现代光学字符识别技术综述
A survey of modern optical character recognition techniques
文章目录
-
- 摘要
- 1 介绍
-
- 1.1 OCR是模式识别的一个成功分支
- 1.2 两类OCR系统
- 1.3 现代OCR的主要趋势
- 1.4 本报告的主要关注点和动机
- 2 光学字符识别
-
- 2.1基本ocr技术
- 2.2当前可用的OCR系统
-
- 2.2.1商用OCR解决方案
- 2.2.2 开源领域OCR资源
- 2.3光学字符识别困难的原因
- 2.4 文档图像类型
-
- 2.4.1扫描文件
- 2.4.2 其他媒体
- 2.5 脚本和语言问题
-
- 2.5.1 复杂文字(复杂字符脚本)
- 2.5.2 处理各种脚本的技术
- 2.6 语言混合的效果
- 2.7 字符类型
- 2.8 手写字体识别
- 2.9 灵活性
- 2.10 准确率
-
- 2.10.1 When ground truth is present
- 2.10.2 When ground truth is absent
- 2.10.3 商用OCR引擎精度
- 2.11 Productivity
-
- 2.11.1 通用阅读器
- 2.11.2 任务特定读卡器
- 3 OCR预处理
-
- 3.1 文档图像缺陷
- 3.3 文档分割
-
- 3.3.1文本与其他材料
- 3.3.2 查找文本行
- 3.3.3 文本阅读顺序检测
- 4 OCR后处理
- 5 总结
-
- 5.1 结论
- 5.2有前途的方向
摘要
本报告探讨了数字文档识别领域的最新进展。以印刷文档图像为重点,讨论了光学字符识别(OCR)和文档图像增强/恢复在拉丁和非拉丁文字应用中的主要发展。此外,我们还回顾和讨论了现有的手写文档识别技术。在本报告中,我们还提供了一些公司在现有OCR引擎上积累的基准结果。
1 介绍
光学字符识别(OCR)是将机器打印或手写文本(数字、字母和符号)扫描图像转换为机器可读字符流、纯文本(如文本文件)或格式化(如HTML文件)的过程。如图1所示,典型OCR系统中的数据路径包括三个主要阶段:
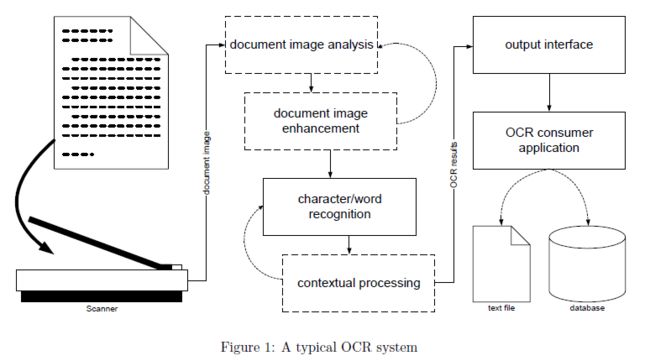
- 文档数字化
- 字符/单词识别
- 输出分布
在第一阶段中,扫描器以光学方式捕获文档中的文本并生成文档图像。扫描仪技术的最新进展使高分辨率文档扫描得到广泛应用。与早期的黑白模板匹配方法不同,现代基于特征的光学识别方法要求图像空间分辨率至少为每英寸200个点(dpi),并且可以从灰度文本图像中获益。较低的分辨率和简单的双调阈值往往会打断细线或填补空白,从而扭曲或使识别阶段所需的字符特征失效。
第二个(也是最有趣的)阶段负责文档图像中的字符和/或单词识别。该过程包括四个操作:
- 可选的图像分析:图像质量评估、文本行检测、文字和字符提取等。
- 可选的图像增强:去除斑点和其他图像噪声,填充孔洞和裂缝等。
- 字符/单词识别通常基于其形状和其他特征
- 可选的上下文处理来限制特性搜索空间
在第三(最后)阶段,输出接口将OCR结果传递给外部世界。
例如,许多商业系统允许将识别结果直接放入电子表格、数据库和文字处理程序中。其他商业系统在进一步的自动匹配处理中直接使用识别结果,当处理完成时,识别结果将被丢弃。在任何情况下,输出接口对OCR系统至关重要,因为它将结果传递给OCR系统之外的用户和程序域。
1.1 OCR是模式识别的一个成功分支
在历史上,光学字符识别被认为是一种解决特定类型的模式识别问题的技术。的确,要从给定的图像中识别一个字符,需要(通过一些已知的度量)将这个字符的特征模式与给定字母表中一些非常有限的已知特征模式参考集进行匹配。这显然是一个典型的模式识别问题。
字符分类一直是模式识别新思想的试验场,但由于许多此类实验都是在孤立的字符上进行的,其结果往往不能立即反映在OCR应用中。光学字符识别在其历史上一直在稳步发展,引发了一系列令人兴奋的研究课题,并产生了许多强大的实际应用。目前它被认为是机器视觉的最佳应用和模式识别理论中最成功的研究分支之一。
1.2 两类OCR系统
自从20世纪50年代引入OCR系统以来,已经开发了数百个OCR系统,其中许多系统在今天已经商业化。商业OCR系统大体上可以分为两类:任务专用阅读器和通用页面阅读器。
特定于任务的读取器仅处理特定的文档类型。一些最常见的任务特定的读卡器处理标准表单、银行支票、信用卡单等。这些读卡器通常使用定制的图像提升硬件,仅捕获几个预定义的文档区域。例如,银行支票阅读器可能只扫描“礼节金额”字段,而邮政OCR系统可能只扫描邮件上的地址块。这种系统强调高吞吐量和低错误率。诸如信件阅读之类的应用程序的一般吞吐量为每秒12个字母,错误率小于
2%。许多特定任务阅读器中的字符识别器能够识别手写文本和机器打印文本。
通用页面阅读器设计用于处理更广泛的文档,如商业信函、技术文章和报纸。典型的通用阅读器的工作原理是:捕捉文档页面的图像,将页面分为文本区域和非文本区域,对文本区域应用OCR,并将非文本区域与输出文本分开存储。大多数通用页面阅读器可以阅读机器书写的文本,但只有少数人能够阅读手写的字母数字。高端页面阅读器具有高级识别功能和高数据吞吐量。低端页面阅读器通常与一般的平板扫描仪兼容,这些扫描仪主要用于办公环境中的台式计算机,而台式计算机对系统精度或吞吐量的要求较低。一些商业OCR软件是自适应的,允许用户根据客户的数据对光学识别引擎进行微调,以提高识别精度。
1.3 现代OCR的主要趋势
光学字符识别是一个发展迅速的技术领域,目前已广泛应用于各种规模的项目中,从偶尔的文档扫描到创建大量的数字文档档案。然而,它仍然是一个活跃的科学研究和创造性工程领域。在现代OCR领域,我们可以发现以下主要的研究趋势:
自适应OCR旨在通过寻址来对更广泛的打印文档图像进行稳健处理
- 多脚本和多语言识别[17,39,40,56,85]
- 泛字体文本[8,36,49,81,64]
- 自动文档分割[15,19,41,47,57,63,66]
- 数学符号识别[19,26,35,62,89]
手写识别[11,85,86]是一种成熟的OCR技术,必须具有非常强大的适应性。总的来说,它仍然是一个被积极研究的开放性问题,对于一些特殊的应用,如
- 表格中手写文本的识别[16,72,77]
- 个人支票笔迹识别[48]
- 邮政信封和包裹地址阅读器[46]
- 便携式和手持设备中的OCR[33,34,60]
文档图像增强[12,18,55,88]涉及(自动)选择并将适当的图像过滤器应用于源文档图像,以帮助给定的OCR引擎更好地识别字符和单词。
智能后处理[9,13,45,51,73,93]对于提高OCR识别精度和创建健壮的信息检索(IR)系统具有重要意义,该系统利用智能索引和近似字符串匹配技术来存储和检索有噪声的OCR输出文本。
多媒体中的OCR[20,50,52,53,54,61,75,90]是一个有趣的发展,它适应了光学字符识别技术,而不是印刷文档,如照片、视频和互联网。
1.4 本报告的主要关注点和动机
这项调查的主要焦点是最新发展的光学字符识别应用于印刷文件图像。草书和手写体识别也被讨论,但程度较低。在后面的章节中,我们将在上述主题的背景下详细阐述正在进行的研究以及商业和公共领域的OCR解决方案。
更具体地说,第2节介绍了OCR领域及其主要技术,回顾了当前可用的OCR系统,然后详细阐述了脚本和语言问题、准确性和性能。第三节讨论了文档图像的缺陷、文档图像预处理和自动页面分割的重要性。在第4节中,我们将讨论在处理噪声OCR输出时出现的信息检索(IR)问题。在报告的最后,我们总结了所讨论的OCR问题,并对光学字符识别领域的一些有希望的方向进行了展望。
2 光学字符识别
虽然OCR代表“光学字符识别”,但一些OCR程序不是通过单个字符来识别文本,而是通过字符块、单词甚至单词组来识别文本。因此,为了使讨论更一般化,讨论识别单元或项目是有意义的。
2.1基本ocr技术
光学字符识别有各种各样的方法。 其中一些需要预先分割成识别项,其中一些不需要,但我们可以安全地期望任何OCR算法都拥有这两个基本组件:
- 一个特征提取器
- 一个分类器
给定项目图像,特征提取器导出项目所拥有的特征(描述符。 然后将导出的特征用作分类器的输入,该分类器确定(最有可能)已知的项与观察到的特征相关。 分类器还期望给出一个置信水平数,它告诉分类器对识别项的确定程度。 让我们简要描述一些经典的光学字符识别方法。
给定一个项目图像,特征提取器导出该项目所拥有的特征(描述符)。然后将派生的特征用作分类器的输入,分类器确定(最有可能)与观察到的特征相对应的已知项。分类器还需要给出一个置信度,该值表示分类器对已识别项的确定程度。让我们简单介绍一些经典的光学字符识别方法。
模板匹配是最常见和最基本的分类方法之一[70,第8.2节]。它也被称为矩阵匹配。一组所有的字符图像原型,模板,是收集和已知的先验知识。特征提取程序使用单个图像像素作为特征。字符分类是通过将输入字符图像与模板数组进行比较来执行的。每次比较都会导致输入字符和模板之间的相似性度量(由已知的“距离”函数给出)。当观察到的字符中的一个像素与模板图像中的相同像素相同(匹配)时,相似度增加。当对应的像素不同(不匹配)时,相似性度量可能降低。结果,角色的身份被指定为模板最相似的那个。
结构分类方法使用结构特征和决策规则对字符进行分类[70,第8.3节]。结构特征可以根据笔划、字符孔或其他字符属性(如角和凹面)来定义。例如,字母“P”可以被描述为“在右上侧附加有弯曲笔划的垂直笔划,形成一个孔”。为了对字符进行分类,提取输入字符的结构特征,并采用基于规则的系统来计算字符的类别。
请注意,上面的技术都是以它们的标准形式描述的,但是它们有许多方法上的变化和混合的方法。例如,模板匹配不必基于像素,例如可以匹配图像和模板的小波变换。结构分类并不总是依赖于决策规则,例如,可以使用一个在特征空间中具有适当度量的最近邻分类器。
许多现代OCR系统都是基于数学形式,以尽量减少一些误分类的措施。这种字符识别器可以使用基于像素的特征或结构特征。让我们谈谈其中的一些:
判别函数分类器利用多维特征空间中的超曲面,将字符的特征描述从不同的语义类中分离出来。这种分类器的目的是减少均方分类误差。
贝叶斯分类器通过使用概率论寻求最小化与字符误分类相关的损失函数。
人工神经网络(ANN)起源于人和动物的感知理论,利用误差反向传播技术学习一些非平凡的字符分类图,并利用数学优化技术来减少可能的分类误差。
2.2当前可用的OCR系统
自从第一个OCR系统引入以来,商业和公共领域的OCR系统已经有成百上千个了。下面,我们提到并简要地描述了一些当前可用的OCR引擎。
2.2.1商用OCR解决方案
许多商业OCR系统最初是大学项目、共享软件或免费软件程序,后来发展成成熟的高质量OCR引擎、软件开发工具包(SDK)和随时可用的软件产品,以满足当今OCR市场的高期望。
由ScanSoft提供的捕获开发系统12(http://www.scansoft.com/)通过提供精确的OCR引擎、先进的图像增强工具、文档处理功能和对广泛的输入/输出过滤器(包括PDF)的支持,使软件开发人员能够降低开发成本和上市时间,XML和开放电子书标准。标准版本处理欧洲脚本,并有一个扩展分别处理中文、日文和韩文。
ABBYY的FineReader 7.0(http://www.abbyy.com/)是专门为网络环境设计的OCR应用程序。它将高精度和格式保留与强大的网络功能相结合,为需要转换和复制各种纸质文档和PDF文件以进行编辑和归档的公司提供了一个良好的OCR解决方案。FineReader可以阅读177种语言,包括英语、德语、法语、希腊语、西班牙语、意大利语、葡萄牙语、荷兰语、瑞典语、芬兰语、俄语、乌克兰语、保加利亚语、捷克语、匈牙利语、波兰语、斯洛伐克语、马来语、印度尼西亚语等。内置拼写检查可用于34种语言。
Sakhr自动阅读器7.0(http://www.sakhr.com/)是阿拉比克文字的标准OCR阅读器之一。Sakhr-OCR结合了两种主要技术:Omni技术(依赖于人工智能的高度先进研究)和提高字符识别精度的训练技术。它可以通过Xerox文本桥技术实现文档图像的自动分割和多个脚本的识别。
诺沃德DX公司(http://www.novodynamics.com/)是一个集成信息检索(IR)系统,可以准确地处理用目标语言编写的大量文档。系统能够
- 准确处理降级文件
- 处理用亚洲语言编写的文件,例如阿拉伯语
- 扩展到多种语言
作为国防部项目的一部分,NovoDynamics最初设计此软件用于某些语言,并通过与In-Q-Tel的业务合作得到增强。
国际神经机器公司的neurtalker可以作为一个“快速、轻量级”的OCR引擎,它通过将图像复制到剪贴板,然后粘贴为文本来运行。
BBN是一个可训练的系统,声称完全独立于脚本,而不是训练和应用程序数据应该明显匹配。
Prime OCR是一个投票系统,一个人可以获得多达6个其他商业引擎在里面。
楔形文字被称为拉丁文字的快速OCR引擎。
Visulata的Visulata OCR软件在多个LINUX和UNIX平台上使用了Caere(ScanSoft)OCR技术。
2.2.2 开源领域OCR资源
大多数公开的(免费的)OCR软件主要是为基于UNIX和LINUX的系统开发的[25]。公有领域OCR程序是用C或C++等最流行的编程语言编写的,并与源代码一起分发,因此它们是开源系统。除了免费之外,开源OCR系统非常灵活,而且对软件开发人员非常友好。开源系统的一个明显的缺点是需要编译并使其在用户的本地平台上可执行,这需要一个合适的编译器,而且通常需要软件开发人员的专业知识。下面我们列出了一些这样的系统:
NIST基于表单的手印识别系统:[27,28]一个由NIST开发的基于标准参考表单的手印识别系统。识别系统处理与NIST专用数据库1和3一起分发的手写样本表格。系统读取包含数字、小写字母、大写字母的手写字段,并读取包含美国宪法序言的文本段落。源代码用于表单注册、表单移除、字段隔离、字段分段、字符规范化、特征提取、字符分类和基于字典的后处理。据悉,该系统已在Digital Equipment Corporation(DEC)Alpha、Hewlett-Packard(HP)型号712/80、IBM RS6000、Silicon Graphics Incorporated(SGI)Indigo 2、SGI Onyx、SGI Challenge、Sun Microsystems(Sun)IPC、Sun SPARCstation 2、Sun 4/470和Sun SPARC station 10上成功编译和测试。
Illuminator:[76]一个开源软件工具集,用于开发OCR和图像理解应用程序,由RAF Technology于1999年开发。Illuminator有两个主要部分:一个用于表示、存储和检索OCR信息的库(称为DAFSLib)和一个称为illum的X-Windows“DAFS”文件查看器。
CalPoly OCR:[84]软件最初是在Clint Staley教授的指导下为加利福尼亚理工州立大学的计算机视觉课程项目编写的。众所周知,该系统是字体专用的,可以很好地处理接受培训的高端HP激光打印机上的字体,但不能保证能在其他打印机上使用。它是加州保利利用大学资源开发的,因此只能用于学术目的,不能用于商业利益。
Xocr:[7]一个共享的OCR软件,由 Martin Bauer(Martin [email protected])r为LINUX系统上的X11编写。经过一些努力,它可以移植到SunOS。
2.3光学字符识别困难的原因
字符误分类主要来源于两个方面:识别单元(项目)图像质量差和分类器的识别能力不足。有许多因素会导致嘈杂、难以识别的物品图像:
- 原始文件质量差
- 噪声、低分辨率、多代图像扫描
- 图像预处理不正确或不足
- 项目分割不好
另一方面,字符识别方法本身可能对给定的字符(项)集缺乏适当的响应,从而导致分类错误。由于训练集有限或分类器的学习能力有限,这类错误很难处理。
机器印刷字符的典型识别率可以达到99%以上,但手写字符的识别率却始终较低,因为每个人的书写方式不同。这种随机性通常表现在特征空间中字符的变化更大,从而导致更高的误分类率。
“困难”字符的一个常见例子是字母“O”很容易与数字“0”混淆。另一个很好的例子是字母“l”与数字“1”混淆,或者被误认为是字母“I”的嘈杂图像。
Rice等人。[64,78]讨论人类与计算机的字符识别能力,并给出识别错误的示例。其错误原因分类的顶层包括:
- 由于重/轻打印、杂散标记、弯曲基线等造成的成像缺陷。
- 上述类似符号
- 由逗号和句点、引号、特殊符号等引起的标点符号。
- 由于斜体和间距、下划线、阴影背景、不寻常字体、非常大/小字体等造成的排版。
对当前系统的优势和不足之处进行深入分析,为未来系统的发展提供了一个思路。他们得出的结论是,目前的OCR设备即使在7岁儿童的水平上也无法阅读。作者认为有四个潜在的改进来源:
- 基于对打印、复印和扫描过程更精确的建模,更好地进行图像处理
- 通过将分类器微调到当前文档的字体,自适应字符分类
- 利用排版文本中的样式一致性进行多字符识别
- 根据文档的语言属性增加对上下文的使用,并且可能因语言而异
基于他们所遇到的错误的多样性,他们倾向于相信OCR的进一步进展更可能是多种技术组合的结果,而不是任何单一的新的总体原则的发现。
2.4 文档图像类型
大多数光学字符识别系统都是为处理白底黑文本的双色调图像而设计的。即使在这种看似简单的成像地形中,由于图像空间分辨率、颜色编码方法和压缩方案的变化,也存在着多种图像格式。
典型的传真扫描文档图像是双色调(每像素一位),空间分辨率为每英寸200点(dpi)。对于高质量的OCR,此分辨率可能并不总是足够的。现代字符识别引擎可以更好地处理扫描速度为300 dpi或更高的文档。数字图书馆试图合理地保持原始文档的质量,通常需要600 dpi的灰度(每像素8位)甚至真彩色(24位/像素)扫描。
然而,高分辨率的彩色图像会对系统的存储造成损失,并且会变得非常大,无法大量存储。智能数字图书馆对文本和非文本内容使用不同的压缩方案。用于双色调文本图像的典型压缩方法是CCITT Fax Group 3和Group 4[22,23,24],而实际图像最好使用JPEG技术进行压缩。下面我们介绍一些最流行的图像和文件格式及其对OCR的适用性。
TIFF代表标记图像文件格式(Tagged Image File Format)。它是当前为光栅数据交换而设计的最流行和最灵活的公共领域光栅文件格式之一。TIFF是由Aldus和微软公司联合开发的。Adobe Systems收购了Aldus,现在拥有TIFF规范的版权。由于它是由打印机、扫描仪和监视器的开发人员设计的,所以它有一个非常丰富的空间来进行色度校准和色域表。
理论上,TIFF可以支持多波段(最多64K波段)、任意位数的每像素、数据立方体和每个文件多个图像,包括缩略图子采样图像。支持的颜色空间包括灰度、伪彩色(任意大小)、RGB、YCbCr、CMYK和CIELab。TIFF支持以下压缩类型:raw uncompressed、PackBits、Lempel Ziv Welch(LZW)、CCITT Fax 3和4、JPEG;以及像素格式:1-64位整数、32或64位IEEE浮点。
TIFF的主要优势在于,它是一种高度灵活且独立于平台的格式,受到众多图像处理应用程序的支持。TIFF的一个主要局限性是缺少存储矢量图形和文本注释的任何规定,但这对OCR来说并不是很大的威胁,因为大多数识别引擎都使用光栅图像表示。
BMP或bitmap,是一种在Windows和OS/2操作系统下广泛使用的光栅图像格式。BMP文件以独立于设备的位图(DIB)格式存储,允许操作系统在任何类型的显示设备上显示位图。DIB以独立于显示器表示颜色的方法的形式指定像素颜色。
Windows 3.0及更高版本支持运行长度编码(RLE)格式,用于压缩每像素使用4或8位的位图。压缩减少了位图所需的磁盘和内存存储空间。显然,这种压缩是以牺牲颜色的多样性和深度为代价的,但是对于双色调或基于灰度的OCR系统来说,这并不存在问题。
位图文件特别适合存储真实世界的图像;复杂的图像可以与视频、扫描和摄影设备一起栅格化,并以位图格式存储。BMP是一种非常适合存储文档图像的直接图像格式,但它不像TIFF那样复杂和灵活。
PCX是PC上可用的最古老的光栅格式之一,最初由Z-soft为其基于PC的画笔软件建立。因为它已经存在了这么长时间,现在有许多版本的PCX。目前大多数软件都支持PCX格式的版本5。版本3只支持256种颜色,但不允许自定义调色板。这意味着当您打开一个版本3的PCX文件时,将使用标准的VGA调色板。PCX保留了所有的图像信息(类似于BMP),但是它不使用压缩,因此内存效率很低。
JPEG代表联合摄影专家组(Joint Photographic Experts Group),该委员会的原名是为有损图像压缩制定了这一标准,它牺牲了一些图像质量,以大大缩小文件大小。JPEG是为压缩自然场景和真实场景的全彩色或灰度图像而设计的。它在照片、自然艺术和类似材料上都很好地工作;在文字、简单卡通或线画方面不太好。JPEG压缩利用了这样一个事实:人眼感知到的小颜色变化比亮度的微小变化要精确。因此,JPEG是用来压缩人类将要看的图像的。但是,JPEG压缩引入的小错误可能会对机器视觉系统造成问题;而且由于JPEG在双色调图像上的性能不足,因此JPEG不是OCR中推荐的图像文件格式。
GIF代表图形交换格式(Graphic Interchange Format)。它在20世纪80年代被CompuServe信息服务作为一种在数据网络上传输图像的有效手段而普及。上世纪90年代初,GIF因其高效性和广泛的熟悉性而被万维网采用。今天网络上绝大多数的图片都是GIF格式的。GIF文件仅限于支持不超过256种颜色的8位调色板。GIF格式合并了一个压缩方案,以将文件大小保持在最小值。GIF对于文本和图表的图像比对真实世界的图像更有效。这使得GIF对于处理二级和灰度图像的OCR系统来说是一个很有吸引力的选择(通常比TIFF更直接)。然而,TIFF的CCITT传真压缩可以产生更紧凑的图像。
PNG代表便携式网络图形( Portable Network Graphics)。这种格式旨在逐步淘汰旧的和简单的GIF格式,并为更复杂的TIFF格式提供一种实用的替代方案。
对于Web而言,PNG确实比GIF有三大优势:alpha通道(可变透明度)、gamma校正(跨平台控制图像亮度)和二维隔行扫描(一种渐进式显示方法)。和GIF一样,PNG提供了无损压缩(不牺牲图像质量以减小文件大小),但在这方面做得更好。与GIF不同,PNG只支持每个文件一个图像。
与TIFF不同,PNG规范对支持的格式特性的实现非常严格,这意味着图像文件的可移植性比TIFF好得多。然而,对于文本或图纸的黑白图像,TIFF的第4组传真压缩或JBIG格式通常比1位灰度PNG好得多。
PDF代表可移植文档格式(Portable Document Format)。它是由Adobe公司开发的,目的是从文档发布应用程序中获取精确的模板信息,从而可以交换格式化的文档,并让它们显示在接收者的监视器或打印机上,就像它们在原始应用程序中看到的那样。
作为PostScript格式的一个紧凑版本,PDF是一种非常先进和精细的文件格式,它支持矢量和光栅图形,应用各种有损和无损压缩方案来减小文件大小。尽管这是一种专有的Adobe格式,但文件格式规范和查看器软件都是免费分发的。PDF图像大小适中,通常在300 dpi时每页大约50KB。这种格式的典型应用包括经济高效的文档归档(不需要文本搜索)和按需打印/传真。为了处理文本的PDF图像,OCR软件需要一个复杂的PDF阅读器,可以通过免费提供的格式规范购买或构建。
在一个OCR系统中,这种丰富多样的图像格式可能难以支持,并且图像格式转换器常常必须使用。此类转换器可用于:
- 独立(有时是开源)实用程序(例如bmp2tiff)
- 图形库的一部分(例如ImageMagick)
- 部分商业图像处理软件(如Adobe Photo Shop)
虽然OCR技术主要涉及扫描的纸质文档,但目前OCR技术在其他媒体(如数字照片、视频和万维网)中的适用性正在不断扩大。这里的主要任务仍然相同:在图像中查找文本;但是图像格式不必固定为黑白。在这一具有挑战性的领域中,研究人员追求的最终目标是建立一个OCR系统,能够识别以任何格式编码的任何静止或动态图像中的任何文本。
在下面的两个小节中,我们将讨论传统的OCR(扫描文档)和非传统的(其他媒体)图像格式。
2.4.1扫描文件
由于文档图像格式的多样性,大多数商用现成(COTS)OCR解决方案可以使用不止一种图像文件格式,并且可以适应各种空间分辨率和像素深度。许多COTS-OCR软件包都提供了一套丰富的图像处理实用程序,可以分析输入图像并将其转换为最适合给定OCR引擎的格式。让我们谈谈一些流行的商业OCR解决方案以及它们支持的图像格式。
ScanSoft Capture Development System 12提供多种图像和应用程序格式支持,包括BMP、GIF、TIF、PDF、HTML、Microsoft Office格式、XML和开放式电子书。
ABBYY Fine Reader 7.0可以处理各种格式的黑白、灰度和彩色图像,包括BMP、PCX、DCX、JPEG、JPEG 2000、PNG、PDF和TIFF(包括多图像,采用以下压缩方法:Unpacked、CCITT Group 3、CCITT Group 4传真(2D)、CCITT Group4、PackBits、JPEG、ZIP)
Sakhr Automatic Reader 7.0提供了在各种格式(包括TIFF、PCX、BMP、WPG和DCX)中读写图像所需的功能。
大多数消费者级OCR程序都使用双级图像,通常希望在白色背景上显示黑色文本。有些可以导入灰度图像并在内部将其转换为黑白图像,有时使用自适应阈值。只有很少的OCR引擎可以直接处理灰度或彩色图像,利用多位像素信息。
2.4.2 其他媒体
许多多媒体源提供的图像和视频包含可自动检测、分割和识别的可见文本。这种能力对于创建先进的多媒体信息检索系统是非常理想的。从多媒体内容中获取的文本将是索引和检索的高级语义信息的宝贵来源。
在这个方向上最有趣的研究是由Lienhart等人进行的。[52,53,54]。他们提出了一种有趣的方法来定位和分割复杂图像和视频中的文本。文本行的识别是通过使用一个复杂值的多层前馈网络来识别文本的,该网络被训练成在固定的尺度和位置检测文本。网络在所有尺度和位置的输出被集成到一个文本显著性图中,作为候选文本行的起点。在视频的情况下,这些候选文本行是通过利用视频中文本的时间冗余来细化的。然后将本地化文本行缩放到100像素的固定高度,并将其分割成白底黑字的二值图像。对于视频,利用时间冗余来提高分割性能。由于采用了真正的多分辨率方法,输入图像和视频可以是任何大小。该方法为图像和视频中的文本定位和文本分割提供了一种通用的、尺度不变的解决方案。在视频帧和网页的真实测试集上,69.5%的文本框被正确定位。利用视频中的时间冗余,性能提高到94.7%。测试视频集中79.6%的字符能够正确分割,88%的字符被正确识别。
2.5 脚本和语言问题
我们把脚本定义为用特定语言书写的方式。多语言共享相同或相似的脚本并不少见,例如。
- 大多数西欧语言都有拉丁语的变体
- 一些东欧语言共享西里尔字母的变体
- 许多伊斯兰文化语言都有阿拉伯语的变体
因此,为一个脚本开发了一个系统后,就可以很容易地将其应用于整个语言家族。直到20世纪90年代初,光学字符识别技术(极少数例外)都与拉丁文字有关。这就产生了各种各样的基于拉丁语的OCR系统。随着信息技术在全球范围内的扩展,对拉丁语以外的其他文字的识别已经成为一个世界性的兴趣。
2.5.1 复杂文字(复杂字符脚本)
正如我们前面提到的,拉丁语类脚本的OCR研究得相当好,并且有许多成功的实现,而大多数亚洲脚本与拉丁语脚本非常不同,因此对OCR社区提出了不同的挑战。

例如,让我们考虑一下日语脚本。除了日文汉字(汉字和汉字)外,还使用日文汉字和汉字。因此,可以想象,由于
- 字符集的大小(超过3300个字符),
- 单个字符的复杂性(图2),以及
- 汉字结构之间的相似性(图3)。
低数据质量是所有OCR系统中的另一个问题。一个典型的日本OCR系统通常是由两个独立的分类器(前分类器和次分类器)组成的级联结构。预分类器首先执行快速粗分类,将字符集缩减为一个短候选列表(通常包含不超过100个候选字符)。然后,二级分类器使用更复杂的特征来确定列表中哪个候选者与测试模式最匹配。
阿拉伯语字符识别也有它的挑战。首先,阿拉伯文本是用相互连接的字符块草草书写、打字和打印的。一个词可以由几个字符块组成。阿拉伯字符除了其独立形式外,还可以根据其在字符块中的位置而采用不同的形状(如图4中所示的首字母、中间字母或词尾)。

阿拉伯字符也可以一个一个地堆叠在另一个上面,这可能导致字符块有多个基线。此外,阿拉伯语还使用许多外部对象,如点、Hamza和Madda。图5所示的可选的外部对象也可以添加。

最后,阿拉伯语字体供应商没有遵循一个共同的标准。鉴于阿拉伯字体的特殊性和阿拉伯语的特点,建立一个全字体的阿拉伯语OCR成为一项艰巨的任务。
2.5.2 处理各种脚本的技术
Steinherz等人。[85]回顾离线草书字识别领域。他们将该领域分为三类:
- 无切分方法:将从单词图像中获得的一系列观察结果与词汇表中的相似引用进行比较,
- 基于切分的方法:寻找原语片段的连续序列与可能单词的字母之间的最佳匹配,
- 感知导向的方法:执行一种类似人类的阅读技巧,在这个技巧中,在整个单词中找到的锚定特征被用来引导一些候选者进入最后的评估阶段。
在他们看来,该领域还不够成熟,无法对上述方法进行比较。在他们看来,小词库和静态词库的情况下,单词识别问题基本上得到了解决,但对于有限的和大的词库,情况并非如此。他们想指出,目前的系统可能已经接近于独立单词识别的极限,应该努力改进利用语法、上下文和其他外部参数的后处理技术。
Khorsheed等人。[42,43,44]回顾阿拉伯语字符识别的各种技术,重点介绍从阿拉伯草书中提取结构特征的基于单词的技术。他们的方法是对文字图像进行骨架化,并将其分解成若干段,形成一个特征向量,再利用这些特征向量训练隐马尔可夫模型进行识别。这种方法高度依赖于作为查找字典的预定义词典。通过从各种脚本源获得的294个单词词典中训练出的实验单词模型,他们的系统被宣称达到了97%的识别率。
Lu等人。[56]提出了一个独立于语言的OCR系统,他们声称能够识别来自世界上大多数语言的印刷文本。该系统使用隐马尔可夫模型(HMM)进行字符识别,但不需要对源数据进行字符或单词的预分割。使用现有的连续语音识别系统进行训练和识别。该系统使用无监督自适应技术来提高其对传真等引起的图像退化的鲁棒性。为了证明该系统的语言独立性,作者对三种语言进行了实验:阿拉伯语、英语和汉语。中文OCR系统可识别3870个字符,其中简体中文字符3755个。阿拉伯语和英语系统提供高质量的无限词汇全向字体识别。作者还证明使用词典可以显著提高OCR系统的字符错误率。
2.6 语言混合的效果
近年来,人们对多语种、多脚本的OCR技术越来越感兴趣。多语种OCR系统的设计很自然,可以读取同一文档中的多个脚本,对于欧洲和亚洲许多国家的文档交换和业务处理尤其重要,因为在这些国家,文档通常以多种语言打印。
在处理包含多种语言的文档页面时,使用最少的文本数据可靠地标识脚本的能力是至关重要的。脚本识别任务有几个挑战,例如。
- 意外的脚本或语言总是有可能出现,这在选择OCR引擎时会出现问题
- 不允许字符识别,因为脚本分析在实际文本识别之前进行
- 手写体识别的处理时间应该是OCR处理总时间的一小部分
Hochberg等人。[30,31]描述了一个在分析多语言文档图像时使用基于聚类的模板的自动脚本识别系统。为文档中每个连接的组件计算脚本标识向量。该向量表示组件和为13个脚本(阿拉伯语、亚美尼亚语、缅甸语、汉语、西里尔文、德瓦纳-加里语、埃塞俄比亚文、希腊语、希伯来语、日语、韩语、罗马语)开发的模板之间的最近距离,作者计算了每幅图像在13维空间内的前三个主要成分。通过将这些组件映射到红色、绿色和蓝色,它们将脚本标识向量中包含的信息可视化。多语言图像的可视化表明,脚本识别向量可以用于将图像分割成大到几个段落或小到几个字符的脚本特定区域。可视化的向量还揭示了脚本内部的区别,比如罗马文档中的字体,日语中的汉字与假名。他们的实验是在200 dpi扫描的有限数量的多脚本文档上进行的。结果似乎对包含高度不同的脚本(如罗马和日语)的文档最好。包含类似文字(如罗马和西里尔文)的文件上的手写体标识将需要进一步调查。
当前的脚本识别方法通常依赖于手工选择的特征,并且通常需要处理文档的重要部分以实现可靠的标识。Ablavsky和Stevens[1]提出了一种基于形状的方法,该方法将大量的图像特征应用于一个小的训练样本,并使用子集特征选择技术自动选择具有最大识别能力的子集。在运行时,他们使用一个分类器和一个证据积累引擎,一旦达到预设的可能性阈值,就会报告一个脚本标签。算法验证在英语和俄语文档图像语料库上进行,共1624行文本。来源是新闻纸和300 dpi扫描的书籍。降级文件是第一代影印件的第一代影印件传真件(表1)。错误产生的主要原因是分区不完善、多栏文本中行提取不准确以及字符合并。脚本分类降级但适当分割字符声称是准确的。
Pal等人。[68]给出一个自动识别不同印度文字行的方案。他们的方法根据脚本特征将脚本分成几个类。它使用各种脚本特征(例如,水库原理、轮廓跟踪和字符轮廓)来识别脚本,而不需要任何昂贵的OCR类算法。该方法应用于250幅包含约4000行文本的多脚本文档图像。扫描的图像来自青少年文学、报纸、杂志、书籍、汇款单、计算机打印件、翻译书籍等。作者报告他们的系统总体准确率约为97.52%。
2.7 字符类型
随着OCR领域的不断进步,开发一个能够对使用复杂字符脚本或各种字体和字体的文档保持较高识别率的识别系统仍然是一个挑战。我们可以确定两种处理多字体文档的主要方法:
字体抽象。在使用拉丁语的多字体文档中,可以在OCR系统已知的有限字体范围内获得高精度。为了克服识别各种字体文档的困难,Kahan等人。[37]介绍了一个OCR系统,该系统利用字体的抽象来概括各种字体的个体差异。这种方法被称为全向字体光学字符识别,它已经有很多或成功的实现。
字体标识。与字体抽象相反–Jung等人。[36]argue–字体识别可以提供有关字符结构和排版设计的详细信息。此外,利用字体信息,可以使OCR系统以有限的努力来处理文档以识别字体。换句话说,由各种单色字体分割工具和识别器组成的OCR系统可以执行特定于字体的识别。他们的方法使用从单词图像中获取的排版属性,如升序、下降和衬线。将属性作为神经网络分类器的输入,产生多字体分类结果。他们声称这种方法可以将7种常用字体按7到18的大小进行分类。他们的实验表明,即使是接触严重的字符,字体分类的准确率也能达到95%左右。
即使是在一个单一的字体中,字符打印也会出现变化(扭曲),给OCR系统带来困难。这种变化包括使用(有时滥用)黑体、斜体、下划线或小号大写字符样式(字体)。一些OCR系统试图通过图像预处理来弥补字体的差异,而另一些系统则简单地将它们视为不同的字体。
2.8 手写字体识别
手写文本的识别或智能字符识别(ICR)是一项比识别打字文本或机器打印文本困难得多的任务。正如Edelman等人。[21]指出,造成困难的两个主要原因是:
- 字符分割歧义
- 字符形状变化
图6是从Pechwitz等人描述的语料库中提取的阿拉伯笔迹示例。在[71]中。手写文本通常是草书的,这意味着单词图像的很大一部分可能由连接连续字符的连字组成。这些连字通常被解释为字母的一部分,产生了多个同样合理的分段。此外,即使是由同一个人书写,相同的字符不仅可能改变几何结构(例如,在某些情况下稍微倾斜,在另一些情况下是笔直的),而且拓扑结构也会发生变化(例如,数字“2”在底部有或没有环)。因此,识别方法往往是调整到一个特定的手写体风格,必须重新训练,甚至重新编程时,不同的风格提出。

一个完整的ICR系统的核心是它的识别单元。根据Steinherz等人。[85],分类识别算法的一种方法是根据所涉及词典的大小和性质,以及是否存在分割阶段。词汇可能是
- 小而具体,大约有100个单词,
- 有限的,但动态的,最多可达1000个单词,并且
- 大的或无限的。
基于切分的方法将从一个单词图像中派生出的一系列原始片段与一组可能的单词组合在一起,并尝试将各个片段连接起来以最佳地匹配候选字符。在没有分割的情况下,没有尝试将图像分割成与字符相关的片段,尽管仍然可以将图像分割成更小的片段,然后生成一系列观察结果。在这两种情况下,算法都试图通过以从左到右(或从右到左)的方式识别单词的组成部分来重现单词的书写方式。
另外,还有一类面向感知的方法,通过利用一些稳定的特征可靠地在图像中的任何地方找到字符,并使用它们引导几个单词候选,以进行最终评估阶段,从而执行类人阅读。虽然这类方法没有其他两类方法开发得那么多,但是存在一些面向感知的方法,它们看起来很有前途。
到目前为止,大多数的注意力似乎都集中在小而有限的词汇方法上,尤其是那些应用于拉丁语的方法。文献中提出了许多不同的方法和一些完整的识别系统。然而,总体而言,手写文本识别领域尚未成熟[85]。
评论风格的文章相对较少[74,42],尝试实验性比较不同方法的尝试更少。其中一个原因是缺乏足够大、通用且可公开使用的测试数据集。
此外,一个完整的ICR系统的性能取决于其识别引擎之外的许多其他组件,例如预处理、分割和后处理模块。据我们所知,几乎没有人试图建立一个共同的框架,以便对不同的引擎或完整的识别系统进行客观的比较。我们发现的唯一例外是HRE-API,它代表手写识别引擎应用程序接口。该API于1994年左右由sunmicrosystems发布到互联网上,希望它能加快商业质量手写识别引擎和应用程序的可用性,并有助于促进大学对新手写识别技术的研究。作为一个可完全扩展的开放源码手写识别框架,HRE-API旨在:
- 为手写识别引擎提供功能完整的接口,
- 同时支持多个手写识别引擎,
- 最小化对特定图形用户界面(GUI)的依赖性,以及
- 全面的多语言支持。
最成功的手写字符和单词识别方法是基于隐马尔可夫模型(HMM)的应用。这种方法将印刷体和草书书写的变化作为一种潜在的概率结构,无法直接观察到[14]。当涉及到小词典时,对单个字符进行建模的基本hmm被组合成单个较大的模型-词典中每个单词的判别hmm。当一个单词图像被呈现给这样一个系统进行识别时,它会选择一个单词解释,其模型给出的概率最大,因为给定的是由给定图像生成的一系列观察值或符号。对于较大的词库,只需从字符子HMM中建立一个路径判别HMM,并通过给定单词图像的观察序列从模型中找到最可能的路径来进行识别。路径判别模型比模型判别模型更通用,但精度较低。
基于HMM的方法之所以流行,是因为它们在类似的语音识别问题上表现得相当好,而且它们的数学机制也得到了很好的发展和完善。同时,它们仍然是一个活跃的研究领域。一个原因是隐马尔可夫模型的性能在很大程度上取决于用于生成观察序列的特征类型,这些特征既用于模型的训练,也用于识别。正如[85]所指出的,“理想”特征集还没有找到,而且可能根本不存在。此外,虽然大多数基于HMM的方法将单词图像表示为一维的观察向量序列,但最近的一种方法是将其推广到二维Markov模型(也称为Markov随机场)[69]。虽然这种方法似乎能提供更好的准确性,但它的计算成本也要高得多,因此需要比传统的基于HMM的方法更复杂的设计和实现。
2.9 灵活性
早期的光学字符识别系统相当不灵活。它们通常只使用单一字体或严格限制的一组字体(如图8或9中的OCR-a或OCR-B),需要固定的文档布局,功能扩展选项非常有限,对输入文档中出现的任何噪音的容忍度都很低。
目前,一个好的光学字符识别系统要求对用户的数据和任务具有灵活性。我们确定了OCR系统灵活性的三个共同领域:
- 任务可调整的配置参数,如识别质量和速度、预期的脚本和字体参数以及无法识别的字符标记
- 为特定文档集优化识别引擎的可训练性
- 软件开发工具包(SDK),用于扩展OCR引擎的功能和/或使其成为更复杂的文档识别系统的一部分
让我们考虑一下第2.2节中提到的现有OCR解决方案的几个示例。我们将描述每个解决方案在上述方面的灵活性。
ScanSoft Capture Development System 12是一个灵活的OCR SDK,提供可调节的吞吐量/精度OCR(机器打印)和ICR(手写打印)引擎,支持字符训练,以提高精度。
ABBYY FineReader 6.0引擎是另一个灵活的SDK,用于将ABBYY OCR和ICR识别技术集成到Windows应用程序中。为了提高表单和非标准文档的识别精度,该引擎提供了一个API,用于创建和编辑特殊识别语言,将用户语言创建为预定义识别语言的副本,并向用户语言添加新词。FineReader引擎允许开发人员创建和使用用户模式,或者从ABBYY FineReader桌面应用程序导入它们。
Sakhr Automatic Reader 7.0 OCR引擎主要用于阿拉伯语机器打印识别,但通过Xerox文本桥技术支持多语言OCR。它有一套丰富的可配置选项,可以区分26种阿拉伯真字体。这个可训练的OCR引擎提供了一个OCR SDK,包括DLL和ActiveX格式。
我们应该提及其他OCR系统灵活性功能,这些功能很少提供,但通常非常理想:
- 源代码可用性
- 跨计算平台的可移植性
- 灰度和彩色图像支持
你可能会在2.2节提到的开源OCR系统中发现这些特性。
2.10 准确率
基于计算机的光学字符识别(OCR)系统自20世纪50年代初问世以来已经取得了长足的进步,尽管其生产率、鲁棒性和准确性都有了很大的提高,但是OCR系统还远远不够完善,尤其是在准确率方面。
给定一个纸质文档,人们可以扫描它生成一个可以由OCR程序处理的数字图像,其输出是以机器可读形式呈现的文档文本,例如文本文件。为了估计OCR的准确性,OCR输出可以与原始文档的文本进行比较,称为基本真实。由于有多种方法可以将OCR输出与实际情况进行比较,因此我们有多种方法来定义OCR的精度。
当原始文档的文本以电子格式提供时,计算机可以通过将文档的源文件与OCR输出文件进行比较来评估OCR的准确性。精度表达式通常考虑
- correct,
- inserted,
- deleted, and
- substituted
当原始文档的文本以电子格式提供时,计算机可以通过将文档的源文件与OCR输出文件进行比较来评估OCR的准确性。准确度表达式通常考虑OCR输出中相对于源文本的项目数(例如单词或字符)。参考第2.10.1节了解基于地面真相的精度估计的详细信息。
当文档的源文本不可用时,流利的母语使用者可以将正确的文本输入到文件中,以提供基本的真实性。另一种选择是,一种方法是让一个以母语为母语的人看一看并在视觉上比较源文档和相应的OCR输出。这个过程可能像识别OCR输出中拼写错误和丢失的单词一样随意,也可能遵循严格的路径来计算正式的OCR准确度分数。在第2.10.2节中,我们给出了不含文件源文本的近似精度评估的详细信息。
2.10.1 When ground truth is present
OCR的两个最常见的准确性度量是精确度和召回率。两者都是OCR准确度的相对度量,因为它们是以正确输出与总输出(精度)或输入(召回)的比率来计算的。更正式的定义

其中,条目指的是字符或单词,而基本事实是存储为例如纯文本文件的原始文本。在计算准确度和召回率时,基本事实用于
- 确定正确识别的项目数量
- 提供地面真实项目的总数。
精确性和召回率都是数学上方便的度量,因为它们的数值是0.0到1.0之间的一些小数,因此可以用百分比来表示。例如,recall是OCR引擎正确找到的原始文本中单词的百分比,而precision是正确找到的单词占OCR输出总字数的百分比。请注意,在OCR相关文献中,术语OCR准确度通常指的是召回率。
考虑一个简单的例子。假设我们收到的传真只有一页,其中大部分是文本。我们运行我们最喜欢的OCR程序将其转换为纯文本文件输出.txt, 我们的OCR输出。然后我们收到原始文本文件输入.txt(我们的基本事实)通过电子邮件。有了这两份文件,我们发现输入.txt544个单词中有3371个字符,而输出.txt542中包含3374个字符文字。评价显示出输出.txt有3350个正确匹配的字符和529个正确匹配的字符文字。那个然后计算精度和召回值,如表2所示。
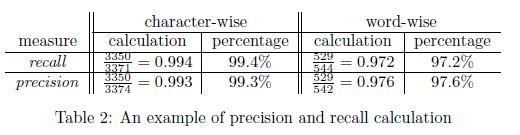
虽然准确度和召回率是良好的OCR性能指标,但它们仍然是两个高度相关但又相互独立的量。OCR软件用户通常需要一个单一的精度度量,用字符或单词的错误率来表示。
使用错误度量来度量系统性能的原因是,错误度量代表了让系统犯这些错误的用户的成本。例如,将错误率降低两倍,说明用户的成本也减少了一半,因为如果用户要纠正这些错误,只需投入一半的精力。然后,可以通过测量错误率的相对降低来跟踪系统性能的改进。
Makhoul等人。[59]从项目插入、删除和替换错误的角度提出了精确度和召回率,并分析了几种OCR错误率估计方法。
经典有效性度量[79,p.174]由

其中P为精度,R为召回率,Makhoul表明M低估了插入和删除错误相对于替换错误的作用,因此OCR的性能比实际要好。为了避免这个问题,Makhoul提出了项目错误率公式:

由于给定测试文档的分母是固定的,这种错误率估计为比较不同OCR系统的性能提供了一种很好的方法。注意,项目错误率类似于在语音识别系统中用作主要性能指标的单词错误率,但它也不是完美的:它的数值范围没有限制在0.0到1.0之间,主要是因为它没有考虑OCR输出大小。
MacKenzie和Soukoreff[58]提出了一个更公平的项目错误率估计:

这个误差率表达式对于插入、删除和替换是无偏的,其数值范围限制在0.0到1.0之间,它同时考虑了基本真实尺寸和OCR输出尺寸。唯一明显的缺点是,对于给定的输入文档,错误表达式中的分母在不同的OCR系统中不是固定的,这一事实使得公平比较它们的性能变得复杂。
Nartker等人。[65]试图将OCR准确性的概念细化为应用于信息检索(IR)任务。他们定义:
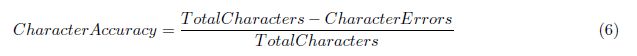
其中TotalCharacters是基本真实中的字符数,CharacterErrors是字符插入、删除和替换的总数。注意,这样定义的字符精度可以是负数,这可能会混淆精度的解释,但是如果我们写characteraccuracity=1-E,则与等式(4)一致。
Nartker还指出,IR系统忽略了常见的单词,称为stopword(如“the”、“or”、“and”)。它们也会忽略标点符号、大多数数字和所有杂散标记。因此,拼写错误的停止字和不正确的数字不是影响检索性能的错误。就从红外系统检索文档的可检索性而言,非停止字精度是衡量转换精度的较好方法。非停止字精度定义如下:
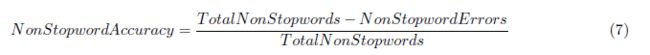
这里再次将TotalNonStopwords计算在基本的真实值中,而non-stopword错误只解释了发生在non-stopwords中的错误。注意,如等式(6)所示,此处的精度估计值可能为负值。
2.10.2 When ground truth is absent
在许多实际情况下,当源文本不可用,因此不存在基本事实来自动验证OCR输出。在这些情况下,我们求助于一个流利的母语者来评估OCR引擎的性能,认为人类的感知系统是最终的光学字符识别系统。不用说,所有这些绩效评估都是近似的和有偏见的。下面我们提供了一些指导方针,说明当我们没有一组文本文件来比较OCR输出时应该怎么做。
- 让流利的语言使用者检查源页面图像和OCR输出。
- 让说话者在OCR输出中识别错误、遗漏和多余的单词。
- 用第2.10.1节中的公式估计页面上的字数。
- 对选定的各种页面重复步骤1-3。
例如,如果页面有大约300个单词,并且说话人发现一段大约20个单词的段落缺失,3个单词不正确,并且没有多余的单词,那么页面的单词级准确率约为99%,页面的单词级召回率约为92%。
上述OCR评估方法应适用于具有各种噪声(如复印或传真)的文档图像,以及一些干净的图像。这样,人们就可以了解在不同的情况下出现了什么样的OCR精度数字。
当大量OCR数据需要验证时,如果您认为配备了替代OCR系统的计算机,则验证过程可以自动进行,并且上述方法也适用于此处。当有几个OCR引擎可用时,可以匹配其输出,从而检测可能的错误,并根据统计信息和字典提出可能的更正[45]。
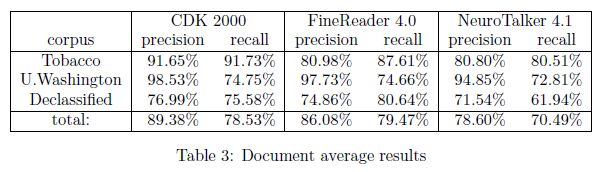
2.10.3 商用OCR引擎精度
Summers[87]比较了三种领先的商业OCR软件包在不同质量的文档图像上的性能。包括OCR软件包
- ScanSoft的Caere Developers Kit 2000版本8,
- Abbyy的FineReader 4.0,以及
- 国际神经机器公司的NeuroTaker4.1。
每个系统的精确性和召回率都是在英国语料库上进行的,该语料库包括1147张华盛顿大学语料库的期刊页面图像、946张解密政府文件的页面图像和540页烟草诉讼文件的图像。在其他统计数据中,计算文档的精确度和召回率的平均值。如表3所示,Caere Developers Kit(CDK)2000和FineReader 4.0的表现一直优于NeuroTalker,总体而言,CDK 2000比FineReader 4.0更精确。然而,就解密的政府文件而言,FineReader4.0的召回率略高于CDK 2000。
Kanungo等人。[38]提出一种称为配对模型的统计技术来比较两种识别系统的准确度得分:Sakhr自动阅读器3.0和Shonut OmniPage 2.0。他们表明,与未配对的方法相比,成对模型的性能比较方法产生了更紧的置信区间。该方法在DARPA/SAIC数据集上进行了测试,该数据集包含342个原始分辨率为600 dpi的阿拉伯文文档,人为地分为400、300、200和100 dpi。他们的实验表明,在300 dpi的SAIC数据集上,Sakhr比OmniPage有更高的精确度,但OmniPage的精确度更好。他们已经注意到,当图像分辨率超过300 dpi时,Sakhr的精确度会下降。此外,他们还发现,当图像分辨率从400 dpi增加到600 dpi时,Sakhr到OCR页面所需的平均时间不会增加。在他们看来,这可能表明Sakhr在识别阶段之前,在内部将输入图像转换为某种标准分辨率。
2.11 Productivity
除了识别精度外,生产率(或吞吐量)是OCR系统的另一个重要特性。吞吐量是以每一时间间隔处理的项目数来衡量的,例如每秒的页数或每分钟的字数。一般来说,OCR系统的吞吐量受许多因素的影响,这些因素包括:
- 系统采用的字符分类器
- 文档复杂性取决于每一页上字体、文本列、非文本项(图片、绘图、绘图)的数量
- 由于原稿质量差或扫描不完善而产生的图像噪声
- OCR校正和可靠的文档索引通常需要后处理
- 涉及输入图像预处理和输出文本格式的接口问题
- 手写识别选项
毫不奇怪,任务特定的OCR系统通常比通用的OCR系统更精确、更高效,但后者有望处理更多种类的文档。下面,我们给出了这两种OCR系统的一些例子,并指出了它们的典型平均吞吐量。
2.11.1 通用阅读器
由于通用OCR系统设计用于处理范围广泛的文档,因此在识别精度和平均吞吐量方面会有所牺牲。一些高端OCR软件包允许用户根据客户数据调整识别引擎,以提高识别精度。它们还可以检测字体(如粗体和斜体)并以相应的样式输出格式化文本。这种多功能性往往以牺牲系统的生产力为代价。
PrimeRecognition(http://primerecognition.com网站/)声称在700MHz的奔腾PC上,OCR引擎的吞吐量是420个字符/秒。OCR的平均准确率为98%。
LeadTools(http://www.leadtools.com/)智能字符识别(ICR)引擎在运行Windows2000的1500MHz奔腾PC机上有256MB的RAM,据称可以达到280-310个字符/秒的手写数字识别速度,以及150-220个字符/秒的手写大小写文本、数字和符号(混合)。
Sakhr(http://www.sakhr.com/)生产主要用于阿拉伯语OCR的自动阅读器。阿拉米达(http://aramedia.net/armedia/ocr.htm)声称运行在Pentium III Windows 2000下的自动阅读器7.0每秒可处理800个字符,对阿拉伯语书籍和报纸的识别准确率为99%。
2.11.2 任务特定读卡器
如前所述,任务特定的读取器主要用于面向类似结构文档并需要高系统吞吐量的大容量应用程序。为了帮助提高吞吐量,这些系统将重点放在文档感兴趣的字段上,这些字段是期望获得所需信息的地方。这种窄聚焦方法可以大大减少图像处理和文本识别的时间。使用特定任务阅读器的一些应用领域包括:
- 邮政编码识别和地址验证
- 基于表格的文本识别,例如在税务表格中
- 纸面水电费票据自动核算程序
- 银行支票处理
- 航空客票核算
- 签名验证
更具体地说,让我们考虑一些任务特定的OCR系统的例子。
(Address readers)地址读取器帮助自动排序邮件。典型的地址读取器首先在邮件上找到目标地址块,然后读取该地址块中的邮政编码。如果地址块中的其他字段以高置信度读取,则系统可能会生成一个9位数的邮政编码。生成的邮政编码用于生成随后打印在信封上的条形码,用于邮件自动分拣。地址读取器的一个很好的例子是美国邮政局(USPS)使用的多行光学字符读取器(MLOCR)。它可以识别多达400种字体,系统每小时可处理45000封邮件。
(Form readers)表单阅读器通过读取纸质表单中的数据来帮助自动化数据输入。典型的表格阅读系统应该能够区分预打印的表格说明和填写的数据。这样的系统首先用一张空白表格训练,以便在表格上登记数据应该出现的区域。在识别阶段,系统需要定位并扫描应该填充数据的区域。一些读者阅读手写数据以及各种机器书写的文本。通常,表单阅读器可以以每小时5800个表单的速度处理表单。
如今,几家航空公司在乘客收入核算系统中使用机票阅读器(Airline ticket readers )来准确核算乘客收入。为了从客票中获得收入,航空公司需要有三个匹配的记录:预订记录、旅行社记录和客票。OCR辅助系统读取客票上的机票号码,并将其与航空公司预订数据库中的号码进行匹配。这种系统的典型吞吐量是每天26万张票,分拣率为每秒17张。
3 OCR预处理
现代OCR引擎被期望处理各种各样的文档图像,这些图像在图像质量、噪声级和页面布局方面可能有很大的变化。因此,一些文档图像过滤和页面结构分析成为实际识别阶段的重要前提。本节介绍了各种文档图像缺陷,揭示了它们的潜在原因,并讨论了增强OCR文档图像的一些技术方法。在这里,我们还讨论了一些与预OCR自动页面和文档分割有关的有趣问题。
3.1 文档图像缺陷
通常情况下,真实的文档图像是不完美的。各种文档图像缺陷,如
- 白色或黑色斑点,
- 破损或触动的字符,
- 浓淡印花,
- 迷路的痕迹,
- 曲线基线
在文件打印/扫描期间发生,有许多物理原因,包括
- 脏原稿,如咖啡污渍
- 纸张表面缺陷
- 墨水或墨粉的扩散和剥落
- 光学和机械变形与振动
- 低印刷对比度
- 非均匀照明
- 散焦
- 有限空间采样分辨率
- 像素传感器灵敏度和位置的变化
- 电子元件噪声
- 二值化或固定自适应阈值
- 复制生成上一次扫描和复制产生的噪声累积
即使输入的文档图像有轻微的退化,文档识别系统的准确性也会急剧下降。为了克服这些困难,研究人员继续研究图像缺陷模型,以帮助控制图像质量变化的影响,并构造满足给定精度目标的分类器。这类模型通常用于合成用于OCR训练的大型真实数据集。
Baird[5]讨论了文档图像缺陷的模型。他区分了两种通用的方法来指定这些模型:解释性和描述性。解释模型是建立在物理学基础上的,可以通过引用物理定律部分地加以验证。这可能导致精确的模型,但它们可能是不必要的具体和复杂的。描述性模型更具经验性,主要通过统计方法进行验证,例如产生真实缺陷图像的重复的概率。一般来说,研究人员同意描述性模型更实用。
Sarkar等人。[80]使用十参数图像退化模型来近似机器打印和文本成像的某些已知物理特性,包括符号大小、空间采样率和误差、仿射空间变形、斑点噪声、模糊和阈值化。结果表明,即使在训练数据和测试数据中图像严重退化的情况下,文档图像解码(DID)监督的训练算法也能以较低的人工工作量获得高精度。作者描述了在DID训练中对字符模板、集合宽度和信道(噪声)模型的改进。他们对文本的综合退化图像进行了大规模的实验,结果表明,即使在相同分布的严重退化图像上,该方法也能达到99%的召回率。这种在低质量图像上进行可靠训练的能力,这些图像受到大量字符碎片和合并的影响,而不需要手动分割和标记字符图像,这大大减少了DID训练的人工工作量。
图像扭曲是一个常见的问题,当扫描或影印一个文件页从一个厚的装订卷,导致阴影和弯曲的文本线装订卷。这不仅降低了可读性,还降低了OCR的准确性。为了解决这一问题,张和谭[91]提出了一种基于连通分量分析和回归的页面图像去扭曲技术。该系统被称为计算效率和分辨率无关。他们报告说,300幅文档图像的总体平均精确度和召回率分别提高了13.6%和14.4%。
3.2 文档图像增强
OCR性能对扫描文档图像的任何基于文本的处理的有用性设置了一个上限。文档图像质量反过来又会极大地影响OCR引擎的准确性和生产率。在处理大量边缘质量文档图像时,OCR文档图像的自动增强和恢复是一个难题。
Loce和Dougherty[55]通过非线性图像滤波算法及其背后的统计优化技术,对数字文档增强和恢复问题进行了有趣的处理。特别是,这本书描述了优化方法的平行减薄,加厚,和差分过滤器。这些滤波器的统计最优性被描述为相对于文档的理想形式,最小化被处理文档的平均绝对误差。作者描述了如何在退化文档图像的恢复方法中使用增加滤波器,这些图像具有明显的背景噪声、过厚的笔划和参差不齐的边缘。这本书还讨论了一些广泛使用的空间分辨率和量化范围增强技术。
让我们来讨论一下OCR相关图像增强的一些值得注意的论文。Cannon等人。[12] 介绍了QUARC,一个用于增强和恢复打印文档图像的系统。他们设计了一套质量评估措施和图像恢复技术,以自动增强用于OCR处理的打印文档图像。他们采用了五种质量标准:
- 小散斑因子
- 白斑因子
- 粘连字符因素
- 断字因子
- 字体大小因子
利用质量指标对给定的文档图像进行优化恢复。这些恢复方法基于以下双调滤波器:
- 什么都不做
- 在打字机网格上剪切
- 填补漏洞和缺口
- 去斑
- 整体形态闭合
- 全局填充孔和裂缝
- 全局去杂点
- K过滤器
该方法通过质量度量对输入文档图像进行特征化,其值由预先训练的线性分类器确定最佳图像恢复滤波器。将分类器训练到一组“典型”图像上,这些图像的“最佳”恢复方法取决于给定的OCR引擎的性能。QUARC声称其字符错误率提高了38%,单词错误率提高了24%。系统中输入的字体和地址没有固定,文档的字体和地址都没有固定。
萨默斯等人。在文档图像增强软件imagerefiner中采用了类似的方法[88]。他们改进了QUARC,通过使用非固定字体(例如TrueType)和非拉丁(例如西里尔文)脚本来处理文档。QUARC质量度量集通过添加连接组件的以下度量进行扩展:尺寸、高度、宽度、面积和纵横比。同时采用了一套没有假定打字机网格的恢复方法。与QUARC相似,他们的系统基于文档图像质量度量确定了一种最佳的恢复方法,但是他们的分类器使用错误传播神经网络来学习特征空间(质量度量)和文档类(恢复方法)之间的最佳分类映射。imagefiniter在处理各种字体和脚本的嘈杂文档图像时非常健壮。实验证明,该方法能够正确提取76.6%的转换。目前,他们正在开发imagefiniter的第二阶段,该阶段预计将使用自适应文档分区并处理非拉丁语(例如亚洲)脚本。
3.3 文档分割
为了确保最佳的字符识别、可搜索性和最小失真,在将文档转换为电子形式时,通常需要保留文档的逻辑结构和格式。理想情况下,人们希望文档识别系统以“扫描的就是得到的”的方式工作。这刺激了一个通常被称为文档图像理解的领域的研究。它包括
- 将文档分解为其结构和逻辑单元(文本块、图形、表格等),
- 标记这些单位,
- 确定他们的阅读顺序
从而最终恢复文档的结构。此外,还必须进行格式分析,包括字体类型和间距的分析。本节介绍了自动文档页面分割、恢复阅读顺序和查找文本行的方法。
3.3.1文本与其他材料
Mukherjee和Acton[63]描述了一种用于文档页面分割的多尺度聚类技术。与分层多分辨率方法不同,这种文档图像分割技术同时利用原始图像不同尺度表示的信息。在尺度空间中,通过基于模糊c-均值的向量间相似性度量,实现图像片段的最终聚类。分割过程被认为是为了减少不重要的细节和噪声的影响,同时保持对象的完整性。他们的结果表明,尺度空间方法可以有效地对文档编码进行有意义的页面分割。缺点之一是在生成比例空间本身时会产生额外的成本。作者目前正在优化他们的计算速度的方法,并开发基于对象的编码算法,以补充分割方法。
Andersen和Zhang[3]提出了应用于报纸文档分割的基于神经网络的区域识别算法中的几个关键特征。他们的方法被称为达到了良好的识别准确率(98.09%),特别是考虑到区域过度分割的程度。作者提出了一种进一步提高分割结果的可能性,通过实现一个具有两个输出节点(一个节点表示文本,另一个节点表示非文本)的软决策神经网络将某些区域划分为非同质区域,即同时包含文本和非文本。有了这种配置,就可以将这种类型的区域重新划分为同质的部分,这样分类过程就有可能纠正初始分割过程中的一些错误。他们目前的工作也集中在通过使用上下文信息(来自相邻区域的信息)以及来自灰度文档的特征来提高分类精度。初步研究表明,这可以减少高达50%的误差。
Ma和Doermann[57]提出了一种页面分割模型的自举学习方法。他们的想法源于试图分割具有一致页面结构的文档图像(例如字典),并扩展到更一般的结构化文档的分割。他们认为,在页面结构高度规则的情况下,通过先使用少量样本对系统进行训练,然后根据训练结果处理较大的测试集,就可以从仅有几页的示例中学习布局。训练阶段可以迭代多次来优化和稳定学习参数。他们将这种分割方法应用于词典、电话簿、口语成绩单等许多结构化文档中,并取得了令人满意的分割效果。作者承认,包含图片、图表和表格的结构化文档可能会对当前的方法实现造成问题,因为具有此类非文本元素的页面通常缺乏一致的结构。
郑等。[92]提出了一种在噪声文档图像中识别和分割手写注释的方法。这种手写注释通常作为认证标志出现,它是注释、更正、澄清、指示或签名的(一部分)。他们的方法包括两个过程:
- 页面分割,将文本按适当的层次划分为多个区域:字符、单词或区域
- 分类,识别分割区域为手写
为了确定能够可靠地进行分类的近似区域大小,他们在字符、单词和区域级别进行了实验。在词水平上获得了可靠的分类结果,分类准确率为97.3%。他们的实验表明,这种方法在噪声过大的文档中可能会出现许多错误识别。他们在随后的研究[93]中解决了这个问题,他们使用马尔可夫随机场(MRF)来模拟印刷文本的几何结构,手写体和噪声来纠正错误的分类。
3.3.2 查找文本行
文本行的精确识别是大多数OCR系统的重要组成部分。它对文档布局分析也非常有用。对于文本行和基线的查找,已经提出了许多方法。有些方法试图只找到文本行,例如使用Hough变换[32,83]、投影轮廓和Radon变换。其他人发现文本行是更一般的文档布局分析任务的一部分,例如XY剪切、空白分割、Voronoi图和基于距离的分组。通常,这种方法首先对布局进行粗略分析,通常基于连接组件或连接组件本身的边界框的接近程度。根据需要,在后续步骤中使用更精确的基线和文本线模型[29,67]。
Breuel[10]提出了一种算法,可以精确地找到页面旋转并可靠地识别文本行。该方法采用分枝定界法进行全局最优寻线。同时在稳健的最小二乘(或最大似然)模型下对基线和下降线搜索进行了优化。该算法易于实现,自由参数的数量非常有限(误差范围、允许的页面旋转和下降尺寸的范围以及数值精度)。该方法显然对文档退化非常敏感,因为文档退化会将大量字符合并到同一个连接组件中。该算法在华盛顿大学数据库2的英文备忘录集上进行了测试,该数据库由62个扫描的备忘录组成,显示了各种字体和手动注释,并呈现出各种各样的图像噪声。当提取的边界框允许时,文本行拟合算法可以正确识别文档中的所有行。没有检测到虚假的文本行,一些短的单字行被忽略。这个算法的一个特别有趣的特性是它允许文本行方向的变化。这使得该算法可以应用于由照片或摄像机而不是扫描仪捕获的文档图像。
Bai和hou[4]提出了一种从手持式笔式扫描仪捕获的文档图像中提取目标文本行的方法。给定一个二值图像,一组可能的文本行首先由连接的组件的最近邻分组形成。然后通过文本行合并和添加缺少的连接组件来优化文本行集。通过基于几何特征的分数函数识别出可能的目标文本行。OCR引擎读取此目标行,如果识别的置信度很高,则接受目标文本行,否则,所有剩余的文本行都将输入OCR引擎,以验证是否存在替代目标文本行,或者是否应拒绝整个图像。在由C-Pen和ScanEye笔扫描仪采集的117幅文档图像组成的测试数据库上进行的一系列实验证实了上述方法的有效性。对于C-Pen,113行中有112行被正确检测,1行被错误分割,没有一行被错误删除。对于ScanEye,在121行中,120行被正确检测到,1行被错误分割,没有一行被错误删除。
3.3.3 文本阅读顺序检测
确定文本块之间的读取顺序对于创建和维护数字图书馆(DL)的OCR系统至关重要,因为它将允许更完全自动地浏览文本图像。此功能还可以帮助OCR系统利用高级上下文来提高准确性。

根据Baird[6]的观点,自动阅读顺序检测通常仍然是一个开放性的问题,因为大量的案例不能仅仅通过文档布局分析自动消除歧义,而似乎需要语言甚至语义分析。
在一个典型的场景中,当一个页面上的歧义案例数量很小时,文本排序歧义问题实际上是通过一个精心设计的交互式GUI来解决的,该GUI以一种易于选择或更正的方式呈现歧义。这种功能存在于专门的高吞吐量扫描和转换服务局,但在消费者级OCR系统中不常见。
Aiello等人。[2] 提出了一个文档分析系统,该系统能够分配逻辑标签并从大量文档中提取阅读顺序。他们的文档分析使用了多种信息源:从几何特征和空间关系到文本特征和内容。为了有效地处理这些信息源,他们定义了一个通用的、足够灵活的文档表示来表示复杂的文档。分别针对文档对象类型body和title单独检测可能的读取顺序。然后,使用标题正文连接规则将这些阅读顺序组合在一起,该规则将一个标题与位于标题下方的最左侧最上面的正文对象连接起来。阅读顺序取决于几何信息(基于空间关系)和内容(基于词汇分析)信息。实验使用两个文件集进行:华盛顿大学UW-II英文期刊数据库(623页)和芬兰奥卢大学的MTDB(171页)。图7显示了一个文档的示例,以及空间分析单独检测到的可能的读取顺序。基于NLP的词汇分析模块发现第一个阅读顺序是正确的。
4 OCR后处理
虽然OCR系统在不太完美的真实世界文档图像上使用了不断提高但却有限的识别能力,因此OCR系统很容易出错。因此,预计OCR输出将包含错误:OCR噪声。有些系统试图纠正有噪声的OCR输出(例如通过拼写检查程序),有些系统使用高级上下文(例如词典)来迭代提高OCR的准确性,而其他系统则只是选择接受有噪声的OCR输出,并在随后的索引和文本检索阶段(例如,通过模糊字符串匹配)考虑可能的OCR错误。无论哪种情况,都必须处理某种OCR后处理。
Spitz[82]描述了一种OCR方法,该方法依赖于将文本图像转换为字符形状代码、快速和健壮的识别过程,以及包含单词“形状”信息和特定单词形状分类中存在的字符歧义的特殊词典。目前,该方法考虑到英语的结构以及形状代码和单词中字符之间的单例映射比例很高。通过查找可以消除相当多的歧义
通过在经过特殊调整和结构化的词典中查找和逐字符替换来消除相当多的歧义。利用字体、字体、字体和大小以及图像质量的局部一致性,使用从周围文本中提取的样本进行模板匹配,进一步降低了模糊度。
Klein和Kopel[45]提出了一种提高OCR精度的后处理系统。它们描述了如何匹配几个OCR引擎的输出,从而检测出可能的错误,并根据统计信息和字典提出可能的更正建议。他们在希伯来语、英语和法语文本集合上测试了他们的系统,每种语言使用两种不同的OCR引擎。根据他们的测试结果,所提出的系统可以显著降低错误率,同时提高校正过程的效率,使大规模的自动数据采集系统更接近于成为现实。
Beitzel等人。[9] 简要介绍OCR文本检索技术。他们将OCR数据检索问题作为搜索“嘈杂”或错误填充的文本来解决。他们讨论的技术包括:为OCR文本集合定义IR模型,使用OCR错误感知处理组件作为文本分类系统的一部分,自动更正OCR过程中引入的错误,以及改进噪声数据的字符串匹配。
5 总结
本报告旨在回顾现代光学字符识别(OCR)领域的主要趋势。我们介绍了OCR作为模式识别的一个成功分支(机器视觉中的一个更通用的学科),描述了一个典型的OCR系统及其组成部分,定义了OCR系统的两个主要类别(通用和特定任务),概述了OCR的基本技术,并提到了许多现有的OCR解决方案(两者都是商业和公共领域)。
我们还讨论了OCR常见的困难,分析了其潜在的原因,并提出了解决这些困难的可能途径。详细讨论了与
- 文字与语言
- 文档图像类型和图像缺陷
- 文档分割
- 字符类型
- OCR灵活性、准确性和生产力
- 手写和印刷
- OCR预处理和后处理
在我们的讨论过程中,我们提到了积极研究的领域以及与每个问题相关的现有OCR系统。所有OCR精度和性能数据均取自参考出版物。任何额外的基准测试都不在本次调查的范围之内。
5.1 结论
光学字符识别技术自20世纪50年代中期商业化以来,取得了令人瞩目的进展。经过特别设计的“标准”字体,例如OCR-A和OCR-B(分别见图8和图9),出现了对elite和pica固定间距字体的支持(如图10和11所示),最后是omni字体排版文本(比如你正在阅读的文档)。早期的OCR实验系统通常是基于规则的。到了20世纪80年代,它们已经完全被基于统计模式识别的系统所取代。对于使用欧洲文字的清晰分割印刷材料,这种模式识别技术提供了几乎没有错误的OCR。自20世纪90年代以来,手写数字和受限字母数字字段的表单阅读器(通常以较高的拒绝/错误率运行)的接受率显著提高。目前,许多研究者正致力于离线和在线草书书写,或致力于多种文字的多语种识别。
当符号数量较多时,如在中文或韩文书写系统中,或当符号不彼此分离时,如在阿拉伯文或天成文书印刷体中,目前的OCR系统与人类读者的错误率仍相差甚远,当源图像质量受到损害时,例如传真传输,OCR的精度会进一步下降。
在手印文本的识别中,目前普遍采用的是具有连续分割、分类和识别(语言建模)阶段的算法。基于隐马尔可夫模型(HMMs)的统计技术在手写体识别中得到了成功的应用。基于HMM的技术可以并行地进行分割、分类和识别决策,但它们的性能仍有待提高,这主要是因为手写体的固有可变性大于语音的可变性,在某种程度上,处理难以辨认的笔迹比处理难以辨认的言语更为常见。
OCR系统成本的降低可能比分类方法的范围和准确性的改进更引人注目。早期的OCR设备都需要昂贵的扫描仪和特殊用途的电子或光学硬件,例如,在社会保障管理局(socialsecurityadministration)使用的ibm1975光学页面阅读器(optical Page Reader)的成本超过300万美元。在1980年前后,个人电脑和电荷耦合阵列扫描器所采用的廉价微处理器,使成本大幅下降,与通用电脑相当。如今,OCR软件是任何桌面扫描仪的常见附加组件,其成本与打印机或传真机差不多(如果不低于)的话。
5.2有前途的方向
尽管存在种种挑战和困难,光学字符识别仍然是机器视觉一个令人兴奋的大领域中的一个成功案例,这一领域已经有许多其他成功的人造物体(或模式)识别系统。为了继续这一令人兴奋的成功故事,OCR社区必须强调其技术优势,通过投资研究寻找新的想法,并遵循最有希望的方向,包括
- 自适应OCR旨在对更广泛的印刷文档图像进行稳健处理
- 作为OCR预处理的一部分的文档图像增强
- 对上下文的智能使用为OCR引擎提供了更大的图片,并使识别任务更加集中和健壮
- 各种形式的手写体识别,静态和动态、通用和特定任务等。
- 多语言OCR,包括多个嵌入式脚本
- 多媒体OCR,用于识别任何环境下由任何视觉传感器捕获的任何文本
以上的一些OCR主题听起来有点野心勃勃,但随着当前信息技术的总体增长率,尤其是OCR,我们相信它们并非遥不可及。