Cross-Domain Transformer用于无监督域自适应ICLR2022

前置内容:Cross Attention(Transformer的解码器部分)
自注意力的计算回顾关于自注意力机制的思考;
key-value注意力的计算为: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Attention(Q,K,V)=softmax(dkQKT)V
交叉注意力和自注意力均来自Transformer,除了输入,交叉注意力的计算与自注意力一样。交叉注意力不对称地结合了两个相同维度的独立embedding序列,自注意力输入是一个单一的embedding序列。
通常,对于注意力的计算,其中一个序列用作query输入,另一个用作key和value输入。即:
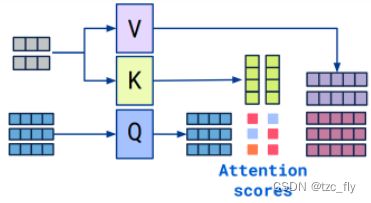
对于交叉注意力,query和value来自同一个序列,key来自另一个序列。即:
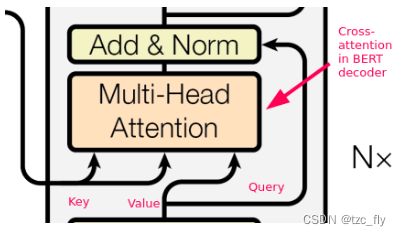
在Transformer的解码器部分:
目录
- 摘要
- 1.Introduction
- 2.Related Work
-
- 2.1.Transformer for vision
- 2.2.Unsupervised domain adaptation
- 2.3.Pseudo labeling
- 3.Method
-
- 3.1.Cross Attention in Transformer
- 3.2.Two-way center-aware pseudo labeling
- 3.3.CDTrans
- 4.Experiments
-
- 4.1.Dataset and implementation
- 4.2.Results
- 个人总结
摘要
无监督域自适应(Unsupervised domain Adaption,UDA)旨在将knowledge从有标记的源域转移到另一个未标记的目标域。大多数现有的UDA方法都侧重于使用基于卷积神经网络(CNN)的框架,从 domain level 或 category level 学习域不变的特征表示。基于category级别的UDA的一个基本问题是为目标域中的样本生成伪标签(pseudo lable),这通常有太多noisy,无法进行精确的域对齐(domain alignment),从而不可避免地影响UDA的性能。随着Transformer在各种任务中的成功,我们发现Transformer中的 cross attention 对噪声输入对(noisy input pairs)具有鲁棒性,以便更好地进行特征对齐(feature alignment),因此本文采用Transformer来完成具有挑战性的UDA任务。具体来说,为了生成准确的输入对,我们设计了一种双向中心感知标记算法(two-way center-aware labeling algorithm),为目标样本生成伪标签。在伪标签的基础上,提出了一种权重共享的三分支transformer框架(triple-branch transformer framework),分别将自注意和交叉注意应用于源-目标特征学习和源-目标域对齐。这种design明确地强制框架同时学习区分性的domain-specific表示和domain-invariant表示。提出的方法被称为CDTrans,它提供了使用Transformer解决UDA任务的尝试。实验表明,我们提出的方法在公共UDA数据集,如VisDA-2017和DomainNet上取得了最好的性能。
1.Introduction
深度神经网络在广泛的应用场景中取得了显著的成功,但由于域转移(domain shift)问题,它对其他新域的泛化性能仍然很差。为了解决这个问题并避免昂贵费力的注释,许多研究工作都致力于无监督域适应(UDA)。UDA任务旨在将从labeled的源域学到的知识转移到另一个未标记的目标域。在UDA中,大多数方法侧重于对齐源域和目标域的分布,并学习域不变的特征表示。其中一种UDA方法基于category级对齐,使用深度卷积神经网络(CNN)在公共UDA数据集上取得了有希望的结果。基于category级别的对齐的基本问题是为目标域中的样本生成伪标签,以生成输入:source-target pairs。然而,当前基于CNN的方法对含有noisy的伪标签不具有鲁棒性,无法实现精确的域对齐。
随着Transformer在NLP和CV上的成功,研究发现,Transformer中的交叉注意力能够很好地对齐不同的分布,即使是从不同的模式,例如 vision-to-vision、vision-to-text 和 text-to-speech。我们发现它对伪标签中的噪声具有一定的鲁棒性。因此,在本文中,我们将Transformer应用到UDA任务,以利用其对噪声的鲁棒性和用于特征对齐的能力来处理CNN中的上述问题。
在我们的实验中,我们得出结论,即使labeling pair中存在噪声,交叉注意力仍然可以很好地调整两个分布。为了获得更精确的伪标签,我们设计了一种双向中心感知的目标域样本标签算法(two-way center-aware labeling algorithm)。基于corss-domain相似度矩阵生成伪标签,并通过中心感知匹配对矩阵进行加权,将噪声削弱到可容忍的范围内。借助伪标签,我们为UDA设计了CDTrans。它由三个权重共享Transformer分支组成,其中两个分支分别用于源数据和目标数据,第三个分支是特征对齐分支,其输入来自source-target pair。自注意力应用于源或目标Transformer分支,交叉注意力涉及特征对齐分支以进行域对齐。这种design明确地强制框架同时学习区分性的域特定和域不变表示。总之,我们的贡献有三个方面:
- 我们提出了一种权值共享的三分支框架,即CDTrans,利用其对噪声标记数据的鲁棒性和强大的特征对齐能力,实现精确的无监督域自适应。
- 为了产生高质量的伪标签,提出了一种双向中心感知标签方法,并在CDTrans环境下提高了最终性能。
- CDTrans在VisDA-2017和DomainNet数据集上取得了与最先进水平相比的最佳性能。
2.Related Work
2.1.Transformer for vision
Transformer用于对NLP领域的顺序数据进行建模。许多研究表明其对计算机视觉任务的有效性。基于纯Transformer的模型正变得越来越流行。例如,ViT是2020年提出的,通过向Transformer提供图像patches序列;Touvron等人提出DeiT,为Transformer引入蒸馏策略,以帮助ViT训练;此后提出了许多其他ViT变体(variants),与对应的CNN相比,这些变体在图像分类和下游任务上取得了很好的性能。对于基于多模态的网络,有几项研究将交叉注意应用于多模态特征融合,这表明注意力机制在提取噪声和特征对齐方面非常强大。
2.2.Unsupervised domain adaptation
UDA方法主要有两个级别:域级别和类别级别。域级UDA通过在不同规模级别将源域和目标域拉到同一分布中来缓解分布差异。常用的差异度量包括最大平均差异(MMD,Maximum Mean Discrepancy)和相关校准(CORAL,Correlation Alignment)。最近,一些工作专注于细粒度category级别的标签分布对齐,通过特征提取器和两个特定于域的分类器之间的对抗方式。与域scale内的粗粒度对齐不同,这种方法通过将目标域样本推送到每个类别中的源域样本分布来对齐源和目标域数据之间的每个类别分布。显然,细粒度对齐可以在同一标签空间内实现更精确的分布对齐。尽管对抗性方法通过在类别级别融合源样本和目标样本的细粒度对齐操作实现了新的改进,但它仍然不能解决错误类别中的噪声样本问题。我们的方法采用Transformer作为类别级UDA来解决噪声问题。
2.3.Pseudo labeling
伪标记2013年首次被引入半监督学习(semi-supervised),并在域适应任务中得到普及。它学习使用预测概率(predicted probabilities)标记无标签的数据,并与标记的数据一起微调。在域适应任务中使用伪标签方面,Long等人采用伪标签进行条件分布对齐;Zhang使用伪标签作为域适应的正则化;Zou等人通过交替解决伪标签的方法设计了一个自训练框架;Caron等人提出了一种深度自监督方法,通过k均值聚类生成伪标签,逐步训练模型;Liang等人开发了一种自监督的伪标签方法,以减轻噪声伪标签的影响。基于Liang等人,在这项工作中,我们提出了一种双向中心感知标记算法来进一步过滤noisy pseudo pairs。
3.Method
3.1.Cross Attention in Transformer
Preliminary
ViT中最重要的结构之一是自注意力模块。在ViT中,一张图像 I ∈ R H × W × C I\in R^{H\times W\times C} I∈RH×W×C被reshape为一个2D flattened patches x ∈ R N × ( P 2 ⋅ C ) x\in R^{N\times(P^{2}\cdot C)} x∈RN×(P2⋅C)的序列,其中 ( H , W ) (H,W) (H,W)是原始图像的分辨率, C C C是通道数, ( P , P ) (P,P) (P,P)是每个patch的分辨率, N = H W / P 2 N=HW/P^{2} N=HW/P2是patches的数量。对于自注意力,patches首先被投影成三个向量,query Q ∈ R N × d k Q\in R^{N\times d_{k}} Q∈RN×dk,key K ∈ R N × d k K\in R^{N\times d_{k}} K∈RN×dk,value V ∈ R N × d v V\in R^{N\times d_{v}} V∈RN×dv。输出为value的加权和计算,其中分配给每个value的权重由query与相应key的函数计算。 N N N个patches作为自注意模块的输入,这个过程可以如下所示。自注意模块的目的是加强输入图像patches之间的关系。 A t t n s e l f ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attn_{self}(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Attnself(Q,K,V)=softmax(dkQKT)V交叉注意模块源于自注意模块。不同之处在于,交叉注意力的输入是一对图像(a pair of images),比如 I s I_{s} Is和 I t I_{t} It。query 和 key或者value 分别来自 I s I_{s} Is和 I t I_{t} It的patches。交叉注意力模块被计算为: A t t n c r o s s ( Q s , K t , V t ) = s o f t m a x ( Q s K t T d k ) V t Attn_{cross}(Q_{s},K_{t},V_{t})=softmax(\frac{Q_{s}K_{t}^{T}}{\sqrt{d_{k}}})V_{t} Attncross(Qs,Kt,Vt)=softmax(dkQsKtT)Vt其中, Q s ∈ R M × d k Q_{s}\in R^{M\times d_{k}} Qs∈RM×dk是来自图像 I s I_{s} Is的 M M M个patches的query, K t ∈ R N × d k , V t ∈ R N × d v K_{t}\in R^{N\times d_{k}},V_{t}\in R^{N\times d_{v}} Kt∈RN×dk,Vt∈RN×dv是来自图像 I t I_{t} It的 N N N个patches的key和value。交叉注意力的输出保持与query数相同的长度 M M M,对于每个输出, V t V_{t} Vt与注意力权重相乘,这些注意力来自 I s I_{s} Is中相应的query与 I t I_{t} It中的key。对于结果,在 I t I_{t} It中的所有patches中,与 I s I_{s} Is的query更相似的patches将拥有更大的权重,对输出的贡献更大。换句话说,交叉注意模块的输出会根据两幅输入图像的相似patches,对两个图像进行聚合。
到目前为止,许多研究人员已经将交叉注意力用于特征融合,尤其是在多模态任务中。在这些工作中,交叉注意力模块的输入来自两种模式,例如 视觉到文本、文本到语音 和 视觉到视觉。他们运用交叉注意力来聚合和调整来自两种模式的信息。鉴于交叉注意模块在特征对齐方面的强大功能,我们建议使用交叉注意模块来解决无监督域自适应问题。
Robustness to noise
如上所述,交叉注意模块的输入是一对图像,通常来自两个域,交叉注意模块旨在对齐这两个图像。如果标签噪声存在,训练数据中就会出现假阳性对。假阳性对中的图像将具有不同的外观,强行对齐它们的特征将不可避免地损害训练学习的知识并影响表现。我们假设假阳性对中的不相似patches比相似patches对性能的危害更大。在交叉注意模块中,两幅图像根据patches相似性对齐。如图1a所示,交叉注意模块将为假阳性对中的不相似patches分配低权重。因此,它在一定程度上削弱了不相似patches对最终性能的负面影响。

- 图1:(a) 假阳性对(汽车与卡车)的交叉注意权重热图。(b) 通过假阳性对的比率来改变UDA性能。红色和绿色曲线代表有无交叉注意模块的模型。蓝色曲线代表着交叉注意模块中只涉及真正的阳性对。
为了进一步分析这个问题,我们设计了一个实验。具体而言,我们从VisDA-2017数据集的源域和目标域中随机抽取真阳性对作为训练数据。然后我们手动将真阳性对替换为随机假阳性对以增加噪声,并观察性能的变化,如图1b所示。x轴表示训练数据中加入假阳性对的比率,y轴表示不同设置在UDA任务中的性能。红色曲线表示用交叉注意模块对齐pair的结果,而绿色曲线表示没有使用交叉注意模块的结果,即直接使用pair中相应源数据的标签来训练目标数据。可以看出,红色曲线比绿色曲线具有更好的性能,这意味着交叉注意模块对噪声的鲁棒性。我们还提供了另一个基线,如图1b中的蓝色曲线所示,即从训练数据中移除假阳性对,并仅使用真阳性对训练交叉注意模块。在没有噪声数据的情况下,这个基线可以被认为是我们方法的上限。我们可以看到红色曲线非常接近蓝色曲线,两者都比绿色曲线好得多。这进一步意味着交叉注意模块对噪声输入对具有鲁棒性。
3.2.Two-way center-aware pseudo labeling
Two-way labeling
为了建立交叉注意模块的训练对,一种直观的方法是,对于源域中的每个图像,我们设法从目标域中找到最相似的图像。所选pair的集合 P S P_{S} PS为: P S = { ( s , t ) ∣ t = m i n k d ( f s , f k ) , ∀ k ∈ T , ∀ s ∈ S } P_{S}=\left\{(s,t)|t=min_{k}d(f_{s},f_{k}),\forall k\in T,\forall s\in S\right\} PS={(s,t)∣t=minkd(fs,fk),∀k∈T,∀s∈S}其中, S , T S,T S,T分别为源域和目标域数据, d ( f s , f k ) d(f_{s},f_{k}) d(fs,fk)代表图像 i , j i,j i,j之间特征的距离。这种策略的优点是充分利用源数据,缺点是只涉及目标域数据的一部分。为了从目标域数据中消除这种训练偏差,我们从相反的方向引入了更多对 P T P_{T} PT,由所有目标数据及其对应的源域中最相似的图像组成: P T = { ( s , t ) ∣ s = m i n k d ( f t , f k ) , ∀ k ∈ S , ∀ t ∈ T } P_{T}=\left\{(s,t)|s=min_{k}d(f_{t},f_{k}),\forall k\in S,\forall t\in T\right\} PT={(s,t)∣s=minkd(ft,fk),∀k∈S,∀t∈T}因此,最终的集合 P P P是两个集合的并集。
Center-aware filtering
P P P中的pair是基于两个域图像的特征相似性建立的,因此伪标签的准确性在很大程度上取决于特征相似性。受Liang等人的启发,我们发现源数据的预训练模型也有助于进一步提高精度。首先,我们通过预训练模型计算所有目标域数据,并从分类器中获得它们在源域类别上的概率分布 δ δ δ。与Liang等人类似,这些分布可用于通过加权k-均值聚类计算目标域中每个类别的初始中心: c k = ∑ t ∈ T δ t k f t ∑ t ∈ T δ t k c_{k}=\frac{\sum_{t\in T}\delta_{t}^{k}f_{t}}{\sum_{t\in T}\delta_{t}^{k}} ck=∑t∈Tδtk∑t∈Tδtkft其中, δ t k \delta_{t}^{k} δtk代表图像 t t t在类别 k k k上的概率。目标域数据的伪标签可以通过最近邻分类器生成: y t = a r g m i n k d ( c k , f t ) y_{t}=argmin_{k}d(c_{k},f_{t}) yt=argminkd(ck,ft)其中, t ∈ T t\in T t∈T, d ( i , j ) d(i,j) d(i,j)是特征 i , j i,j i,j的距离。基于伪标签,我们可以计算新的簇: c k ′ = ∑ t ∈ T 1 ( y t = k ) f t ∑ t ∈ T 1 ( y t = k ) c_{k}'=\frac{\sum_{t\in T}1(y_{t}=k)f_{t}}{\sum_{t\in T}1(y_{t}=k)} ck′=∑t∈T1(yt=k)∑t∈T1(yt=k)ft在Liang等人的工作中,上面的更新公式可以更新为多轮,我们在论文中只采用了一轮。然后使用最终的伪标签来优化所选pair。具体地说,对于每一对,如果目标图像的伪标签与源图像的标签一致,这一对将被保留用于我们的训练,否则它将作为噪声被丢弃。
3.3.CDTrans
CDTrans的框架如图2所示,它由三个权重共享Transformer组成。权重共享分支有三个数据流和约束。框架的输入是从上述的labeling方法中选择的pair。这三个分支被命名为源分支、目标分支、源-目标分支。如图2所示,输入对中的源和目标图像分别被发送到源分支和目标分支。在这两个分支中,自注意力用于学习域特定(domain-specific)的表示。并利用softmax交叉熵损失对分类进行训练。值得注意的是,由于两个图像的标签相同,这三个分支共享相同的分类器。

- 图2:CDTrans由三个权重共享的Transformer组成,通过Two-way center-aware labeling方法生成输入的pair。交叉熵用于调整 source branch H S H_{S} HS 和 target branch H T H_{T} HT,distillation loss(蒸馏损失)用于 source-target branch H S + T H_{S+T} HS+T 和 H T H_{T} HT。
交叉注意模块被源-目标分支使用。源-目标分支的输入来自其他两个分支。在第 N N N层,cross-attention的query来自第 N N N层source branch的query,而key和value来自target branch的key和value。然后交叉注意模块输出对齐的特征,并且与第 N − 1 N-1 N−1层的输出相加。
源-目标分支的特征不仅符合两个域的分布,而且由于交叉注意模块,对输入对中的噪声具有鲁棒性。因此,我们使用源-目标分支的输出来指导目标分支的训练。具体来说,源-目标分支和目标分支分别表示为教师和学生。我们将分类器在源-目标分支中的概率分布视为软标签,通过蒸馏损失进一步监督目标分支学习: L d t l = ∑ k q k l o g ( p k ) L_{dtl}=\sum_{k}q_{k}log(p_{k}) Ldtl=k∑qklog(pk)其中, q k q_{k} qk和 p k p_{k} pk为类别 k k k在source-target分支输出的概率,和在target分支输出的概率。
在推理(inference)过程中,只使用目标分支。输入是来自测试数据的图像,并且仅触发目标域的数据流,即图2中的蓝线。分类器的输出被用作最终的预测标签。
4.Experiments
4.1.Dataset and implementation
提出的方法在四个流行的UDA基准上进行了验证,包括VisDA-2017、Office Home、Office-31和DomainNet。在DomainNet数据集中,我们遵循其他数据集的设置方法,使用traget域的全部数据进行训练和测试。实验中的输入图像大小为224×224。DeiT small和DeiT base都被用作我们进行比较的基础。我们使用动量为0.9、权重衰减率为1e-4的随机梯度下降算法来优化训练过程。Office Home、Office-31和DomainNet的学习率设置为3e-3,VisDA-2017的学习率设置为5e-5。批处理大小设置为64。
4.2.Results
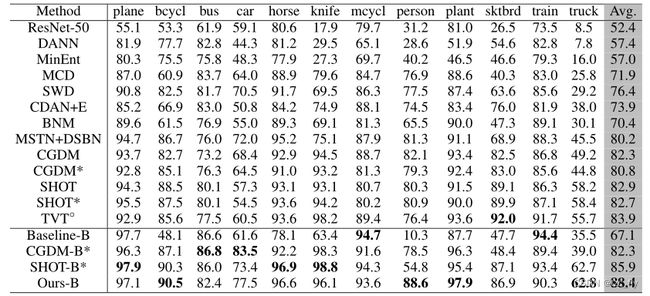
- 表1:与VisDA-2017上的SoTA方法进行比较。
个人总结
CDTrans中,Transformer的交叉注意力用于特征融合,或者特征对齐。该思想可以用到后续的DA问题。
对于非密集型的固定category伪标签生成,可以使用论文中提到的想法,基于K-means迭代生成伪标签。
可以采用这种简单的教师-学生分支,采用蒸馏学习优化target branch。