CenterTrack复现步骤和问题汇总
工程路径:link
准备工作:
在CenterTrack/readme/INSTALL.md中查看工程依赖的环境要求。

在按照作者给出的环境配置步骤操作之前,强烈建议先去git issue页面看一下是否有关于环境配置的相关提问和解决方案,尤其是跟自己当前的系统配置相似的issue。
整个环境我断断续续配置了两天时间(一部分原因是网速慢)才完成,其中大部分的问题都是可以先读issue来避免踩坑的。
因此,以下是最终能够成功运行的配置步骤:
步骤一:
为了不破坏公用的服务器环境,依旧采用单独的镜像来维护不同项目所需的环境配置。依据作者的环境建议和我当前项目的情况,采用了cuda10.0+cudnn7+ubuntu18.04这样的配置。
在DockerHublink上找到相应的镜像,然后下载该镜像:
docker pull nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04
步骤二:
完成镜像的下载之后,运行该镜像。并在镜像中查看是否能够正常访问cuda驱动以及cudnn版本。
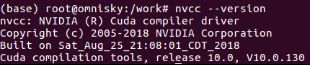
运行nvidia-smi,看到cuda驱动版本为10.2

运行nvcc --version,查看当前安装的cuda版本为10.0
步骤三:
下载ubuntu下的Anaconda安装文件,然后在镜像中进行安装:
bash Anaconda3-2020.11-Linux-x86_64.sh
【注意】:在对镜像文件进行修改时,应及时commit镜像的更新。
安装完Anaconda之后,需要先退出当前的镜像终端(不用关闭镜像),然后再重新进入。这样Anaconda才能生效。在终端运行conda list来确认是否安装成功。
步骤四:
参考CenterTrack/readme/INSTALL.md中的【步骤0】完成python环境的配置。

步骤五:
安装pytorch。这个一步需要特别注意版本的问题。我最开始按照作者给出的conda install pytorch torchvision -c pytorch 这个命令安装就出现了一系列的问题,因为这个conda命令默认安装出来的是cpu版本的pytorch。后来在排查问题的时候在git issue中找到了答案,参考link。
如果安装的pytorch版本有问题,就会出现这样的错误提示。
No module named 'torchvision.models.utils
另外在参考了git issue上关于pytorch版本相关的话题之后,我最后选择安装pytorch 1.4.0,torchvision 0.5.0这个版本。
pip install torch==1.4.0+cu100 torchvision==0.5.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html
安装完pytorch之后可以运行python,并查看一下所安装的pytorch版本对不对。
进入python,输入如下命令:
import torch
print(torch.__version__)
步骤六:
完成pytorch的安装之后就可以进行作者给出的【步骤2】~【步骤6】的复现了。这里需要注意的是,在install the requirements 这一步需要先打开工程里的requirements.txt这个文件,注释掉nuscenes-devkit这个库的安装,这个库会将pytorch更新到最新的版本(好像是1.7.0)。

如果采用的镜像跟我的一致,那还会遇到以下一些镜像环境问题:
(1)镜像中没有安装pip
在镜像中运行:
apt-get update
apt-get install pip
(2)找不到libGL.so.1

参考这个链接link进行安装。
(3)找不到Libgthread-2.0.so.0

参考这个链接link进行安装。
步骤七:
这一步主要是解决运行工程时不能显示图片的问题。
(1) 因为我的服务器没有外接显示,且ssh 登录用-X也没搞定,运行demo的时候会报如下的错误。

最后决定采用作者提供的--save_video来将demo的推理结果存到视频文件中。需要先修改工程中与cv2.imshow和cv2.waitKey相关的代码。需要修改demo.py和lib/utils/debugger.py这两个文件中的代码,参考下面的git diff信息。


该问题可以参考这两个链接:
git issue 1: link
git issue 2: link
(2)采用--save_video之后发现,没有在results文件夹下生成视频文件。这是因为pip安装的opencv不支持H264格式的视频输出(版权问题link)。截图中可以看到报了”codec id 27: Encoder not found“ 的错误,但是不影响工程的运行。
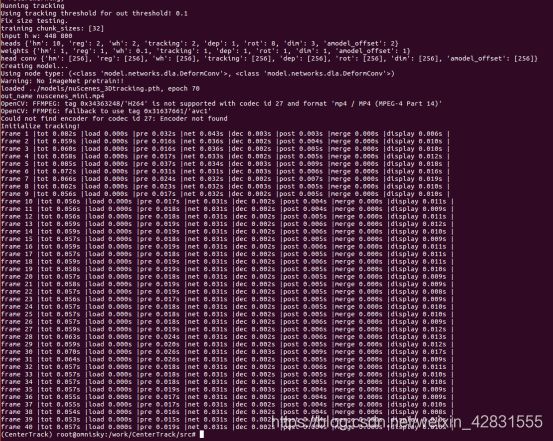
因此,还需要对demo.py文件做一个小修改,直接保存单张图片,绕过写视频这个问题。git diff信息如下。

最后惯例贴个图:
运行Demo:
python demo.py tracking,ddd --load_model ../models/nuScenes_3Dtracking.pth --dataset nuscenes --pre_hm --track_thresh 0.1 --demo ../videos/nuscenes_mini.mp4 --test_focal_length 633 --save_video --video_h 448 --video_w 800

至此,demo算是跑起来了。我尝试去在自己的图像数据上跑demo的模型,发现推理出来的检测跟踪框跟图片中实际的目标位置差的有点远。问题还在排查中。