Python-seaborn 笔记整理
仅供个人自学使用,仅供参考
Reference:
https://vitu.ai/course/65599248200156992
https://www.jianshu.com/p/94931255aede
https://baijiahao.baidu.com/s?id=1650565251991078037&wfr=spider&for=pc
https://www.cnblogs.com/abdm-989/p/12204640.html
某速查表
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
特点
- 基于matplotlib aesthetics绘图风格,增加了一些绘图模式
- 增加调色板功能,利用色彩丰富的图像揭示您数据中的模式
- 运用数据子集绘制与比较单变量和双变量分布的功能
- 运用聚类算法可视化矩阵数据
- 灵活运用处理时间序列数据
- 利用网格建立复杂图像集

5种主题风格 - darkgrid
- whitegrid
- dark
- white
- ticks
导包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Seaborn 要求原始数据的输入类型为 pandas 的 Dataframe 或 Numpy 数组,画图函数有以下几种形式
sns.图名(x='X轴 列名', y='Y轴 列名', data=原始数据df对象)
sns.图名(x='X轴 列名', y='Y轴 列名', hue='分组绘图参数', data=原始数据df对象)
sns.图名(x=np.array, y=np.array[, ...])
通用设置
# Set the width and height of the figure
plt.figure(figsize=(14,6))
# Add title
plt.title("标题")
#调整x,y轴的限制
plt.ylim(0,100)
plt.xlim(0,10)
#调属性
plt.setp(ax,yticks=[0,5])
#调整子图参数
plt.tight_layout()
#将上下文设置为 "notebook", 缩放字体,覆盖参数映射
sns.set_context("notebook", font_scale=1.5, rc={"lines.linewidth":2.5})
#显示图形
plt.show()
#保存
plt.savefig("foo.png")
#保存为透明画布
plt.savefig("foo.png", transparent=True)
各种图
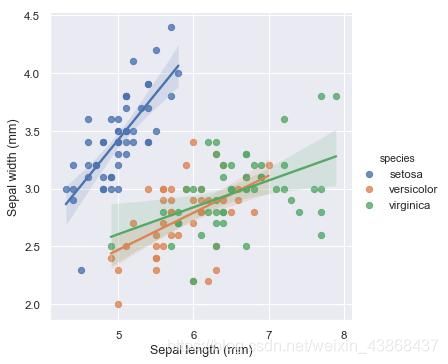
lmplot
lmplot主要用于可视化线性回归关系,也就是用来画回归图,可以观察两组数据之间是否存在线性关系。
# 设置图表风格为darkgrid
sns.set(style='darkgrid')
# 读取Seaborn自带的数据集
irisiris = sns.load_dataset("iris")
# x轴为萼片长度,y轴为萼片宽度
# hue: 根据品种分类
# truncate: 截断,为True时回归线受到数据大小的限制,默认为False
# height:图表大小
g=sns.lmplot(x="sepal_length",y="sepal_width",hue="species",truncate=True, height=5, data=iris) # 设置x轴和y轴的标签
g.set_axis_labels("Sepal length (mm)", "Sepal width (mm)")
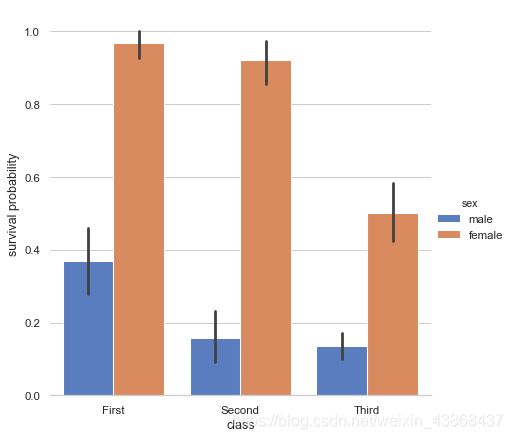
catplot
catplot用于将分类图绘制到FacetGrid界面上,根据kind参数不同可以绘制不同类型的分类图。
# 设置风格
sns.set(style="whitegrid")
# 读取数据集
titanic titanic = sns.load_dataset("titanic")
# 显示不同船舱等级和性别下的存活率
g=sns.catplot(x="class",y="survived", hue="sex",data=titanic,height=6, kind="bar", palette="muted")
# 不显示y轴
g.despine(left=True)
# 设置y轴标签
g.set_ylabels("survival probability")
boxplot
箱形图(或箱须图)可以在变量之间或类别变量之间以比较的方式显示定量数据的分布。
# 设置风格,调色盘
sns.set(style="ticks", palette="pastel")
# 读取数据集
tips tips = sns.load_dataset("tips")
# 根据日期和是否吸烟对小费数目进行分类显示
sns.boxplot(x="day", y="total_bill", hue="smoker", palette=["m", "g"], data=tips)
# offset设置纵横两轴近原点端点距离原点的距离
# trim限制显示的轴线的范围
sns.despine(offset=10, trim=True)

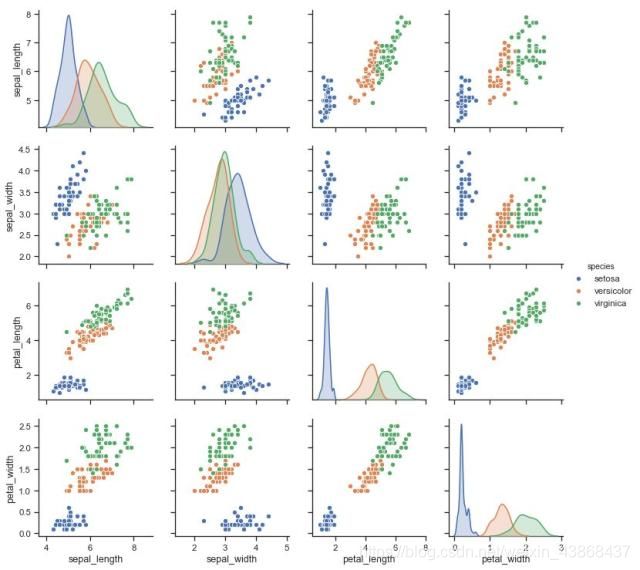
pairplot
变量关系组图,此函数将创建一个轴网格,显示每两个变量之间的分布情况。对角轴的处理方式有所不同,显示单个变量的分布图。
# 设置风格
sns.set(style="ticks")
# 读取数据集
irisdf = sns.load_dataset("iris")
# 显示分布图
sns.pairplot(df, hue="species")
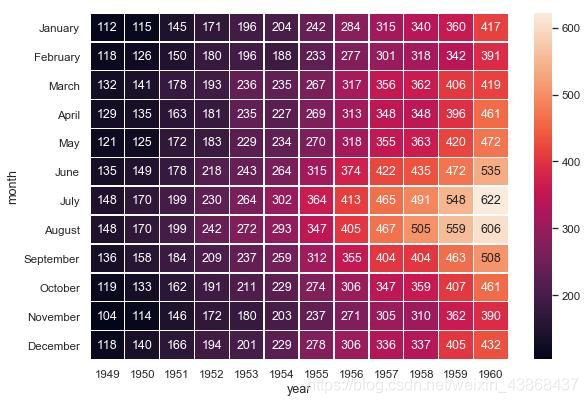
heatplot
热力图,绘制矩形数据作为颜色编码矩阵。
# 设置为默认风格、
sns.set()
# 读取数据集
flightsflights_long = sns.load_dataset("flights")
# pivot(): 根据列值重塑数据
index='month',column='year', values='passengers'
flights = flights_long.pivot("month", "year", "passengers")
# 用每个单元格中的数值绘制热图
f, ax = plt.subplots(figsize=(9, 6))
sns.heatmap(flights, annot=True, fmt="d", linewidths=0.5, ax=ax)
barplot
柱状图,如其名
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.arange(8)
y = np.array([1,5,3,6,2,4,5,6])
df = pd.DataFrame({"x-axis": x,"y-axis": y})
sns.barplot("x-axis","y-axis",palette="RdBu_r",data=df)
plt.xticks(rotation=90)
plt.show()
横坐标为0-7的整数,纵坐标表示这八个整数分别所占的权重,调整 palette 参数可以美化显示风格

散点图
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
加回归,把命令换成sns.regplot
regplot()和lmplot()都可以绘制回归关系,推荐regplot()。
两者间主要的区别是:regplot接受各种格式的x y,包括numpy arrays ,pandas series 或者pandas Dataframe对象。相比之下,lmplot()只接受字符串对象。这种数据格式被称为’long-form’或者’tidy’。除了输入数据的便利性外,regplot()可以看做拥有lmplot()特征的一个子集。
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])

带颜色分类的散点图
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])

sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)

直方图
distplot
# kde 密度曲线 rug 边际毛毯
sns.distplot(a=iris_data['Petal Length (cm)'], kde=False, rug = False)

密度图
kdeplot
# shade 阴
sns.kdeplot(data=iris_data['Petal Length (cm)'], shade=True)

二维密度图
jointplot
特殊参数
kind : { “scatter” | “reg” | “resid” | “kde” | “hex” }
基本参数
color : 颜色。参数类型: matplotlib color
size : 默认 6,图的尺度大小(正方形)。参数类型:numeric
ratio : 中心图与侧边图的比例,越大、中心图占比越大。参数类型:numeric
space : 中心图与侧边图的间隔大小。参数类型:numeric
s : 点的大小。参数类型:numeric
linewidth : 线的宽度。参数类型:numeric
edgecolor : 点的边界颜色,默认无色,可以重叠。”w”为白色。参数类型:matplotlib color
{x, y}lim : x、y轴的范围。参数类型:two-tuples
{joint, marginal, annot}_kws : dicts Additional keyword arguments for the plot components.
marginal_kws : 侧边图的信息。例如:dict(bins=15, rug=True)
annot_kws : 注释的信息。例如:dict(stat=”r”)
sns.jointplot(x=iris_data['Petal Length (cm)'], y=iris_data['Sepal Width (cm)'], kind="kde")

## 设置颜色
sns.set(color_codes=True)
mean, cov = [0, 1], [(1, .5), (.5, 1)] # 设置均值(一组参数)和协方差(两组参数)
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("ticks"):
sns.jointplot(x=x, y=y, kind="hex", color="k")
plt.show()
树形图
类似于散点图,用于显示每一个数据的分布情况
tips = sns.load_dataset("tips")
sns.swarmplot(x="day", y="total_bill",hue="sex",data=tips)
plt.show()

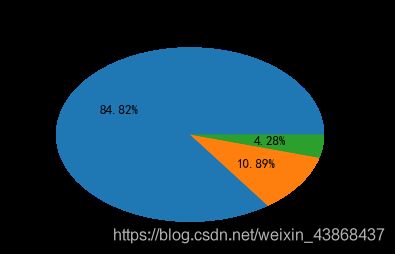
饼图
phone=df.phone_operator.value_counts()
df_phone=pd.DataFrame({'phone_operator':phone.index[1:],'fre':phone.values[1:]})
plt.rc('font', family='SimHei', size=13)
fig = plt.figure()
plt.pie(df_phone.fre, labels=df_phone.phone_operator, autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("手机运营商分布")
plt.show()
记数图
sns.countplot(x="deck", data=titanic, palette="Greens_d")
点图
sns.pointplot(x="class", y="survived", hue="sex", data=titanic, palette={"male":"g","female":"m"}, markers=["^","o"], linestyles=["-","--"])