【笔记】transformer
一.前置知识
1.什么是注意力机制
【参考知乎】一文读懂注意力机制
1)原理是什么?怎么实现?
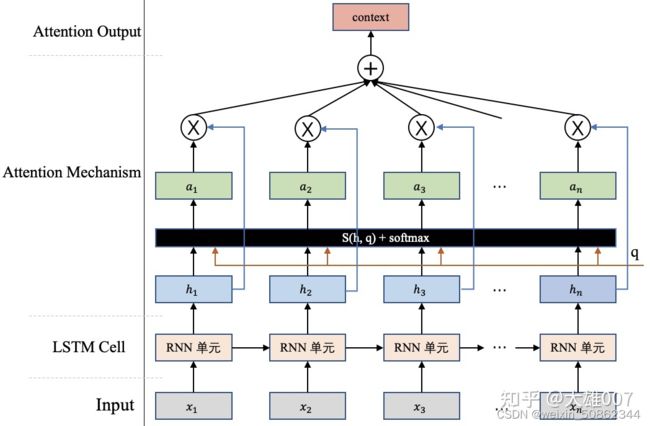
step:
(1)通过打分函数计算查询向量q和输入h的相关性
(2)softmax归一化获得注意力分布
【注意】此时的输入h仍然为一个标量,而在 键值对注意力机制(以及 多头注意力机制中)都是使用键值对
详细如下图:

更多细节参考一文读懂注意力机制
2)查询向量q如何获得?
- 在查询向量q往往和任务相关,比如基于Seq-to-Seq的机器翻译任务中,这个查询向量 q 可以是Decoder端前个时刻的输出状态向量
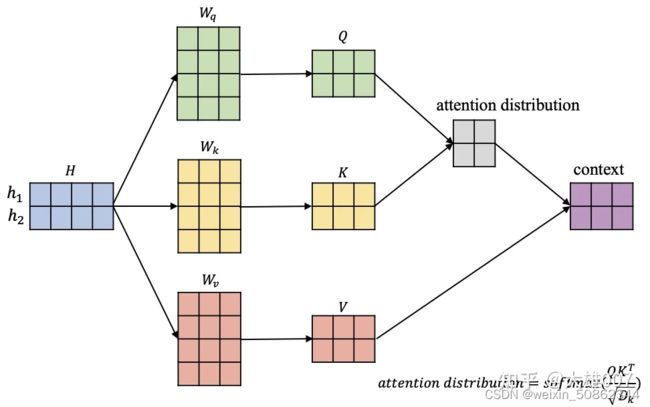
- 然而在自注意力机制(self-Attention)中,这里的查询向量q也可以使用输入信息进行生成。输入信息h,通过三个矩阵W 映射到对应的 查询空间Q,键空间K,值空间V
2.什么是transformer架构?和普通的encoder-decoder架构有什么区别?
transformer其实也属于encoder-decoder架构。transformer不同的是完全基于注意力机制,完全不使用循环和卷积。
二. transformer
1.来自两个任意输入或输出位置的信号的关联 所需的操作数量 被减少为一个常数数量的操作,尽管代价是由于平均注意力加权位置而降低了有效分辨率,我们用Multi-Head Attention抵消了这一影响
1.架构

1.1encoder
第一层是一个多头的自注意力机制,第二层是一个简单的、位置上的全连接前馈网络。我们在两个子层中采用一个残差连接,然后进行层归一化
1.2decoder
除了每个编码器层的两个子层之外,解码器还插入了第三个子层,它对编码器堆栈的输出进行多头注意力。与编码器类似,我们在每个子层周围采用残差连接然后进行层归一化。我们还修改了解码器堆栈中的自注意力子层,以防止位置关注后续位置。
1.3 多头自注意力机制
【代码】github传送门
多头注意力实现代码:
"""
---
title: Multi-Headed Attention (MHA)
"""
import math
from typing import Optional, List
import torch
from torch import nn
from labml import tracker
class PrepareForMultiHeadAttention(nn.Module):
"""
## Prepare for multi-head attention
This module does a linear transformation and splits the vector into given
number of heads for multi-head attention.
This is used to transform **key**, **query**, and **value** vectors.
"""
def __init__(self, d_model: int, heads: int, d_k: int, bias: bool):
super().__init__()
# Linear layer for linear transform
self.linear = nn.Linear(d_model, heads * d_k, bias=bias)
# Number of heads
self.heads = heads
# Number of dimensions in vectors in each head
self.d_k = d_k
def forward(self, x: torch.Tensor):
# Input has shape `[seq_len, batch_size, d_model]` or `[batch_size, d_model]`.
# We apply the linear transformation to the last dimension and split that into
# the heads.
head_shape = x.shape[:-1]
# Linear transform
x = self.linear(x)
# Split last dimension into heads
x = x.view(*head_shape, self.heads, self.d_k)
# Output has shape `[seq_len, batch_size, heads, d_k]` or `[batch_size, heads, d_model]`
return x
class MultiHeadAttention(nn.Module):
r"""
## Multi-Head Attention Module
This computes scaled multi-headed attention for given `query`, `key` and `value` vectors.
$$\mathop{Attention}(Q, K, V) = \underset{seq}{\mathop{softmax}}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)V$$
In simple terms, it finds keys that matches the query, and gets the values of
those keys.
It uses dot-product of query and key as the indicator of how matching they are.
Before taking the $softmax$ the dot-products are scaled by $\frac{1}{\sqrt{d_k}}$.
This is done to avoid large dot-product values causing softmax to
give very small gradients when $d_k$ is large.
Softmax is calculated along the axis of of the sequence (or time).
"""
def __init__(self, heads: int, d_model: int, dropout_prob: float = 0.1, bias: bool = True):
"""
* `heads` is the number of heads.
* `d_model` is the number of features in the `query`, `key` and `value` vectors.
"""
super().__init__()
# Number of features per head
self.d_k = d_model // heads
# Number of heads
self.heads = heads
# These transform the `query`, `key` and `value` vectors for multi-headed attention.
self.query = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=bias)
self.key = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=bias)
self.value = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=True)
# Softmax for attention along the time dimension of `key`
self.softmax = nn.Softmax(dim=1)
# Output layer
self.output = nn.Linear(d_model, d_model)
# Dropout
self.dropout = nn.Dropout(dropout_prob)
# Scaling factor before the softmax
self.scale = 1 / math.sqrt(self.d_k)
# We store attentions so that it can be used for logging, or other computations if needed
self.attn = None
def get_scores(self, query: torch.Tensor, key: torch.Tensor):
"""
### Calculate scores between queries and keys
This method can be overridden for other variations like relative attention.
"""
# Calculate $Q K^\top$ or $S_{ijbh} = \sum_d Q_{ibhd} K_{jbhd}$
return torch.einsum('ibhd,jbhd->ijbh', query, key)
def prepare_mask(self, mask: torch.Tensor, query_shape: List[int], key_shape: List[int]):
"""
`mask` has shape `[seq_len_q, seq_len_k, batch_size]`, where first dimension is the query dimension.
If the query dimension is equal to $1$ it will be broadcasted.
"""
assert mask.shape[0] == 1 or mask.shape[0] == query_shape[0]
assert mask.shape[1] == key_shape[0]
assert mask.shape[2] == 1 or mask.shape[2] == query_shape[1]
# Same mask applied to all heads.
mask = mask.unsqueeze(-1)
# resulting mask has shape `[seq_len_q, seq_len_k, batch_size, heads]`
return mask
def forward(self, *,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[torch.Tensor] = None):
"""
`query`, `key` and `value` are the tensors that store
collection of *query*, *key* and *value* vectors.
They have shape `[seq_len, batch_size, d_model]`.
`mask` has shape `[seq_len, seq_len, batch_size]` and
`mask[i, j, b]` indicates whether for batch `b`,
query at position `i` has access to key-value at position `j`.
"""
# `query`, `key` and `value` have shape `[seq_len, batch_size, d_model]`
seq_len, batch_size, _ = query.shape
if mask is not None:
mask = self.prepare_mask(mask, query.shape, key.shape)
# Prepare `query`, `key` and `value` for attention computation.
# These will then have shape `[seq_len, batch_size, heads, d_k]`.
query = self.query(query)
key = self.key(key)
value = self.value(value)
# Compute attention scores $Q K^\top$.
# This gives a tensor of shape `[seq_len, seq_len, batch_size, heads]`.
scores = self.get_scores(query, key)
# Scale scores $\frac{Q K^\top}{\sqrt{d_k}}$
scores *= self.scale
# Apply mask
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# $softmax$ attention along the key sequence dimension
# $\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)$
attn = self.softmax(scores)
# Save attentions if debugging
tracker.debug('attn', attn)
# Apply dropout
attn = self.dropout(attn)
# Multiply by values
# $$\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)V$$
x = torch.einsum("ijbh,jbhd->ibhd", attn, value)
# Save attentions for any other calculations
self.attn = attn.detach()
# Concatenate multiple heads
x = x.reshape(seq_len, batch_size, -1)
# Output layer
return self.output(x)
2.整体代码
【pytorch版本】transformer
"""
---
title: Transformer Encoder and Decoder Models
summary: >
These are PyTorch implementations of Transformer based encoder and decoder models,
as well as other related modules.
---
# Transformer Encoder and Decoder Models
[](https://colab.research.google.com/github/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/transformers/basic/autoregressive_experiment.ipynb)
"""
import math
import torch
import torch.nn as nn
from labml_nn.utils import clone_module_list
from .feed_forward import FeedForward
from .mha import MultiHeadAttention
from .positional_encoding import get_positional_encoding
class EmbeddingsWithPositionalEncoding(nn.Module):
"""
## Embed tokens and add [fixed positional encoding](positional_encoding.html)
"""
def __init__(self, d_model: int, n_vocab: int, max_len: int = 5000):
super().__init__()
self.linear = nn.Embedding(n_vocab, d_model)
self.d_model = d_model
self.register_buffer('positional_encodings', get_positional_encoding(d_model, max_len))
def forward(self, x: torch.Tensor):
pe = self.positional_encodings[:x.shape[0]].requires_grad_(False)
return self.linear(x) * math.sqrt(self.d_model) + pe
class EmbeddingsWithLearnedPositionalEncoding(nn.Module):
"""
## Embed tokens and add parameterized positional encodings
"""
def __init__(self, d_model: int, n_vocab: int, max_len: int = 5000):
super().__init__()
self.linear = nn.Embedding(n_vocab, d_model)
self.d_model = d_model
self.positional_encodings = nn.Parameter(torch.zeros(max_len, 1, d_model), requires_grad=True)
def forward(self, x: torch.Tensor):
pe = self.positional_encodings[:x.shape[0]]
return self.linear(x) * math.sqrt(self.d_model) + pe
class TransformerLayer(nn.Module):
"""
## Transformer Layer
This can act as an encoder layer or a decoder layer.
Some implementations, including the paper seem to have differences
in where the layer-normalization is done.
Here we do a layer normalization before attention and feed-forward networks,
and add the original residual vectors.
Alternative is to do a layer normalization after adding the residuals.
But we found this to be less stable when training.
We found a detailed discussion about this in the paper
[On Layer Normalization in the Transformer Architecture](https://papers.labml.ai/paper/2002.04745).
"""
def __init__(self, *,
d_model: int,
self_attn: MultiHeadAttention,
src_attn: MultiHeadAttention = None,
feed_forward: FeedForward,
dropout_prob: float):
"""
* `d_model` is the token embedding size
* `self_attn` is the self attention module
* `src_attn` is the source attention module (when this is used in a decoder)
* `feed_forward` is the feed forward module
* `dropout_prob` is the probability of dropping out after self attention and FFN
"""
super().__init__()
self.size = d_model
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.dropout = nn.Dropout(dropout_prob)
self.norm_self_attn = nn.LayerNorm([d_model])
if self.src_attn is not None:
self.norm_src_attn = nn.LayerNorm([d_model])
self.norm_ff = nn.LayerNorm([d_model])
# Whether to save input to the feed forward layer
self.is_save_ff_input = False
def forward(self, *,
x: torch.Tensor,
mask: torch.Tensor,
src: torch.Tensor = None,
src_mask: torch.Tensor = None):
# Normalize the vectors before doing self attention
z = self.norm_self_attn(x)
# Run through self attention, i.e. keys and values are from self
self_attn = self.self_attn(query=z, key=z, value=z, mask=mask)
# Add the self attention results
x = x + self.dropout(self_attn)
# If a source is provided, get results from attention to source.
# This is when you have a decoder layer that pays attention to
# encoder outputs
if src is not None:
# Normalize vectors
z = self.norm_src_attn(x)
# Attention to source. i.e. keys and values are from source
attn_src = self.src_attn(query=z, key=src, value=src, mask=src_mask)
# Add the source attention results
x = x + self.dropout(attn_src)
# Normalize for feed-forward
z = self.norm_ff(x)
# Save the input to the feed forward layer if specified
if self.is_save_ff_input:
self.ff_input = z.clone()
# Pass through the feed-forward network
ff = self.feed_forward(z)
# Add the feed-forward results back
x = x + self.dropout(ff)
return x
class Encoder(nn.Module):
"""
## Transformer Encoder
"""
def __init__(self, layer: TransformerLayer, n_layers: int):
super().__init__()
# Make copies of the transformer layer
self.layers = clone_module_list(layer, n_layers)
# Final normalization layer
self.norm = nn.LayerNorm([layer.size])
def forward(self, x: torch.Tensor, mask: torch.Tensor):
# Run through each transformer layer
for layer in self.layers:
x = layer(x=x, mask=mask)
# Finally, normalize the vectors
return self.norm(x)
class Decoder(nn.Module):
"""
## Transformer Decoder
"""
def __init__(self, layer: TransformerLayer, n_layers: int):
super().__init__()
# Make copies of the transformer layer
self.layers = clone_module_list(layer, n_layers)
# Final normalization layer
self.norm = nn.LayerNorm([layer.size])
def forward(self, x: torch.Tensor, memory: torch.Tensor, src_mask: torch.Tensor, tgt_mask: torch.Tensor):
# Run through each transformer layer
for layer in self.layers:
x = layer(x=x, mask=tgt_mask, src=memory, src_mask=src_mask)
# Finally, normalize the vectors
return self.norm(x)
class Generator(nn.Module):
"""
## Generator
This predicts the tokens and gives the lof softmax of those.
You don't need this if you are using `nn.CrossEntropyLoss`.
"""
def __init__(self, n_vocab: int, d_model: int):
super().__init__()
self.projection = nn.Linear(d_model, n_vocab)
def forward(self, x):
return self.projection(x)
class EncoderDecoder(nn.Module):
"""
## Combined Encoder-Decoder
"""
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: nn.Module, tgt_embed: nn.Module, generator: nn.Module):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src: torch.Tensor, tgt: torch.Tensor, src_mask: torch.Tensor, tgt_mask: torch.Tensor):
# Run the source through encoder
enc = self.encode(src, src_mask)
# Run encodings and targets through decoder
return self.decode(enc, src_mask, tgt, tgt_mask)
def encode(self, src: torch.Tensor, src_mask: torch.Tensor):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory: torch.Tensor, src_mask: torch.Tensor, tgt: torch.Tensor, tgt_mask: torch.Tensor):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)