【RL 第2章】Q-Learning
Q-Learning是一种决策过程,也是RL种最最基础的一门算法,这块b站的莫凡大神的视频我个人认为讲的不是很清楚,所以我找了唐宇迪的视频进行学习,本节课我会先给大家讲Q-Learning的过程,再给大家放上代码,供大家细细品尝~
注意!本节需要用到第一章的知识内容!!如果有小伙伴忘记了请自行跳转复习!!
ok兄弟们,那么接下来,咱们就开始正式的学习Q-Learning算法!
按照Willing的风格,咱们还是举一个栗子:
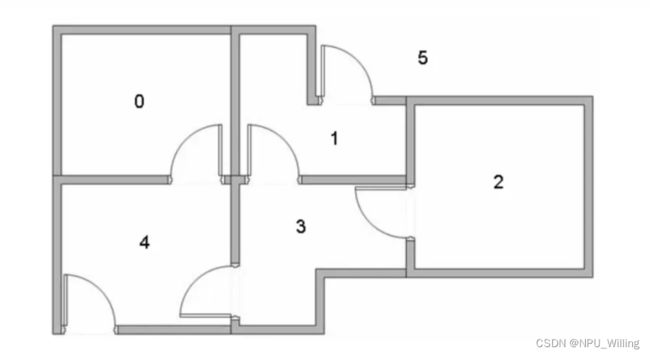
假设有这样一间房屋,里面共有6个房间,我们随机将机器人投放到其中一个房间中,并且我们的目标是到达5号房间
此时模型非常显而易见了,在这个过程中,我们的Agent是投放到房屋里的机器人,State是身处的房间号(例如在3号房间就是State 3),Action是穿越不同房间的门(例如(2,3),(4,0)),Policy则是Agent从初始房间最终到达5号房间所经历的一系列动作集。(有smart的同学发现了,那Reward呢?别着急,在下面我们会定义奖励)
此时,我们可以对其进行建模,如下图所示:
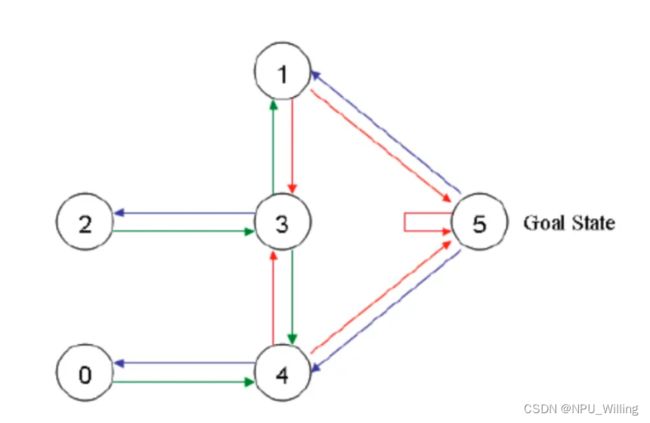
图中单箭头表示房间的通向性(例如2指向3,就代表从2号房间可以进入3号房间) ,特别的是,5号房间有一个自循环的箭头,这是因为5号房间就是我们的目标房间,当Agent到达5号房间时,它会在其中自循环,游戏此刻就已经结束(总不能再让它再跑出去吧<(* ̄▽ ̄*)/)
当然,为了保证Agent能够走出去,我们要给不同的箭头设置不同的Reward,因为5号是目标房间,所以所有指向5号房间的箭头的Reward将特别大,同理,其他箭头(例如2指向3,0指向4)的Reward就特别小,如下图所示:

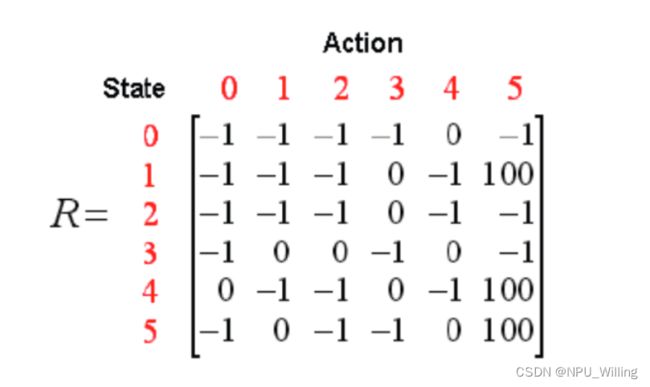
根据上述Reward的分布,我们可以得到一个Reward矩阵:
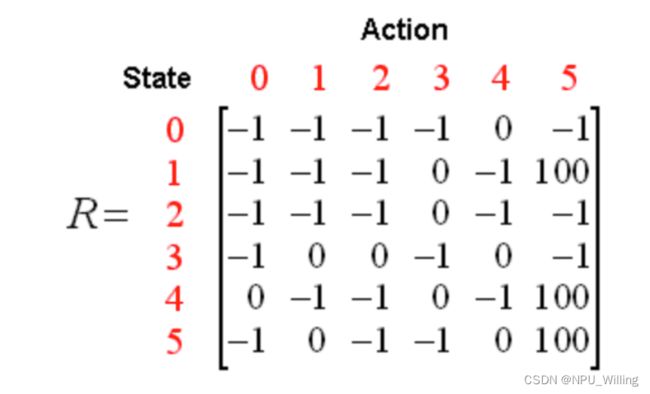
其中,矩阵的行代表Agent当前所处的状态,列代表处于此状态的Action,-1代表两个房间是不通的,0代表可以通过,100则代表到达终点。
同时,我们也可以定义一个Q表(划重点!),他是一个与Reward同阶的0矩阵(所有元素都是0),Q表代表Agent所学习到的经验。
根据Q-Learning的状态转移方程:
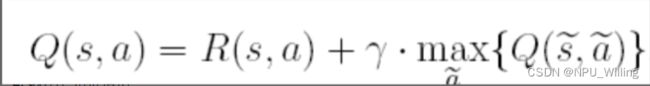
其中,s,a代表当前的状态和行为,s~,a~代表s的下一个状态和行为,γ为贪婪因子,一般为(0,1)之间的常数。
接下来,我们给出 Q-Learning的学习步骤:

实际上,这是一个对Q表不断进行迭代的过程 ,如果同学们一时没看明白也没关系,咱们可以举一个实际推导的例子来算一算(′▽`〃)
假定贪婪因子γ=0.8
Reward矩阵:
初始化Q表:
 接下来,我们随机选择一个状态,例如State 1,我们发现并未达到目标状态,于是我们在Reward矩阵中查看1所能到达的房间(即可以进行的Action) ,发现是3或5,随机的,我们选择5作为Action,于是根据Q-Learning的状态转移方程:
接下来,我们随机选择一个状态,例如State 1,我们发现并未达到目标状态,于是我们在Reward矩阵中查看1所能到达的房间(即可以进行的Action) ,发现是3或5,随机的,我们选择5作为Action,于是根据Q-Learning的状态转移方程:
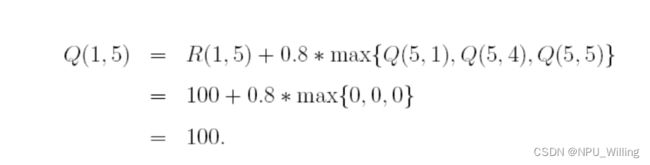 此时Q表更新为:
此时Q表更新为:
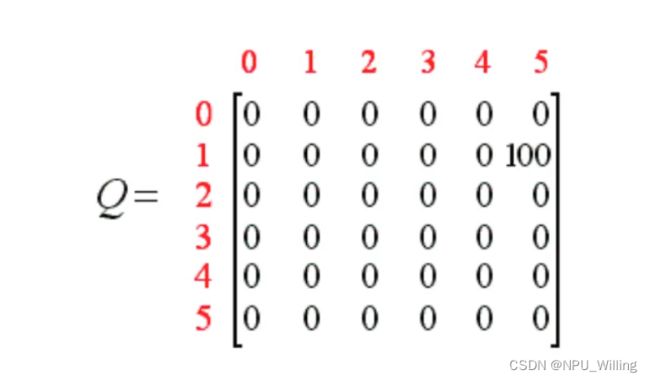
因为到达了目标房间5,于是本轮游戏结束(撒花ლ(╹◡╹ლ))
接下来,我们再随机将Agent投放到一个房间,比如State 3,那么3的选择就有(3,1)(3,2)(3,4),我们随机选择(3,1),于是根据 Q-Learning的状态转移方程:
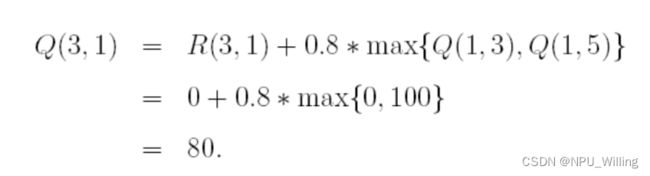
此时Q表也更新为:
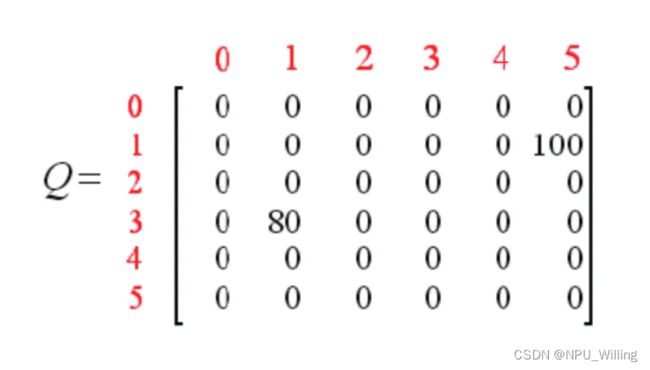
接下来,重复上述迭代次数,不断地将Agent随机投入到一个有一个的房间.......
写到这里,可能有smart的同学已经发现了,Q-Learning的本质实际上是根基Reward矩阵,对Q表不断地进行更新和完善 ,我们进行上述训练的目的,就是为了在经过一定次数的迭代训练后,得到一张“成熟”的Q表(如下图),作为我们的Agent在实际应用中的“行动指南”。
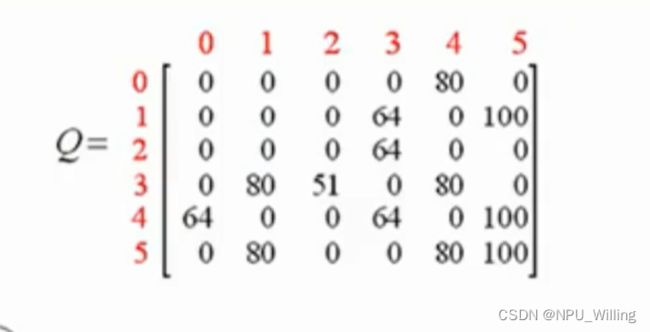
例如,在实际应用中,当我们将Agent随机放入到某一个房间后(假如是1),Agent会掏出Q表,定睛一看:诶~我能去的房间只有3和5,(1,5)的Q值明显大于(1,3),诶嘿嘿嘿~那我就走(1,5),于是乎,Agent就成功的通关啦↖(^ω^)↗,当然,也有眼尖的同学发现了,这个Q表里(4,0)的值和(4,3)的一样啊,这样子怎么办呢?这时候,若有多个最大且相同的Q值,我们是采取随机选择一个Action的。
当然,可能也有同学会担心:这个迭代次数一多,Q表里的值会不会一直增加呀(°o°;),答案是不会的!当训练到一定次数时,Q表的值会趋于稳定,此时我们称之为Q表的收敛

写到这里,相信大家已经对Q-Learning的基本原理有了一定的认识,当然,在实际生活中,更新Q表的过程也是通过机器去进行的,相信在座有很多大佬已经饥渴难耐了o( ̄▽ ̄)d,别着急,Willing下面就讲为大家展示Q-Learning的详细代码步骤,Willing所使用的是Python语言,需要用到numpy库函数,其他语言的代码也欢迎各位大佬私信补充ヾ(≧∇≦*)ゝ
A.建立Reward矩阵,并初始化Q表
import numpy as np
import random
# 建立 Q 表
q = np.zeros((6, 6)) #zeros函数:返回一个给定形状大小的用0填充的数组
q = np.matrix(q) #矩阵化
# 建立 R 表
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
r = np.matrix(r) #因为array返回的是数组,所以我们需要用matrix函数将其矩阵化
# 贪婪指数
gamma = 0.8
B.训练1000次模型,最终得到一张“成熟”的Q表
# 训练
for i in range(1000):
# 对每一个训练,随机选择一种状态
state = random.randint(0, 5)
while state != 5: #没有达到目标房间
# 选择r表中非负的值的动作
r_pos_action = []
for action in range(6): #选出所有能到达的下一个房间
if r[state, action] >= 0:
r_pos_action.append(action)
next_state = r_pos_action[random.randint(0, len(r_pos_action) - 1)] #随机选择下一个状态
q[state, next_state] = r[state, next_state] + gamma * q[next_state].max()#根据转移方程更新Q表
state = next_state
print(q)#打印Q表
C.将训练好的Q表作为Agent的“行动指南”,验证Q表的质量
# 验证
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5) #随机将Agent投放到一个房间里
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break #如果超过20步,则失败
# 选择最大的q_max
q_max = q[state].max()
q_max_action = []
for action in range(6): #选出最大的,因为最大的可能不只有一个
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]#从Q值最大的action中随机选取一个,进入下一个State
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
安啦~以上就是代码的组成,接下来我们运行试试看(☆▽☆):
训练好的Q表:
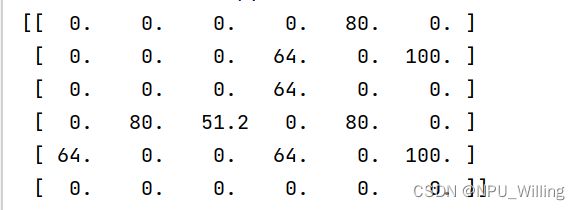
验证结果:

总体来说,模型还是很不戳滴Y(^o^)Y,那么本期的教程就到这里了,如果uu没听懂可以再多手算推导几次,相信大家最终都可以掌握(づ。◕‿‿◕。)づ,拜拜,米娜桑!
最后,小的附上完整代码:
import numpy as np
import random
# 建立 Q 表
q = np.zeros((6, 6)) #zeros函数:返回一个给定形状大小的用0填充的数组
q = np.matrix(q) #矩阵化
# 建立 R 表
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
r = np.matrix(r) #因为array返回的是数组,所以我们需要用matrix函数将其矩阵化
# 贪婪指数
gamma = 0.8
# 训练
for i in range(1000):
# 对每一个训练,随机选择一种状态
state = random.randint(0, 5)
while state != 5: #没有达到目标房间
# 选择r表中非负的值的动作
r_pos_action = []
for action in range(6): #选出所有能到达的下一个房间
if r[state, action] >= 0:
r_pos_action.append(action)
next_state = r_pos_action[random.randint(0, len(r_pos_action) - 1)] #随机选择下一个状态
q[state, next_state] = r[state, next_state] + gamma * q[next_state].max()#根据转移方程更新Q表
state = next_state
print(q)#打印Q表
# 验证
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5) #随机将Agent投放到一个房间里
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break #如果超过20步,则失败
# 选择最大的q_max
q_max = q[state].max()
q_max_action = []
for action in range(6): #选出最大的,因为最大的可能不只有一个
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]#从Q值最大的action中随机选取一个,进入下一个State
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1