FastSpeech2论文中文翻译
FastSpeech2
论文的翻译,翻译的挺差的,大概是那意思
只翻译了摘要、模型部分和实验部分
摘要:
高级的TTS模型像fastspeech 能够显著更快地合成语音相较于之前的自回归模型,而且质量相当。FastSpeech模型的训练依赖于一个自回归的教师模型为了时长的预测(为了提供更多的信息作为输入)和知识蒸馏(为了简化数据的分布在输出里),这种知识蒸馏能够解决一对多的映射问题(也就是相同文字下的多语音变化)在tts中。然而,Fastspeech有几个缺点:1、教师-学生的蒸馏管道是复杂的。2、从教师模型中提取的时长不是足够准确的,并且从教师模型蒸馏出来的目标mel谱遭受信息的损失导致了数据简化,这两者都限制了声音的质量。在这篇文章中,我们提出了Fastspeech2,这个能够解决fastspeech中的问题并且更好的解决了TTS中的一对多映射问题。通过以下方式:1、直接训练模型通过真实目标代替了教师的简化输出。2、引入更多的语音变量信息(像音高、能量和更精准的时长)作为条件输入。具体来说,我们从语音波形提取了时长、音高和能量,直接把它们作为条件条件输入在训练阶段,并且使用预测值在推理阶段。我们进一步设计了fastspeech2s,这个是第一次尝试去平行地直接产生语音波形从文本中,享受全端到端训练的优点并且甚至可以更快推理相比于FastSpeech。实验结果展示:1、fastspeech2和2s超越了fastspeech的声音品质在更简化训练管道和减少训练时间的基础上。2、fastspeech2和2s能够匹配自回归模型的声音品质,但是推理速度远远快于自回归模型。能听的声音样本在:https://speechresearch. github.io/fastspeech2/
模型部分:
在这一部分,我们第一描述FS2的设计动机,并且介绍了FS2的体系结构,目标是改进FS,更好的解决一对多映射问题,简化训练,得到更高品质的声音。
动机:之前自回归可以通过之前的语音信息预测,但是非自回归中只有文本信息,信息不足导致目标语音变化敏感,泛化能力弱。(可能是加embedding也没法提取想要的信息)
FS设计了2个方式去解决一对多问题:一个是减少数据方差通过在目标侧的知识蒸馏,简化了目标。二是引入了时长信息(从教师模型中的attention map提取的)为了展开文本序列匹配mel谱的长度,这些可以提供更多的输入信息解决一对多问题。尽管知识蒸馏和从教师模型提取时长信息能供提高FS的训练效果,他们也带来了几个问题:一是两个阶段 教师-学生训练管道导致训练过程过于复杂。二是信息丢失(重复3遍了。。。)给了2表证明上面的话
在FS2中,删了教师-学生蒸馏简化了训练过程,用真实语音避免损失,提高了时长的准确性和引入了更多信息解决一对多,下面详细说。
模型概述
FS2总体结构图如下所示:
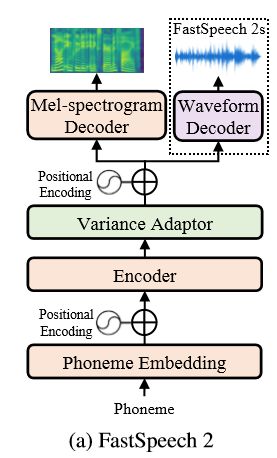
Encoder转换了音素序列到隐藏序列,并且【变量adaptor】加入了不同的变量信息,如时长、音高、能量到隐藏序列中,最终mel谱解码器平行地转换了被adapted(翻译成适应过的?大概意思就是加了那些乱七八糟信息的)的隐藏序列到mel谱序列中。我们使用了前馈形的Transformer块,这种Transformer块是由自注意力层和1d卷积叠加而成的,作为基础结构在encoder和mel谱decoder中。不同于FS依赖于教师-学生蒸馏管道和从教师模型得到的音素时长。FS2做了重大的提高,首先,我们删了教师-学生蒸馏管道并直接用真实语音做目标(太罗嗦了,上面说好几遍了,不翻了)。第二,我们的变量适配器不仅包括长度调节,还包括了音高和能量的预测,长度调节使用的是通过强制切分获得的音素时长,强制切分比自回归教师模型的注意力层准确得多。并且附加的音高和能量预测能够提供更多的变量信息,对于tts一对多映射问题的解决是重要的。第三,又说了一遍FS2s的端对端优点,没有mel谱了。。在下面的小节中,我们将详细介绍我们的方法中的【变量适配器】和直接波形生成的设计。
变量适配器
【变量adaptor】的目标是增加变量信息(如时长、音高、能量等)到音素隐藏序列,为了能够提供足够的信息去预测变化的语音为了tts一对多映射问题。结构如下所示:
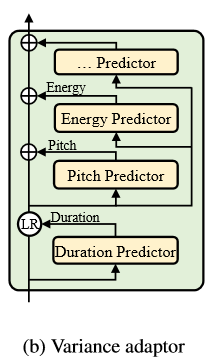
【变量adaptor】由1、时长预测器2、音高预测器和3、能量预测器组成,更多的变化信息可以被【变量adaptor】加入,这些信息将在接下来讨论。在训练阶段,我们用从记录中提取的真实的时长、音高、能量值作为输入到隐藏序列去预测目标语音,同时,我们分别单独的预测时长、音高和能量,这些被用来在推测阶段去合成目标语音。在这一小节,我们首先描述了【变量预测器】的模型细节,然后描述如何让时长、音高和能量信息在【变量adaptor】中起到影响。
变量预测器:如图所示:
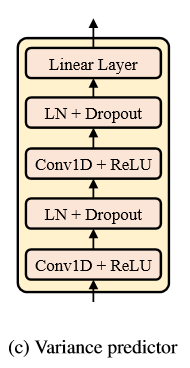
变量预测器有相似的模型结构和FS中的时长预测器。这把隐藏的序列作为输入并且预测了每个音素(时长)的变化,或每一帧(音高和能量)通过均方误差损失。变量预测器由2层的ReLU激活的1D卷积网络组成,每一层都紧跟着LN(层标准化)和dropout层,并且一个额外的线性层去投影隐藏状态到输出序列。对于时长预测器,时长是每个音素在对数域上的长度。对于音高预测器,输出序列是帧级F0序列,对于能量预测器,输出是每个mel谱帧的能量序列。所有的预测器共享相同的模型结构但是不同的模型参数。
变量信息的细节:除了文字,语音录音通常包含了大量的其他变量信息,包括:1、音素时长,代表了语速。2、音高,传达感情的关键,对于感知有着很大的影响。3、能量,指示mel谱的帧级幅度,直接影响mel谱计算的损失。4、感情,风格、说话人等等。变量信息不完全是文本决定的,由于一对多映射问题,是有害于非自回归TTS模型的训练的,在这个阶段,我们描述了细节关于使用音高、能量和时长在【变量adaptor】。
时长:为了提高分割的准确性并减少输入输出之间的信息差距,代替了通过使用预训练自回归TTS提取音素时长,我们提取了音素时长通过MFA,一个高性能的开源的语音文字切割系统,它可以在成对文本音频语料库上训练,而无需任何手动对齐注释。我们转换了MFA的结果到音素级序列并且把它喂给长度修正器(大概是fastspeech里的方法?所谓的LR?)去展开因素序列的隐藏状态
音高和能量:我们提取了F0从原始的波形(用pyworld提的,没有用有/没有声音的flags,直接把没有声音的帧置零,对于合成语音没有影响),提取时候用和目标谱相同的帧移为了观察每一帧的音高,并且计算了每个stft帧的振幅的L2范数作为能量。然后我们量化了每帧的f0和能量到256种可能值(f0是对数刻度的,能量是原始值)并且分别编码他们到一个one-hot矩阵序列中。在训练过程中,我们对音高和能量查表,嵌入到p和e中,(就是常用的lookup embedding?)并将它们添加到隐藏序列中。音高和能量的预测器直接预测F0和能量的值代替one-hot矩阵并用均方误差训练。在推理阶段,我们预测F0和能量使用变量预测器。
FastSpeech2s:
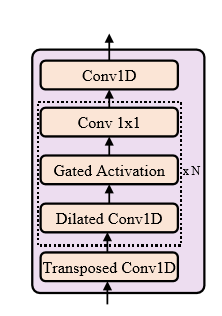
先不翻译了,简单概括下就是主要参考了wavenet和p-wavegan,用了对抗的设计(gan),也用了stft损失,应该就是把一个类似p-gan接在了网络后边。后面比训练速度的时候,这个也没有比,估计由于带了声码器,所以训练挺慢的
实验部分:
实验装置:
数据集:我们评价fs2用了ljspeech。大概13100英语音频片段(24小时)和对应的文字。我们把数据集分割为三部分,12228个样本训练用,349个样本(LJ003)验证,523个(LJ001和LJ002)用来测试。为了缓解错误发音问题,我们转换了文本序列到音速序列,用了别人的开源工具包(https://github.com/Kyubyong/g2p)。根据shen的研究,我们转换原始波形到mel谱,并设置帧长和帧移分别为1024和256,采样率为22050。
模型配置:我们的fastspeech由4个前馈形Transformer(FFT)块组成,在编码器和mel解码器中。在每个FFT块中,音素嵌入的维度和自注意力隐藏大小设置为256。注意力头的数量设置为2并且在自注意力层后的2层卷积网络中的1D卷积的核大小被设置为9(也太绕了吧。。。)。输入/输出大小为256/1024是第一层网络并1024/256是第二层网络(这个大概说的是上面的2层卷积网络?)。输出的线性层转换256维隐藏状态到80维mel谱。并且用MAE做优化。音素的词典大小是76,包含了标点符号。在变量预测器中,1d卷积的卷积核大小设置为3,这两层的输入/输出的维度为256/256,并且dropout速率设置为0.5。我们的波形解码器(fastspeech2s)由1层滤波器大小64的转置1D卷积和30层扩张残余卷积块组成,其1D卷积的跳过通道大小和核大小分别设置为64和3。FS2s中的D(鉴别器)的配置和P-gan相同。底下列出了实验中使用的所有模型的超参数和配置。
训练和推理:我们训练Fast speech2在1张nvidia V100上,batchsize是48个句子。我们使用Adam优化器,其中β1 = 0.9, β2 = 0.98, ε = 10−9并和【attention is all you need】使用相同的学习率计划表。训练到160k步收敛。在推理阶段,mel谱通过训练好的p-gan生成音频。
Fastspeech2s中,我们训练模型在2张v100上,batchsize是每个GPU上6句,波形解码器以20480个波形样本片段对应的切片隐藏状态作为输入。优化器和学习率跟fs2相同。对抗训练的细节跟p-wavegan一样,需要6000k步收敛。
后续部分基本为结果对比及分析,暂时不翻译了,大概就是Fs2s效果很好。。。
参数表:
