1到5。
随着人脸识别深度学习方法的高精度的不断发展,与人脸质量评估相关的研究工作也成功地采用了这种方法。例如,在[43]中,作者预测了与识别精度相关的质量测量(称为机器质量值,MQV)和其他与人类感知质量相关的质量测量(人类质量值,HQV)。他们使用亚马逊机械土耳其人平台对LFW数据库进行了注释,参与者比较了来自LFW的成对图像,并确定了哪对感知质量最高。与[40]不同的是,他们预测了识别精度的值,[43]在训练阶段使用了FMR和FNMR作为精度值,输出是对MQV或HQV的预测。这项工作的另一个区别是,作者使用了一个预先训练好的CNN(VGGFace)从图像中提取特征。然后,他们利用这些特征来训练自己的分类器,这意味着他们成功地将知识从人脸识别转移到质量预测。作者得出了一些有趣的结论,比如两者都是如此。他们还得出结论(基于他们的结果),自动HQV是一个比自动MQV更准确的预测精度。[43]的工作可能是文献中报道的最面对质量估计的先进方法之一。然而,它仍然存在一些缺点:1)需要大量的人力精力来标记数据库与人类感知质量;2)每个受试者需要手动选择高质量的图像来获得机器精度预测,从而涉及人类的努力和引入人类偏见[45]
在[13]中提出的工作比较了主观和客观的人脸质量度量及其对人脸识别相似度分数的影响。他们询问了26名参与者标签人脸图像的分数与容易识别图像上的人脸。然后,作者将该主观分数与使用ISO/IECTR29794-5的指南计算出的其他客观分数进行了比较。他们发现,主观分数与识别分数的相关性优于客观分数
在[11]中,我们提出了FaceQnetv0,这是一种深度学习方法,其目标是将图像的质量与其人脸识别的预期精度联系起来。它是被设计为在[43]中提出的工作的一个扩展的。我们使用BioLaBICAO框架[30]为VGGFace2数据库的图像标记与国际民航组织合规级别相关的质量信息。FaceQnetv0的训练是使用那个自动标记的基础真相来完成的。我们表明,来自FaceQnetv0的预测与一个最先进的商业系统的人脸识别精度高度相关。然而,我们的建议有一些局限性:我们 只在生成真实值时使用了一个人脸识别器(可能引入了系统依赖性);基本真相数据中异常值的存在显著影响了训练过程 ;由于我们的测试协议只包括两个不同的数据库,因此我们无法提取出可以完全有信心地应用于其他数据的结论
最近的一些面部质量评估工作已经在其主要参考文献中提到了FaceQnetv0。其中之一是[44],作者提出了一种基于无监督学习的人脸质量评估方法。他们计算了来自几个预先训练的CNNs的人脸嵌入的变化。他们通过测量单个人脸图像不同嵌入的鲁棒性开发了质量指示器。作者将他们的解决方案与六种最先进的面部质量评估方法(其中包括FaceQnetv0)进行了比较。
人脸质量评估工作遵循了与人脸识别[7]的平行路径。在这两种情况下,最初的作品都是基于手工制作的特征,这是由研究人员根据他们对哪些因素可能与要解决的问题更相关的直觉来设计的。与人脸识别相似,目前最有前途的方法是那些基于深度学习的方法。只要有足够的训练数据,这种算法的性能就会优于手工制作的方法可用的。利用这些数据,深度学习模型能够推断出输入和预期输出之间的关系,即使它们是非线性的。然而,缺乏标签数据,例如,在面部质量评估中,使得真的很难准确地训练深度模型。综上所述,由于这次对面部质量评估工作的回顾,我们已经确定了迫切需要一种方法,以促进将具有质量值的训练数据进行标记的任务。
目前的工作是在克服[43]和FaceQnetv0[11]的限制方面向前迈出了一步。因此,我们提出的解决方案,即FaceQnetv1是:
- 1)基于最先进的深度学习;2)在没有人工干预的情况下,可大量扩展;3)使用多个人脸数据集和最先进的人脸识别系统开发和测试;4)在NIST的独立评估中得到验证。

目前的工作分为两个不同的阶段:一个开发阶段,我们构建和训练FaceQnetv1,另一个评估阶段,我们将FaceQnetv1和文献中的其他质量措施应用到不同的数据库中,比较它们在面部质量评估中的准确性。图展示了FaceQnet的开发和评估框架的总体方案,以及在每个阶段使用的数据库、面部识别器和质量措施形式的不同资源。
图的左半部分描述了我们第一次在其中通过标记一个训练数据库(VGGFace2的300名用户)来生成一个高质量的基础真相的开发阶段
我们可以把人脸识别的质量作为衡量主体图像的类内变异性的一种标准。国际民航组织的技术报告[27]在捕捉新图像时制定了非常严格的指导方针。控制变异率因素,如分辨率、光照、姿势、焦点等,[46],使来自同一主题的图像看起来像尽可能相似,即内部变异性较低。这样,比较分数应该只依赖于不同受试者之间的差异,即阶级间的变异性。基于这个基本原理,在目前的工作中,我们提出了下一个假设,以计算质量的基础真相:
假设1:
在这项工作中,我们假设一个完全兼容的国际民航组织图像代表了完美的质量,因为它的低的类内变异性。因此,我们**假设这种完美质量的图片A(即符合ICAO)与一个质量未知的图片B之间的匹配比较分数可以是图片B的质量水平(其阶级内的变化水平)的有效和准确的反映。**如果比较分数较低,则这一定是由于图像B的低质量所致,因为A是已知的完美质量。另一方面,如果分数很高,则可以假定第二张图像质量良好,包含低水平的变异性因子,如前面提到的那些。因此,该比较分数可以用作图片B的机器生成的基本质量
为了了解训练数据库中的哪些图像最接近国际民航组织的合规性,我们使用了来自[30]的生物实验室框架。该框架为其30个国际民航组织合规测试提供0到100分。并不是所有这些测试对人脸识别都具有相同的相关性,所以我们选择了它们的一个子集,然后我们计算了一个最终的平均全球国际民航组织合规值。更具体地说,我们选择的测试是:模糊水平、过暗/光照、像素化、异质背景、滚动/音高/偏航水平、帽子/帽子的存在、眼镜的使用和阴影的存在
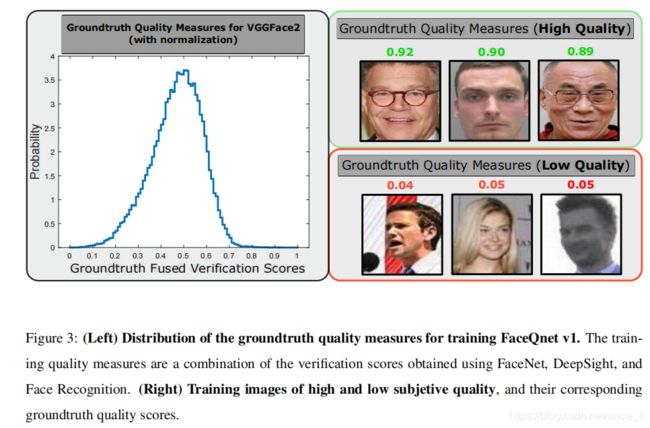
作为我们的质量评估措施的训练集,我们从VGGFace2数据库[8]中选择了300个主题的子集,从现在起将被称为DBGt-1。该数据库包含9131个不同个体的331万张图像,每个研究对象平均有362.6张图像。数据库中的所有图像都是从谷歌图像中获得的,它们对应于知名名人,如男女演员、政治家等。图像在无约束条件下获得,在姿势、年龄、光照等方面有很大的变化。这些变化意味着不同的质量水平。在本工作的评估部分,我们还使用了由30个主题组成的VGGFace2的另一个不相交子集来检查我们的质量测量的准确性。VGGFace2不同质量的图像如图所示。
对于训练集中的每个主题,我们选择了具有最高国际民航组织合规值的图像作为参考图像,并使用其余图像作为探测图像。为了获得根据假设1中解释的基本原理,将作为我们的基本真相质量分数,我们将训练数据库的每个探测图像输入到三个人脸识别器中,以提取三个不同的128维特征向量。我们决定使用各种开源和专有的最先进的识别器,以开发一个尽可能少依赖系统的质量基础真实性
常见的实现网络
-
FaceNet
-
DeepSight
-
Dlib
每个主题使用一个基准图片,将其设为参考。
利用人脸识别的方式获得人脸的嵌入向量128维度,再计算与基准图片的欧式距离
基于上述方法得到三种不同的距离,之后对这三种距离进行归一化操作,归一化到0~1

然后将这三个分数的平均数作为训练faceqnet-v1的训练标签
使用三种不同的面部识别器获得的标签分数,以试图避免依赖于系统的质量基本分数。如果我们只使用一个识别器,那么在估计该训练匹配器的识别性能时,所得到的质量度量将是非常准确的,但它可能对预测以前从未见过的识别器的准确性不是那么有效果。
核心思想是借鉴于人脸识别的网络,如果两个图片人脸识别时候效果好,说明两个图片的质量高,且两个人像。
基于此,embeding向量代表该人脸的图像及质量,如果embeding向量与基准图片的embeding向量的分数非常相近的话,则表示该图像质量分数高。
本文使用三种人脸提取算法获得三个分数,并以平均分数表示其最终分数,基于该数据来训练FaceQnet网络
假设2:
考虑到识别精度的面部特征向量和质量之间的定义(根据来源的特征、捕获装置的保真度和样本的效用)所存在的密切关系,包含有关身份信息的面部特征向量也很可能包含有关人脸质量的信息。因此,使用知识迁移,我们应该能够从最初为识别目的而设计的特征向量中提取与质量相关的信息。
VGGFace2数据库还发布了一个基于ResNet-50架构的CNN网络,通过数据库预先训练,表明在对具有挑战性的人脸识别基准进行测试时,他们能够获得最先进的结果。
移除最后一个分类层,并添加两个全连接层替换它来进行质量估计;删除了基础模型的最后一个分类层,并用两个全连接(FC)层替换它来进行质量估计
为了改进FaceQnetv0[11]的初步结果,在FaceQnetv1中,我们还在第一个FC层之前添加了一个dropout层,以避免在面对来自不同数据集和场景的图像时更好地推广。
FaceQnetv1的最终架构如图所示。除了在基础真实数据的生成中所做的变化之外,我们还使用了三种不同的比较器来避免系统的依赖性,与FaceQnetv0相比,架构中的这种变化使模型更与系统和数据无关
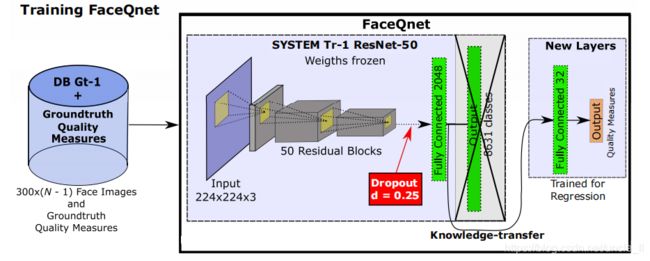
对网络的输入是先前使用MTCNN[59]裁剪和对齐的尺寸为224×224×3的人脸图像。我们冻结了所有旧层的权重,并且我们只使用前一步中生成的质量基础真相来训练新层
一旦训练,FaceQnet可以用作“黑盒”,接收人脸图像并输出与人脸识别精度相关的0到1之间的质量度量。
评估结果:
三个图像分类
- 应用拍摄的
- 网络摄像头
- 自然拍摄

总结
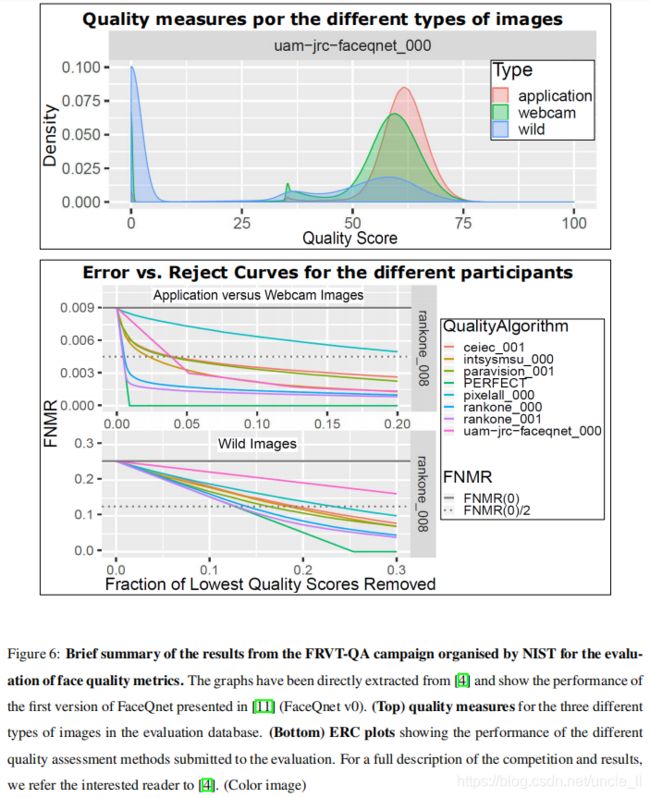
给定了质量分数的分布,如图所示。表6上半部分表明,我们可以说FaceQnetv0能够以合理的准确性区分竞争中考虑的三个图像类别中的质量差异。然而,它有在质量范围的低端饱和的倾向,也就是说,它识别质量差图像的能力明显有限,为它们分配给非常低的质量值(见质量值0周围的野生分布的异常高叶)。
表6小半部分表明:FaceQnetv0在对平均、良好和非常高质量的图像(即网络摄像头和应用程序类别)的质量估计方面表现得相当好。这一点已经在顶部图中所示的分布中已经被注意到,并通过“应用与网络摄像头”场景的ERC曲线进一步证实,在大多数曲线中,FaceQnetv0的性能只比两个“兰肯”质量指标更差。请注意,这些ERC曲线是使用“兰酮”比较器提取的,因此,可以预期“兰酮”比较器和质量度量与所有参与者的相关性最高
野生与野生”场景的ERC曲线表明,FaceQnetv0在低质量图像存在的情况下苦苦挣扎,其性能比所有参与评估的其他算法都要差。同样,这也证实了基于顶部图中所示的分布而提取的观察结果。基于这些结果,我们可以说,度量能够检测到不良图像(参见“野生”分布中接近0的高叶),但它赋予它们总是非常低的质量。因此,它需要提高其更好地区分对应于低值的图片(质量范围为0-30)的能力。
基于此: 研究了faceqnetv1版本,做出的改进有:
-
架构的改变增加了dropout层,以避免算法在质量范围低端的快速饱和;
-
使用额外的数据集和人脸识别系统改进训练过程,以产生真实质量分数
自我评测
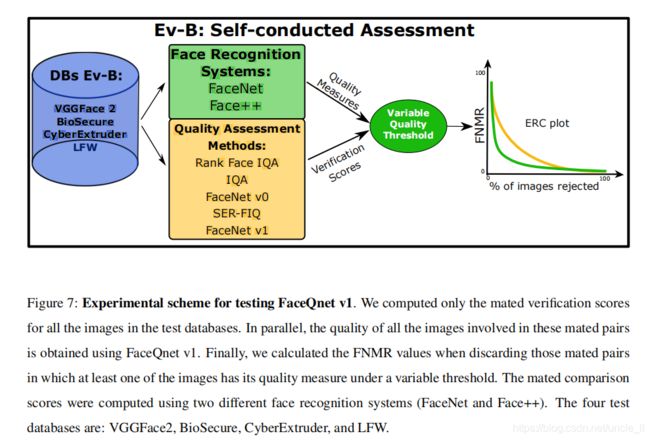
在四个数据集上进行测试:VGGFace2, BioSecure, CyberExtruder, LFW

-
vggface2:
-
biosecure:
- 由1000名受试者组成,他们的生物特征样本是在三种不同的场景中获得的。第一个场景的图像是使用网络摄像头远程获得的,第二种是使用具有均匀背景的高质量摄像机的肖像型场景,第三种场景不受控制,用室内和室外的移动摄像机拍摄。在目前的工作中,我们使用这个数据库进行评估。我们使用了1459张来自第二种第三种场景下的140个受试者获得FaceQnetv1的质量度量。
-
cyberextruder:
- 该数据集包含了从互联网上提取的1,000人的10,205张受试者的图像。这些数据是不受限制的,即它包含很大的姿势、灯光、表达、种族和年龄变化。它还包含带有闭塞性的图像。
-
lfw:
- 该数据库由5749个不同对象的13233张图像组成,其中1680张有两个或更多不同的图像。
- 近年来,该数据库被广泛用于研究无约束条件下的人脸识别。为每张图像发布一个基于精度的质量度量可以有助于提高使用该数据集作为基准的最先进的人脸识别系统的准确性。
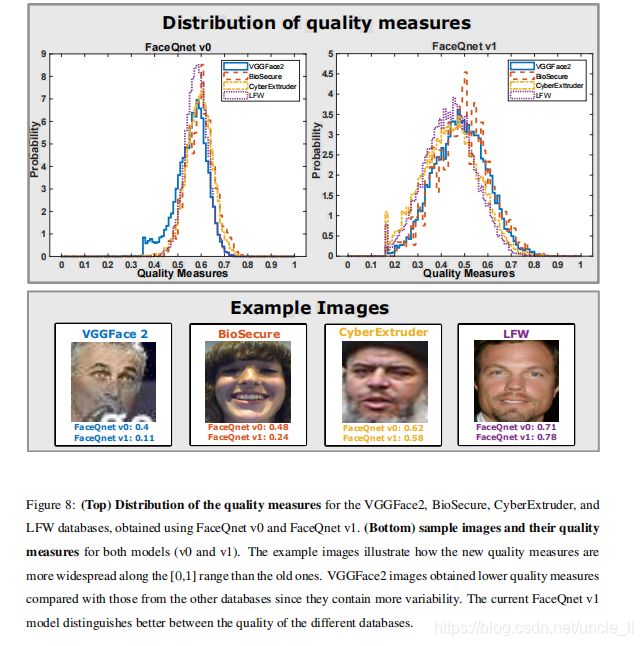
(上半部)使用VaceQnetv0和FaceQnetv1获得的四个数据库的质量指标的分布。(下半部)两种模型(v0和v1)的样本图像和质量测量。示例图像说明了新的质量测量如何在[0,1]范围内比旧的更广泛。VGGFace2与其他数据库相比,VGGFace2图像获得的质量较低,因为它们包含更多的变异性。当前的FaceQnetv1模型更好地区分了不同数据库的质量
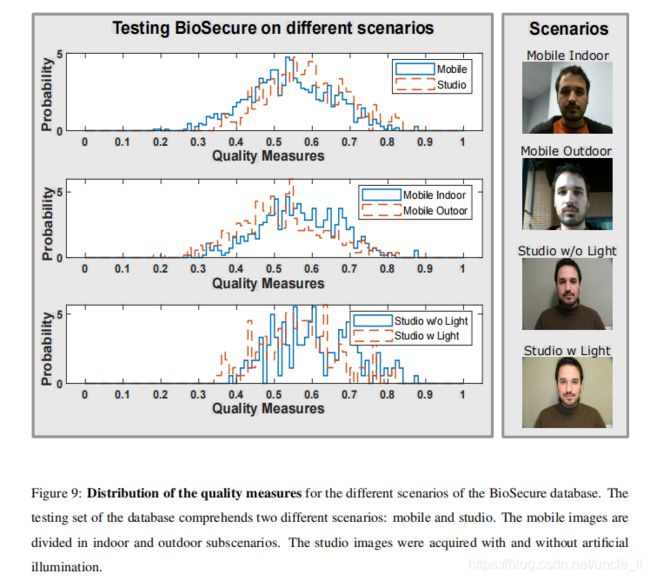
显示了上述场景和子场景的质量度量的分布。正如预期的那样,在“工作室”条件下获得的质量度量比在“移动”条件下获得的平均值更高,因为其图像是用更高质量、背景和光照均匀、姿态更好的相机获得的。此外,不同的收购条件也为
- 室内比室外好
- 工作室拍摄比手机拍摄质量好
结论
-
1 假设1成立,本工作采用的生成基础真相质量分数的方法是成立的,假设完美质量图片A(即符合国际民航组织的图片)与低质量图片B(同一主题)的比较分数,是有效、准确反映图片的质量水平的方法 B. 因此,由此产生的比较分数可以作为机器生成的图像基础真相质量分数 B. 这种策略允许使基础真相生成过程自动化,避免了基于人类感知生成质量分数的高度耗费时间和资源的任务,这也可能偏向于机器对质量的理解
-
2 假设2成立。机器学习的人脸识别特征不仅包含关于人的身份的信息,而且还包含关于图片质量的信息。这些与质量相关的信息可以通过a从原始的特征向量中提取出来
实验关键点:
-
本方法的关键点之一是基于完美的符合国际民航组织的图片生成基本真相质量分数(见假设1)。由于缺乏专门为人脸质量评估设计的公共数据库,国际民航组织的肖像是从通用人脸数据库中选择的,依赖于自动的ICAO合规测试仪,效率没有得到充分证明。手动监督自动选择的图片作为第二次检查,以在最大程度内确保整体高质量水平。尽管我们尽了最大努力,但很可能有许多这些训练图像,即使是高质量的,也不完全符合国际民航组织的要求。因此,我们坚信,如果训练过程是在民航组织的限制下获得的图像,而不是从一般“野外”数据库中选择,它将有很大的好处。
-
训练数据:如果训练数据库的大小显著增加,只有覆盖大量和均匀的整个质量谱的图像,才能期望得到更准确的结果。这意味着训练数据库应包括每个主题:1)在符合国际民航组织的环境中获得的图片(见上面的要点);2)涵盖大量质量值的图片(例如接近国际民航组织、室内正面网络摄像头、野外户外正面网络摄像头)。据我们所知,研究界还没有这样的数据库。我们认为,这将是一个旨在进一步推进面部质量评估领域的宝贵资产。
-
人脸检测:对于输入图像,第一任务是只检测人脸,并且仅对图像中的该区域进行紧密裁剪。人脸检测器可能很难正确定位面部,但这种困难将独立于我们所提倡的仅限人脸使用的质量指标。在一些应用中,使用集成人脸分割和生物特征质量的质量度量可能更有效、更可操作。虽然在我们的视野中,生物特征分割(在这种情况下的人脸检测)本质上不是人脸质量算法的一部分,但它可以对其结果产生决定性的影响,这取决于所使用的人脸检测器的准确性。对于人脸质量指标的训练和评估,包括FaceQnet,强烈建议对人脸区域使用基于真实值分割的人脸图像,以便不需要人脸检测器,因此,从系统中删除其可能引入的可变性。人脸检测算法对质量评估的影响还是比较大的。
参考
- Biometric Quality: Review and Application to Face Recognition with FaceQnet