Bert分类将检查点ckpt模型转成saved model的pb模型
使用官方提供的Bert中文模型做分类之后,由于某些方面的需求,需要将训练的checkpoints模型转换成pb模型,但是由于对Bert模型不是很了解,一些方法没法使用,最后找到一些工具,成功转换。这里记录一下。如果有和我情况完全一致的人,可以使用和我一样的方法来转换。推荐使用2.3的方法。下面记录下我的出错流水账。
我的情况:
1.使用的是Bert模型的分类模型(见2.2第一个参考博文,里面说别的模型可能会出错)
2.没有仔细看代码,不清楚Bert模型的输入输出变量都是什么(知道的就能用2.1的通用方法了)。
如果只想知道怎么转换,直接看2.2。
PS:在发现2.3的方法的过程中,发现pb模型,也就是saved model模型是应该有两个文件的。
但是2.2的方法只生成了pb文件,另外一个文件缺失,没法用,建议用2.3的方法。
3. 学习使用TensorRT的时候,发现了一种更好的新方法,记录在2.3。如果是已经训练好的ckpt,可以直接修改代码重新生成。非常方便,建议用这个。
下面顺便记录一下Bert相关的一些情报,避免我以后忘记。
1.Bert模型
谷歌官方BERT:https://github.com/google-research/bert
bert中文模型的GitHub:https://github.com/ymcui/Chinese-BERT-wwm/tree/5f78b7dad237cbdc76557ffc5b895481afeaf278
关于Bert模型的使用,我的理解是,分为预训练和fine-tuning两步。可以下载预训练完成的预训练模型(也可以自己训练),然后在此基础上进行fine-tuning,变成分类模型或者别的模型,这里第一个链接就是官方提供的fine-Tuning代码。
在第一个链接下载代码,在第二个链接下载中文预训练模型文件。
这里我使用的是最大的那个预训练模型。
![]()
想要关于Bert更详细的理论和代码解释,可以参考:
理论详解:https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
更多: https://zhuanlan.zhihu.com/p/130913995
以及代码详解:https://www.jianshu.com/p/aa2eff7ec5c1
2.ckpt模型转pb模型
2.1 通用转换方法
参考:https://www.jianshu.com/p/a33742957a36
这个方法需要知道模型的输出变量名。![]()
我不知道输出变量名是什么,于是尝试将所有的变量名打印出来(方法见2.1.2),但是从我打印出来的变量名中,也很难看出到底哪个是输出变量.
1.output_weights/adam_v
2.output_weights/adam_m
3.output_bias/adam_v
......
1175.bert/encoder/layer_0/output/dense/bias/adam_m
1176.bert/encoder/layer_23/intermediate/dense/kernel/adam_m
1177.bert/encoder/layer_17/intermediate/dense/kernel/adam_m
1178.bert/encoder/layer_23/output/LayerNorm/beta
1179.bert/encoder/layer_8/attention/self/key/bias/adam_m
1180.bert/encoder/layer_23/output/LayerNorm/beta/adam_m
按照顺序来看的话,见上图,其中好几个都像是,所以也无法根据顺序判断。我尝试将一个我觉得像的变量放进去,代码执行成功了,但是pb模型非常小,只有几kb。我看理论上输出的pb模型是只将与你写的输出Tensor相关的部分抽出来,所以模型才这么小,但是这么小的模型肯定是不对的。这里失败。
2.1.1 ckpt模型
这里了解下ckpt模型的几个文件的作用
参考 https://blog.csdn.net/u014061630/article/details/80461044
2.1.2 获取模型的参数
PS:如果用官方代码训练的话,其实是会在开始的info中打印出所有的参数的。
这里粘贴一下开头和结尾的info,我觉得这里就是输入和输出参数
INFO:tensorflow:**** Trainable Variables ****
I0623 18:34:39.674900 139725119866688 run_classifier_pb.py:754] **** Trainable Variables ****
INFO:tensorflow: name = bert/embeddings/word_embeddings:0, shape = (21128, 1024), *INIT_FROM_CKPT*
I0623 18:34:39.675090 139725119866688 run_classifier_pb.py:760] name = bert/embeddings/word_embeddings:0, shape = (21128, 1024), *INIT_FROM_CKPT*
........
*INIT_FROM_CKPT*
INFO:tensorflow: name = output_weights:0, shape = (2, 1024)
I0623 18:34:39.702357 139725119866688 run_classifier_pb.py:760] name = output_weights:0, shape = (2, 1024)
INFO:tensorflow: name = output_bias:0, shape = (2,)
I0623 18:34:39.702441 139725119866688 run_classifier_pb.py:760] name = output_bias:0, shape = (2,)方法一(直接打印所有参数):
也可以参考上面的链接,下面是我用的代码:
# coding:utf-8
import tensorflow as tf
'''
# 使用inspect_checkpoint来查看ckpt里的内容
from tensorflow.python.tools import inspect_checkpoint as chkp
chkp.print_tensors_in_checkpoint_file(file_name="../outputs/model.ckpt-150000",
tensor_name=None, # 如果为None,则默认为ckpt里的所有变量
all_tensors=False, # bool 是否打印所有的tensor,这里打印出的是tensor的值,一般不推荐这里设置为False
all_tensor_names=True) # bool 是否打印所有的tensor的name
'''
# 上print_tensors_in_checkpoint_file其实是用NewCheckpointReader实现的.
model_path = "../outputs/model.ckpt-150000"
outfile = "../output.txt"
## 下面两个reader作用等价
#reader = pywrap_tensorflow.NewCheckpointReader(model_path)
reader = tf.train.NewCheckpointReader(model_path)
## 用reader获取变量字典,key是变量名,value是变量的shape
var_to_shape_map = reader.get_variable_to_shape_map()
with open(outfile,"w") as f:
for var_name in var_to_shape_map.keys():
#用reader获取变量值
var_value = reader.get_tensor(var_name)
#print("var_name",var_name)
#print("var_value",var_value)
#f.write(var_name + ": "+str(var_value)+ "\n")
f.write(var_name + "\n")
方法二(TensorRT中提到的):
If your model is in checkpoint or graphdef format and you do not know the input and output nodes of the model, you can use the summarize_graph TensorFlow utility. The summarize_graph tool does need to be downloaded and built from source. If you have the option of going to your model provider and obtaining the model in saved model format, then we recommend doing so.
链接:https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
这个方法是看TensorRT的时候提到的,但是我没用过,有需要的可以试试。
2.2 专用转换方法
在由于不知道Bert模型的参数导致上面的方法失败之后,我又去查了下Bert模型,看有没有专门讲Bert模型的转换的。发现了一个很好的博文https://blog.csdn.net/zhonghua50yuan/article/details/117253735?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
这篇文章指出了他使用的转换代码:https://github.com/xmxoxo/BERT-train2deploy 里面的 freeze_graph.py工具 ,要放到Bert文件夹下。将里面的参数调整一下,例如分类数目,bert文件的名字和位置之类的。然后就可以转换了。
python freeze_graph.py \
-bert_model_dir ../chinese_roberta_wwm_large_ext \
-model_dir ../outputs \
-model_pb_dir ../pb_model_dir \
-max_seq_len 64 \
-num_labels 2我成功转换之后,生成了一个1.2G的pb文件。
2.3 直接修改代码重新生成的方法
参考:https://www.cnblogs.com/demo-deng/p/13892636.html
将这段代码添加run_classifier.py中,添加到estimator.train后面。上面的代码里最后一个形参
is_tpu_estimator 没有用到,把这个形参删掉就行。
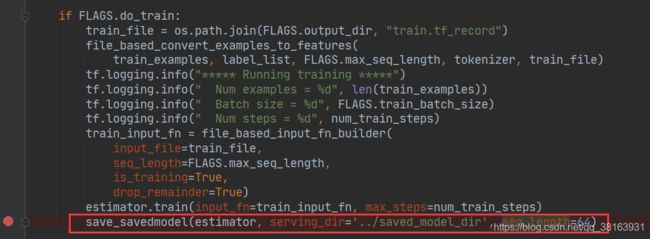
添加这句之后执行这个训练代码,如果你之前训练过了的话,其实是不会重新训练的,只会将ckpt文件转换成saved model文件,这里转换的文件是齐全的,包含variable文件,速度很快,几分钟就会转换完毕。建议使用这种方法转换。