关于yolo的学习笔记----原理和核心技术的总结
关于yolo的学习笔记-----原理和核心技术的总结
1.yolo v1与fasterRCNN的区别
link.
参考文章https://blog.csdn.net/guleileo/article/details/80581858
faster-RCNN 中也直接用整张图作为输入,但是 faster-RCNN 整体还是采用了 proposal+classifier 两个分支计算的思想,YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。
2.yolo v1的回归与计算方法
link.
https://www.jianshu.com/p/13ec2aa50c12
目前,基于深度学习算法的一系列目标检测算法大致可以分为两大流派:
1.两步走(two-stage)算法:先产生候选区域然后再进行CNN分类(RCNN系列),
2.一步走(one-stage)算法:直接对输入图像应用算法并输出类别和相应的定位(YOLO系列)
输入一幅图,分成S*S个网格,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。处于object中心点的网格负责预测这个物体
每个格子输出B个bounding box信息,以及C个物体属于某种类别的概率信息。
每个格子输出=B个(x,y,w,h,confidence)+C个类别概率
confindence = 
confidence反映当前bounding box是否包含物体以及物体位置的准确性。
若bounding box包含物体,则P(object) = 1;否则P(object) = 0. IOU(intersection over union)为预测bounding box与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
x,y,w,h表示box坐标,其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
因此,YOLO网络最终的全连接层的输出维度是 S* S * (B * 5 + C)。YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7(划分为7X7个网格),B=2(为什么是2呢?);采用VOC 20类标注物体作为训练数据,C=20(识别的物体类别数)。因此输出向量为7 * 7 * (20 + 2*5)=1470维。
注意:class 信息是针对每个网格的(每个网格都有一个class分类概率),confidence 信息是针对每个 bounding box 的(只有候选框才会有IOU呀)。
3.yolo v1网络结构

缺点1:由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。(输入尺寸必须固定,这是一个缺点)
在 test 的时候,每个网格预测的 class 信息和 bounding box 预测的 confidence信息相乘,就得到每个 bounding box 的 class-specific confidence score:(用类别乘以是否含有目标(0 or 1)乘以IOU),因此这个函数包含了class类别信息也包含了box位置信息。
也等于类别概率乘以IOU(因为如果该格子不含物体,那么就没有class啦,因此只需要考虑含有物体的,含有物体的为1)

左边第一项,表示该单元格存在物体且属于第i类的概率。右边第一项,表示这个box属于第i类物体的概率。
因此最后对应了,预测的哪一类和box信息(针对每一个bounding box来说,不是每一个格子)
虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的 bounding box 作为物体检测输出,即每个格子最多只预测出一个物体。(增加B是否可以提高准确度?)
最后一步,得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 处理,就得到最终的检测结果。(那么得到的也应该是S * S * (5 * B+C))的一个向量。
缺点2:当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是 YOLO 方法的一个缺陷(不适用物体多且小还密的图片)
link.
https://www.jianshu.com/p/13ec2aa50c12
具体计算为下图;
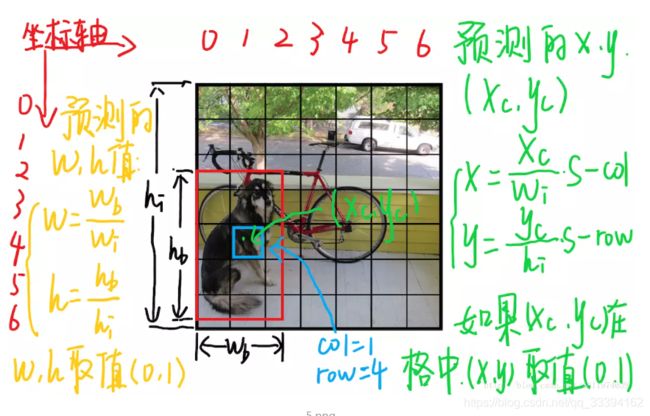
由于归一化,那么所有输出都是属于(0,1).
(x,y)是bbox的中心相对于单元格的偏移
(w,h)是bbox相对于整个图片的比例
4.yolo v1的损失函数
损失函数为坐标误差和IOU误差和class误差的平方和

但是需要进行权重的修正,因为
1.坐标误差,IOU误差和class误差比重需要调整,不能1:1:1一样重要更看重坐标误差,系数取
2.对于小格子是否是目标的中心点,注意不是包含物体一部分,没有的box confidence(就是在计算bounding box是否包含物体以及物体位置的准确性那里,类别概率乘以真是标签的IOU)取0.5,有的取1
3.对于box大小,小的box肯定会因为一点小偏移产生巨大误差,而box很大的话,因为一点小偏移产生的误差就很小,因此用根号w和根号h代替以前的w和h,因为根号函数就是在x小的时候变化很快,x大的时候变化越来越小。可以对应,box小的时候一点点误差影响很大,也就是y轴变化大,box大的时候反之,其实就是斜率和求导。(有文章说这个方法不能完全解决这个问题,没看懂为什么link.参考https://zhuanlan.zhihu.com/p/25236464)
loss函数计算公式:参考link.
https://blog.csdn.net/guleileo/article/details/80581858

只有当某个网格中有 object 的时候才对 classification error 进行惩罚。
只有当某个 box predictor 对某个 ground truth box 负责的时候,才会对 box 的 coordinate error 进行惩罚,而对哪个 ground truth box 负责就看其预测值和 ground truth box 的 IoU 是不是在那个 cell 的所有 box 中最大。
5.yolo v1 的缺点
由于进行了多次的下采样,缩小了图片大小,因此特征提取并不精细,会影响检测结果。
大box 和小box影响没有完全解决,虽然用了平方根算法。
由于一个格子只能预测0和1个物体,因此有小而密的物体预测时不准确
出现新的长宽比奇特物体时,检测效果不好
损失函数上,因更加加强位置定位,特别是大小物体同时出现的时候。