Spark基础篇-Spark-Core核心模型(一)
Spark系列文章目录
第一章 初识Spark
第二章 Spark-Core核心模型(一)
第二章 Spark-Core核心模型(二)
第三章 Spark-Core编程进阶(一)
第三章 Spark-Core编程进阶(二)
第四章 Spark-SQL基础(一)
第四章 Spark-SQL基础(二)
第五章 Spark-SQL进阶(一)
第五章 Spark-SQL进阶(二)
第五章 Spark-SQL进阶(三)
文章目录
- Spark系列文章目录
- 第二章 Spark-Core核心模型(一)
-
- 1.RDD
- 2.数据分区
-
- 2.1构建RDD
-
- 2.1.1**读取外部数据集**
- 2.1.2 **对一个Seq并行化**
- 2.1.3**案例**
- 2.2分区个数
第二章 Spark-Core核心模型(一)
1.RDD
弹性分布式数据集(Resilient Distributed Dataset)是Spark中最基本的数据抽象。
-
不可变(只读)
-
可分区
-
可并行计算
-
自动容错
-
位置感知性调度
RDD是Spark的核心抽象模型,本质上是一个抽象类。RDD源代码部分重点代码实现如下:
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
......
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`
*/
protected def getPartitions: Array[Partition]
/**
* Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*/
protected def getDependencies: Seq[Dependency[_]] = deps
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
/** Optionally overridden by subclasses to specify how they are partitioned. */
@transient val partitioner: Option[Partitioner] = None
// =======================================================================
// Methods and fields available on all RDDs
// =======================================================================
/** The SparkContext that created this RDD. */
def sparkContext: SparkContext = sc
/** A unique ID for this RDD (within its SparkContext). */
val id: Int = sc.newRddId()
......
}
RDD有五个属性,用来描述数据集的状态。
- partitions 数据分区(抽象)
- compute 对分区计算的函数(抽象)
- dependences 依赖列表(抽象)
- partitioner 分区方式(具体)
- preferredLocations 优选位置(具体)
注意,RDD的具体实现类中必须重写前三个属性。
思考1,RDD的具体实现类中后两个属性需要重写吗?
RDD的具体实现类如下:




注意,虽然RDD的实现类很多,但只需要掌握抽象RDD中的五个重要属性即可。
2.数据分区
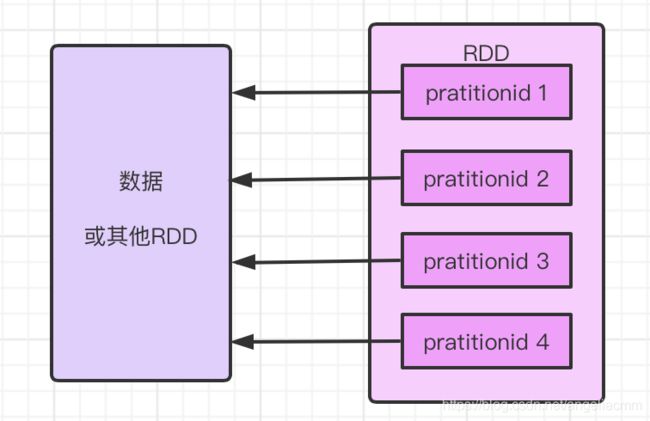
站在数据的角度思考RDD,RDD是由数据分区(partition)组成,这些分区运行在集群中的不同节点上。
- 一个RDD可以包含多个分区
- 一个分区就是一个dataset片段
- 一个分区会被封装成一个Task
RDD内部数据组成如图:
数据分区源码实现如下:
/**
* An identifier for a partition in an RDD.
*/
trait Partition extends Serializable {
/**
* Get the partition's index within its parent RDD
*/
def index: Int
// A better default implementation of HashCode
override def hashCode(): Int = index
override def equals(other: Any): Boolean = super.equals(other)
}
思考2,数据分区内部存储数据吗?RDD存储真正的数据吗?
数据分区内部并不会存储具体的数据。
- Partition类内包含一个index成员,表示该分区在 RDD内的编号;
- 通过RDD编号+分区编号可以唯一确定该分区对应的块编号;
- 利用底层数据存储层提供的接口;
- 就可以从存储介质(如:HDFS、Memory)中提取出分区对应的数据。
2.1构建RDD
2.1.1读取外部数据集
- 文本文件
sc.textFile(path[,minPartitions])
sc.wholeTextFiles(path[,minPartitions])
- 字节文件
binaryFiles(path[,minPartitions])
- 对象文件
sc.objectFile[T](path)
- SequenceFile
sc.sequenceFile(path,keyClass,valueClass[,minPartitions])
sc.sequenceFile[K,V](path[,minPartitions])
- Hadoop输入输出格式
sc.newAPIHadoopFile[Text,Text,KeyValueTextInputFormat](path)
sc.newAPIHadoopFile[F](path)
说明:
-
path可以是文件也可以是目录,也可以是带有匹配符号的路径。
-
minPartitions是指用户未给定时HadoopRDD的默认最小分区数。注意,我们使用math.min所以"defaultMinPartitions"不能大于2。
-
keyClass、valueClass是指数据文件中key、value的数据类型。
在源码中各个方法定义如下:
//1.文本文件
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
def wholeTextFiles(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[(String, String)] = withScope {
/** Default level of parallelism to use when not given by user (e.g. parallelize and makeRDD). */
//....
}
//2.字节文件
def binaryFiles(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[(String, PortableDataStream)] = withScope {
//...
}
//3.对象文件
def objectFile[T: ClassTag](
path: String,
minPartitions: Int = defaultMinPartitions): RDD[T] = withScope {
assertNotStopped()
sequenceFile(path, classOf[NullWritable], classOf[BytesWritable], minPartitions)
.flatMap(x => Utils.deserialize[Array[T]](x._2.getBytes, Utils.getContextOrSparkClassLoader))
}
//4.sequence文件
def sequenceFile[K, V](path: String,
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int
): RDD[(K, V)] = withScope {
assertNotStopped()
val inputFormatClass = classOf[SequenceFileInputFormat[K, V]]
hadoopFile(path, inputFormatClass, keyClass, valueClass, minPartitions)
}
def sequenceFile[K, V](
path: String,
keyClass: Class[K],
valueClass: Class[V]): RDD[(K, V)] = withScope {
assertNotStopped()
sequenceFile(path, keyClass, valueClass, defaultMinPartitions)
}
def sequenceFile[K, V]
(path: String, minPartitions: Int = defaultMinPartitions)
(implicit km: ClassTag[K], vm: ClassTag[V],
kcf: () => WritableConverter[K], vcf: () => WritableConverter[V]): RDD[(K, V)] = {
withScope {
assertNotStopped()
val kc = clean(kcf)()
val vc = clean(vcf)()
val format = classOf[SequenceFileInputFormat[Writable, Writable]]
val writables = hadoopFile(path, format,
kc.writableClass(km).asInstanceOf[Class[Writable]],
vc.writableClass(vm).asInstanceOf[Class[Writable]], minPartitions)
writables.map { case (k, v) => (kc.convert(k), vc.convert(v)) }
}
}
//5.newAPIHadoop文件
def newAPIHadoopFile[K, V, F <: NewInputFormat[K, V]]
(path: String)
(implicit km: ClassTag[K], vm: ClassTag[V], fm: ClassTag[F]): RDD[(K, V)] = withScope {
newAPIHadoopFile(
path,
fm.runtimeClass.asInstanceOf[Class[F]],
km.runtimeClass.asInstanceOf[Class[K]],
vm.runtimeClass.asInstanceOf[Class[V]])
}
def newAPIHadoopFile[K, V, F <: NewInputFormat[K, V]](
path: String,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V],
conf: Configuration = hadoopConfiguration): RDD[(K, V)] = withScope {
assertNotStopped()
//...
}
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
/**
* Default min number of partitions for Hadoop RDDs when not given by user
* Notice that we use math.min so the "defaultMinPartitions" cannot be higher than 2.
* The reasons for this are discussed in https://github.com/mesos/spark/pull/718
*/
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
2.1.2 对一个Seq并行化
sc.makeRDD(seq[,numPartition])
sc.parallelize(seq[,numPartition])
说明:
- seq是指Seq集合
- numPartition是指分区个数(并行度)
在源码中makeRDD、parallelize方法定义如下:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
2.1.3案例
- 分别使用
textFile和wholeTextFiles方法读取/opt/spark/README.md文件。
object RDDTest1{
def main(args:Array[String])={
//1.获取SparkConf对象
val conf=new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("案例1")
//2.获取SparkContext对象
val sc=new SparkContext(conf);
sc.setLogLevel("warn")
//3.构建RDD
//3.1使用textFile读取文本文件
val rdd1=sc.textFile("/opt/spark/README.md")
println(rdd1.count)
println(rdd1.first)
//3.2使用wholeTextFiles读取文本文件
val rdd2=sc.wholeTextFiles("/opt/spark/README.md")
println(rdd2.count)
println(rdd2.first)
//5.关闭SparkContext对象
sc.stop()
}
}
观察,rdd1和rdd2调用相同方法输出有什么不同?
- 通过对
Seq集合并行化构建RDD
object RDDTest2{
def main(args:Array[String])={
//1.获取SparkConf对象
val conf=new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("案例2")
//2.获取SparkContext对象
val sc=new SparkContext(conf);
sc.setLogLevel("warn")
//3.构建RDD
//使用makeRDD将seq集合并行化
val seq=1 to 10
val rdd1=sc.makeRDD(seq)
//4.1调用map方法将rdd1中每个元素+1,返回一个新的RDD
val rdd2=rdd1.map(x=>x+1)
//4.2将rdd2中的元素输出到控制台
rdd2.foreach(println)
//5.关闭SparkContext对象
sc.stop()
}
}
注意,通过以上两个案例的编写,发现每次都需要构建SparkContext对象,且代码基本一致。
思考3,是否可以封装SparkContext对象的构建过程?如果可以的话,如何实现?
借助于Scala里面的包对象实现封装:
package com
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Duration, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark使用工具类
* 方便构建使用Spark
* */
package object briup {
private var _conf:Option[SparkConf]=None;
private var _sc:Option[SparkContext]=None;
private var _spark:Option[SparkSession]=None;
private var _ssc:Option[StreamingContext]=None;
implicit val jarFilePath:Option[String]=None;
/**
*
* 获取SparkConf对象
**/
private def getConf(master:String,appName:String,checkPoint:String="spark-checkpoint"):SparkConf={
_conf match{
case Some(conf) => conf
case None =>
val conf=new SparkConf()
conf.setMaster(master)
conf.setAppName(appName)
conf.set("spark.sql.streaming.checkpointLocation",checkPoint)
_conf=Some(conf)
conf
}
}
/**
* 获取SparkContext对象
* */
def getSparkContext(master:String,appName:String)(implicit jarFilePath:Option[String]=None):SparkContext={
_sc match{
case Some(sc) => sc
case None =>
val conf=getConf(master,appName)
//第一种构建方式
// val sc=new SparkContext(conf);
//第二种构建方式
val sc=SparkContext.getOrCreate(conf);
jarFilePath match {
case Some(filepath) => sc.addJar(filepath)
case None =>
}
_sc=Some(sc)
sc.setLogLevel("warn")
sc
}
}
/**
* 获取SparkSession对象
* */
def getSpark(master:String,appName:String,checkPoint:String="spark-checkpoint")(implicit jarFilePath:Option[String]):SparkSession={
_spark match{
case Some(spark) =>
// println("...获取已经存在的Spark...")
spark
case None =>
// println("...开始创建Spark...")
val conf=getConf(master,appName)
val spark=SparkSession.builder().config(conf).getOrCreate();
jarFilePath match {
case Some(filepath) => spark.sparkContext.addJar(filepath)
case None => //println("无jarFilePath......");
}
_spark=Some(spark)
spark
}
}
/**
* 获取StreamingContext对象
* */
def getStreamingSpark(master:String,appName:String,batchDur:Duration)(implicit jarFilePath:Option[String]=None):StreamingContext={
_ssc match{
case Some(ssc) =>ssc
case None =>
val conf=getConf(master,appName)
val ssc=new StreamingContext(conf,batchDur)
jarFilePath match {
case Some(filepath) => ssc.sparkContext.addJar(filepath)
case None => //println("无jarFilePath......");
}
_ssc=Some(ssc)
ssc
}
}
}
- 操作
非文本数据文件
数据目录:hdfs://172.16.0.4:9000/data/grouplens/ml-1m/users.dat
数据说明:用户ID::性别::年龄::职业代码::邮编
编码实现:
object RDDTest3{
def main(args:Array[String])={
//1.获取SparkConf对象
val conf=new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("案例3-各种数据练习")
//2.获取SparkContext对象
val sc=SparkContext.getOrCreate(conf)
//3.获取RDD+4.RDD操作
//1.读取文本文件构建RDD
val rdd=sc.textFile("hdfs://172.16.0.4:9000/data/grouplens/ml-1m/users.dat")
//2.输出到控制台
rdd.foreach(println)
//3.保存为对象文件 注意,该参数为路径名称
rdd.saveAsObjectFile("users_obj")
//4.读取对象文件
val objectRDD=sc.objectFile[String]("users_obj")
//5.输出到控制台
objectRDD.foreach(println)
//6.读取字节文件
val binaryRDD=sc.binaryFiles("hdfs://172.16.0.4:9000/data/grouplens/ml-1m/users.dat")
//8.输出到控制台
binaryRDD.foreach(println)
//9.保存为Sequence文件
objectRDD.map(str=>(str.length,str)).saveAsSequenceFile("users_seq")
//10.读取Sequence文件
val seqRDD=sc.sequenceFile[Int,String]("users_seq")
//11.输出到控制台
seqRDD.foreach(println)
//12.保存为Hadoop格式的文件
seqRDD.map(tu=>(new IntWritable(tu._1),new Text(tu._2))).saveAsNewAPIHadoopFile[SequenceFileOutputFormat[IntWritable,Text]]("users_hadoop")
//13.读取Hadoop格式的文件
val hadoopRDD=sc.newAPIHadoopFile[IntWritable,Text,SequenceFileInputFormat[IntWritable,Text]]("users_hadoop")
//14.输出到控制台
hadoopRDD.foreach(println)
//5.关闭SparkContext对象
sc.stop()
}
}
思考4,学会了如何构建RDD,如何查看RDD中的分区个数?
2.2分区个数
获取分区个数:rdd对象.getNumPartitions
演示:
object RDDTest2{
def main(args:Array[String])={
//1.获取SparkConf对象
val conf=new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("演示1-分区个数")
//2.获取SparkContext对象
val sc=SparkContext.getOrCreate(conf)
//3.构建RDD
val rdd=sc.textFile("hdfs://172.16.0.4/data/grouplens/ml-1m/users.dat")
//3.1查看RDD的分区个数
println(rdd.getNumPartitions)
//5.关闭SparkContext对象
sc.stop()
}
}
注意,分区个数会决定Stage中Task的个数,分区个数是Spark任务调度中的并行度。
思考5,如何设置RDD的分区个数?
- 获取RDD时指定
- 读取外部文件时,可选参数minPartitions
- 不指定时为math.min(Spark任务调度中的并行度,2)
- minPartitions是指用户未给定时HadoopRDD的默认最小分区数
- 并行Seq集合时,可选参数numPartition
- 不指定时为Spark任务调度中的并行度
- numPartition是指分区数
- 读取外部文件时,可选参数minPartitions
- 重分区(调整RDD的分区个数)
rdd.repartition(numPartitions:Int)rdd.coalesce(numPartitions:Int,shuffle:Boolean)pairRdd.repartitionAndSortWithinPartitions(partitioner: Partitioner)
重分区的方法源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](
mapPartitionsWithIndexInternal(distributePartition, isOrderSensitive = true),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
def repartitionAndSortWithinPartitions(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
new ShuffledRDD[K, V, V](self, partitioner).setKeyOrdering(ordering)
}
思考6,重分区一定需要通过网络混洗吗?
注意:
- 对于
repartition和coalesace方法,Spark建议使用repartition的优化版coalesace - 如果重分区之后需要对分区内的数据进行排序,Spark建议使用
repartitionAndSortWithinPartitions
演示:
object RDDTest2{
def main(args:Array[String])={
//1.获取SparkConf对象
val conf=new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("演示2-分区个数")
//2.获取SparkContext对象
val sc=SparkContext.getOrCreate(conf)
//3.1构建RDD时指定分区个数
val rdd1=sc.textFile("hdfs://172.16.0.4/data/grouplens/ml-1m/users.dat")
println(rdd1.getNumPartitions)
val rdd2=sc.textFile("hdfs://172.16.0.4/data/grouplens/ml-1m/users.dat",5)
println(rdd2.getNumPartitions)
val rdd3=sc.makeRDD(1 to 10)
println(rdd3.getNumPartitions)
val rdd3=sc.makeRDD(1 to 10,4)
println(rdd3.getNumPartitions)
//3.2重分区调整分区个数
println(s"重分区 repartition 前:分区个数:${rdd1.getNumPartitions}")
val re_rdd1=rdd1.repartition(3)
println(s"重分区 repartition 后:分区个数:${re_rdd1.getNumPartitions}")
println("-----调小分区个数-------")
println(s"重分区 coalesce 前:分区个数:${rdd2.getNumPartitions}")
val co_rdd2=rdd2.coalesce(3)
println(s"重分区 coalesce 后:分区个数:${co_rdd2.getNumPartitions}")
println("-----调大分区个数-------")
println(s"重分区 coalesce 前:分区个数:${rdd2.getNumPartitions}")
val co_rdd2=rdd2.coalesce(10)
println(s"重分区 coalesce 后:分区个数:${co_rdd2.getNumPartitions}")
println(s"重分区 repartitionAndSortWithinPartitions 前:分区个数:${rdd3.getNumPartitions}")
val partitioner=new HashPartitioner(5)
val ras_rdd3=rdd3.map(x=>(x,1)).repartitionAndSortWithinPartitions(partitioner)
println(s"重分区 repartitionAndSortWithinPartitions 后:分区个数:${ras_rdd3.getNumPartitions}")
//5.关闭SparkContext对象
sc.stop()
}
}
思考7,coalesce方法中第二个参数的含义?coalesce优于repartition的原因?
原因:
repartition操作一定会产生Shuffle操作,网络开销大,性能降低。coalesce针对调小分区个数可以不用产生Shuffle操作,故可以节省网络开销,提高效率。
思考8,coalesce针对调大分区个数一定要产生Shuffle操作吗?为什么?
原因:
- 调小分区个数,可以让多个分区直接进行合并为一个大分区,可以不需要Shuffle。
- 调大分区个数,需要将一个分区内的数据打乱分发到多个分区,必须借助于Shuffle。
