visdrone+yolov5
1.数据集转换
VisDrone2019-DET-train
下载地址
http://aiskyeye.com/download/object-detection/
解压后只有images、annotations两个文件夹
使用数据集转换工具visdrone2yolo.py
只要修改
root_dir就可以直接运行。运行前先装一下pip包。如果没有labels文件夹生成就手动新建个labels文件夹,在root_dir下。
import os
from os import getcwd
from PIL import Image
import xml.etree.ElementTree as ET
import random
#root_dir = "train/"
root_dir = "/home/lhw/Gradute/VirDrone/yolov5/VisDrone2019-DET-train/"
annotations_dir = root_dir+"annotations/"
image_dir = root_dir + "images/"
label_dir = root_dir + "labels/"
# label_dir = root_dir + "images/" # yolo里面要和图片放到一起
xml_dir = root_dir+"annotations_voc/" #注意新建文件夹。后续改一下名字,运行完成之后annotations这个文件夹就不需要了。把annotations_命名为annotations
data_split_dir = root_dir + "train_namelist/"
sets = ['train', 'test','val']
class_name = ['ignored regions', 'pedestrian','people','bicycle','car', 'van', 'truck', 'tricycle','awning-tricycle', 'bus','motor','others']
def visdrone2voc(annotations_dir, image_dir, xml_dir):
for filename in os.listdir(annotations_dir):
fin = open(annotations_dir + filename, 'r')
image_name = filename.split('.')[0]
img = Image.open(image_dir + image_name + ".jpg")
xml_name = xml_dir + image_name + '.xml'
with open(xml_name, 'w') as fout:
fout.write('' + '\n')
fout.write('\t' + 'VOC2007 ' + '\n')
fout.write('\t' + '' + image_name + '.jpg' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t\t' + '' + 'VisDrone2018 Database' + '' + '\n')
fout.write('\t\t' + '' + 'VisDrone2018' + '' + '\n')
fout.write('\t\t' + '' + 'flickr' + '' + '\n')
fout.write('\t\t' + '' + 'Unspecified' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t\t' + '' + 'Haipeng Zhang' + '' + '\n')
fout.write('\t\t' + '' + 'Haipeng Zhang' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t\t' + '' + str(img.size[0]) + '' + '\n')
fout.write('\t\t' + '' + str(img.size[1]) + '' + '\n')
fout.write('\t\t' + '' + '3' + '' + '\n')
fout.write('\t' + '' + '\n')
fout.write('\t' + '' + '0' + '' + '\n')
for line in fin.readlines():
line = line.split(',')
fout.write('\t' + ' + '\n')
fout.write('\t\t' + '' + class_name[int(line[5])] + '' + '\n')
fout.write('\t\t' + '' + 'Unspecified' + '' + '\n')
fout.write('\t\t' + '' + line[6] + '' + '\n')
fout.write('\t\t' + '' + str(int(line[7])) + '' + '\n')
fout.write('\t\t' + '' + '\n')
fout.write('\t\t\t' + '' + line[0] + '' + '\n')
fout.write('\t\t\t' + '' + line[1] + '' + '\n')
# pay attention to this point!(0-based)
fout.write('\t\t\t' + '' + str(int(line[0]) + int(line[2]) - 1) + '' + '\n')
fout.write('\t\t\t' + '' + str(int(line[1]) + int(line[3]) - 1) + '' + '\n')
fout.write('\t\t' + '' + '\n')
fout.write('\t' + '' + '\n')
fin.close()
fout.write('')
def data_split(xml_dir, data_split_dir):
trainval_percent = 0.2
train_percent = 0.9
total_xml = os.listdir(xml_dir)
if not os.path.exists(data_split_dir):
os.makedirs(data_split_dir)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(data_split_dir+'/trainval.txt', 'w')
ftest = open(data_split_dir+'/test.txt', 'w')
ftrain = open(data_split_dir+'/train.txt', 'w')
fval = open(data_split_dir+'/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation_voc(xml_dir, label_dir, image_name):
in_file = open(xml_dir + '%s.xml' % (image_name))
out_file = open(label_dir + '%s.txt' % (image_name), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in class_name or int(difficult) == 1:
continue
cls_id = class_name.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
if cls_id != 0: # 忽略掉0类
if cls_id != 11: # 忽略掉11类
out_file.write(str(cls_id - 1) + " " + " ".join([str(a) for a in bb]) + '\n') # 其他类id-1。可以根据自己需要修改代码
def voc2yolo(xml_dir, image_dir, label_dir):
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists(label_dir):
os.makedirs(label_dir)
image_names = open(data_split_dir+'%s.txt' % (image_set)).read().strip().split()
list_file = open(root_dir + '%s.txt' % (image_set), 'w')
for image_name in image_names:
list_file.write(image_dir+'%s.jpg\n' % (image_name))
convert_annotation_voc(xml_dir, label_dir, image_name)
list_file.close()
if __name__ == '__main__':
visdrone2voc(annotations_dir, image_dir, xml_dir) #将visdrone转化为voc的xml格式
data_split(xml_dir, data_split_dir) # 将数据集分开成train、val、test
voc2yolo(xml_dir, image_dir, label_dir) # 将voc转化为yolo格式的txt
- 下载yolov5源码
git clone https://github.com/ultralytics/yolov5.git
然后在git下的yolov5根目录下创建文件夹visdronedata及其附属目录

将visdrone的images文件夹里面的图片全部复制到images/train和iamges/val里面,上面程序生成的labels文件夹,将里面的所有txt复制到labels/train和labels/val里面
然后安装yolov5环境,要在Python3.8的环境下安装,如果使用conda可以使用
conda create -n py38 python=3.8 # 创建虚拟环境
conda activate py38 # 激活虚拟环境,如果成功激活环境则在命令行用户名前面有虚拟环境名称的括号
pip install -r requirements.txt # 在yolov5根目录下安装需要的包
安装完环境之后,修改data/voc.yaml
# download command/URL (optional)
# download: bash data/scripts/get_voc.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: visdronedata/images/train/ # 16551 images
val: visdronedata/images/train/ # 4952 images
# number of classes
nc: 10
# class names
names: ['pedestrian','people','bicycle','car','van','truck','tricycle','awning-tricycle','bus','motor']
修改models/yolov5l.yaml
# parameters
nc: 10 # number of classes #只修改这个类别数
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
在这里的v1部分下载预训练模型yolov5l.pt,由于使用的yolov5l.yaml,所以使用yolov5l.pt。使用其他的训练配置文件可以下载相应的预训练模型,在github有对应关系。
将下载好的预训练模型放到weights文件夹下
然后在命令段运行
内存足够时可以增大
batch-size:1、8、16、32、64
python train.py --data data/voc.yaml --cfg models/yolov5l.yaml --weights weights/yolov5l.pt --batch-size 1
也可直接在train.py直接修改默认参数,然后直接运行
python train.py

然后进行训练,在训练的过程中会产生过程文件及训练模型,会保存在runs/文件夹中

在exp里面会有保存的中间临时权重,可以拿出来放到yolov5/根目录下进行预测测试,预测的结果也会放到runs/detect文件夹下
python decect.py --source file.jpg --weight best.pt --conf 0.25
python decect.py --source file.mp4 --weight best.pt --conf 0.25
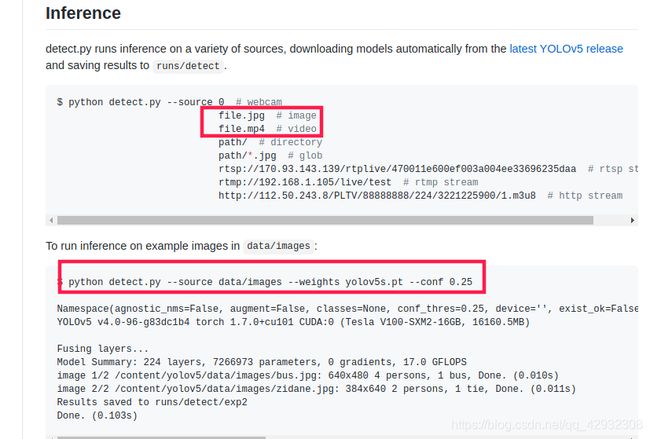
运行十来分钟就拿来测试了。。。

