【深度推荐算法】DataWhale组队学习Task01: DeepCrossing
DeepCrossing
动机
将深度学习架构应用于推荐系统中的模型2016年由微软提出, 完整的解决了特征工程、稀疏向量稠密化, 多层神经网络进行优化目标拟合等一系列深度学习再推荐系统的应用问题。
- 应用场景
微软搜索引擎Bing中的搜索广告推荐(用户输入搜索查询进店之后,搜索引擎返回相关结果还返回与搜索词相关的广告) - 优化目标
预测某一广告,用户是否会点击,依旧是点击率预测的问题。
点击率预测,即CTR预估。CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content)。 - 输入特征
| 指标 | 数据类型 | 如何处理 |
|---|---|---|
| 广告id | 类别型特征 | one-hot编码 |
| 广告预算 | 数值型特征 | 归一化处理(进行简单清洗) |
| 广告id | id | 数值型特征 |
这个模型在传统神经网络的基础上加入了embedding,残差连接等思想,且结构比较简单。
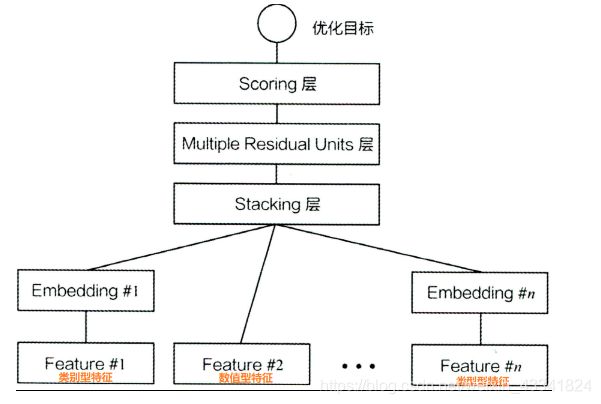
模型结构

提出了一种深度交叉模型(Deep Crossing),它是一种深度神经网络,可以自动地将特征进行组合,生成更优的模型。
输入
一组个体特征,可以是密集的,也可以是稀疏的。
重要的交叉特征由网络隐式发现,网络由嵌入和叠加层,以及残留单元的级联组成。
输出
对这些特性没有显式表示的模型。
相关研究
CNN
深度cnn使用特定于任务的过滤器捕获的特征之间的深度交互
深度语义相似模型Deep Semantic Similarity Model (DSSM)
深度语义相似模型[10]学习一对文本字符串之间的语义相似度,每个文本字符串都由一种称为三字母克的稀疏表示表示。学习算法通过将三字母克嵌入到两个向量中来优化基于余弦距离的目标函数。学习到的嵌入捕获单词和句子的语义,并已被应用于赞助搜索、问题回答和机器翻译,并获得强大的结果。
因子分解机Factorization Machines (FM)
因式分解机(FM)[15]在其一般形式下模型了个体特征之间的d-way交互作用。在输入非常稀疏的情况下,FM显示出比支持向量机更好的结果,但它在密集特征上的表现尚不清楚。
赞助搜索SPONSORED SEARCH
赞助搜索【5】负责在有机搜索结果旁边显示广告。在这个生态系统中有三种主要的代理:用户、广告商和搜索平台。该平台的目标是向用户展示最符合用户意图的广告,主要通过特定的查询来表达。下面是接下来讨论的关键概念
FEATURE REPRESENTATION
Individual Features
![]()
- text feature
- category
- counting feature

除计数特征外,所有引入的特征都是稀疏特征。
Combinatorial Features

模型结构
- The objective function
is log loss for our applications but can be easily cus-
tomized to soft-max or other functions. Log loss is defined
as:
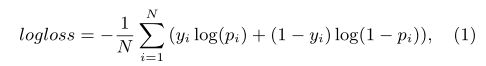
- where i i i indexes to the training samples
- N N N is the number of samples
- y i y_i yi is the per sample label. The label y i y_i yi in the click prediction problem is a user click.
- p i p_i pi is the output of the one-node Scoring Layer in Fig. 1, which is a Sigmoid function in this case.
- The Embedding Layer
对每个特征进行嵌入来转换输入特征。嵌入层由单个神经网络组成,一般形式为:

- j j j indexes the individual feature
- X i j ∈ R n j X_{ij} \in R^{n_j} Xij∈Rnj is the input feature
- W j W_j Wj is an m j × n j m_j \times n_j mj×njmatrix

Stacking layer
然后输出特征被堆叠(连接)成一个向量作为下一层的输入:

- 与Word2Vec等方法仅仅嵌入不同的是
这种嵌入需要和模型一起训练
需要训练的参数为 { W j } \{W_j\} {Wj} { b j } \{b_j\} {bj}
Multiple Residual Units Layer

残差单元的唯一特性是通过两层ReLU转换后将原始输入特征重新添加回来。具体地说:
![]()
将右边的移到左边来
![]() =
=![]()
深交叉确实展示了一些可能受益于剩余单位的属性(Deep Crossing did exhibit a few properties that might benefit from the Residual Units)
Scoring Layer
CTR预估二分类,往往采用逻辑回归
看代码用的是sigmoid函数
整体模型架构图
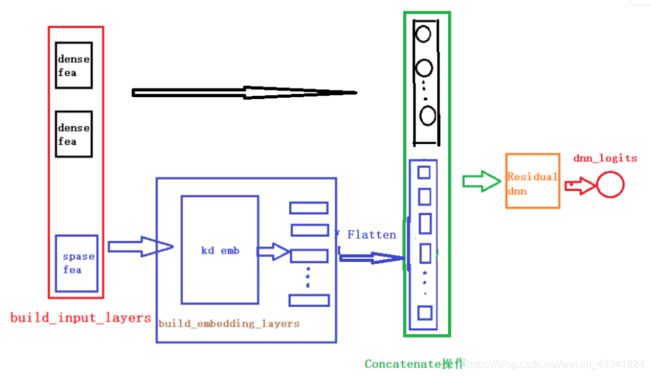
只包含部分特征的模型结构图
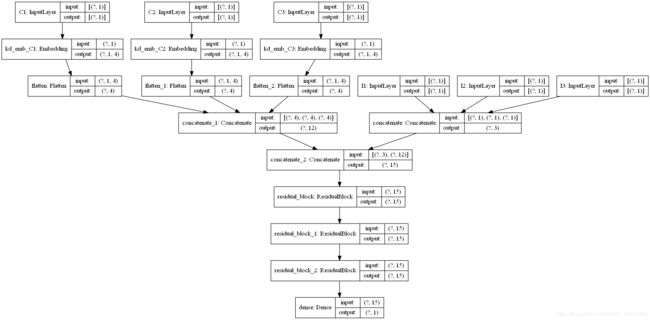
代码部分
读取数据
data = pd.read_csv('criteo_sample.txt')
划分dense和sparse特征
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]

构造一个
# 简单的数据预处理
from sklearn.preprocessing import LabelEncoder
def data_process(data_df, dense_features, sparse_features):
"""
简单处理特征,包括填充缺失值,数值处理,类别编码
param data_df: DataFrame格式的数据
param dense_features: 数值特征名称列表
param sparse_features: 类别特征名称列表
"""
data_df[dense_features] = data_df[dense_features].fillna(0.0)#缺失值填充
for f in dense_features:#每一列的特征的名字
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)#如果x>-1(因为x+1>0才能计算对数)就计算为log(x+1)转化为对数,否则就等于-1
data_df[sparse_features] = data_df[sparse_features].fillna("-1")#缺失值填充
for f in sparse_features:
lbe = LabelEncoder()
data_df[f] = lbe.fit_transform(data_df[f])
return data_df[dense_features + sparse_features]
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
pandas.DataFrame.fillna
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
功能:使用指定的方法填充NA / NaN值
参数:value : 变量, 字典, Series, or DataFrame
用于填充缺失值(例如0),或者指定为每个索引(对于Series)或列(对于DataFrame)使用哪个字典/Serise/DataFrame的值。(不在字典/Series/DataFrame中的值不会被填充。)这个值不能是一个列表。
LabelEncoder() 参考
Encode labels with value between 0 and n_classes-1
即将离散型的数据转换成 0 0 0 到 n − 1 n-1 n−1 之间的数,这里 n n n 是一个列表的不同取值的个数,可以认为是某个特征的所有不同取值的个数。
LabelEncoder().fit_transform(data_df[f])
将DataFrame中的每一行ID标签分别转换成连续编号
# 将特征做标记
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for feat in sparse_features] + [DenseFeat(feat, 1,)
for feat in dense_features]
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
# 定义一个embedding层对应的字典
embedding_layers_dict = dict()
# 将特征中的sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
if is_linear:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, 1, name='1d_emb_' + fc.name)
else:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='kd_emb_' + fc.name)
return embedding_layers_dict
# 将所有的sparse特征embedding拼接
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
# 将sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
embedding_list = []
for fc in sparse_feature_columns:
_input = input_layer_dict[fc.name] # 获取输入层
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
embed = _embed(_input) # B x dim 将input层输入到embedding层中
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list
# DNN残差块的定义
class ResidualBlock(Layer):
def __init__(self, units): # units表示的是DNN隐藏层神经元数量
super(ResidualBlock, self).__init__()
self.units = units
def build(self, input_shape):
out_dim = input_shape[-1]
self.dnn1 = Dense(self.units, activation='relu')
self.dnn2 = Dense(out_dim, activation='relu') # 保证输入的维度和输出的维度一致才能进行残差连接
def call(self, inputs):
x = inputs
x = self.dnn1(x)
x = self.dnn2(x)
x = Activation('relu')(x + inputs) # 残差操作
return x
# block_nums表示
DNN残差块的数量
def get_dnn_logits(dnn_inputs, block_nums=3):
dnn_out = dnn_inputs
for i in range(block_nums):
dnn_out = ResidualBlock(64)(dnn_out)
# 将dnn的输出转化成logits
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logits
# 构建DeepCrossing模型
def DeepCrossing(dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
#将所有的dense特征拼接到一起
dense_dnn_list = list(dense_input_dict.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
# 将dense特征和Sparse特征拼接到一起
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)
# 输入到dnn中,需要提前定义需要几个残差块
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
model = Model(input_layers, output_layer)
return model
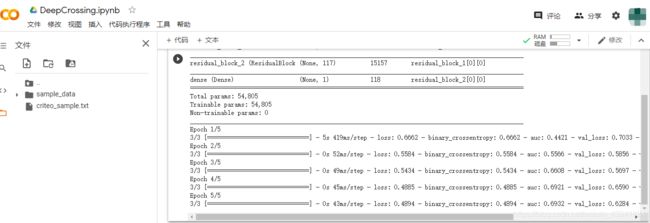
history = DeepCrossing(dnn_feature_columns)
history.summary()
history.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 将输入数据转化成字典的形式输入
train_model_input = {name: data[name] for name in dense_features + sparse_features}
# 模型训练
history.fit(train_model_input, train_data['label'].values,
batch_size=64, epochs=5, validation_split=0.2, )
结果:
参考:
DataWhale深度推荐模型组队学习
Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features