数据分析与挖掘中常用Python库的介绍与实践案例
数据分析与挖掘中常用Python库的介绍与实践案例
一、Python介绍
现在python一词对我们来说并不陌生,尤其是在学术圈,它的影响力远超其它任何一种编程语言, 作为一门简单易学且功能强大的编程语言,它拥有丰富的第三方库,在许多方面都有着广泛的应用,如网站开发、游戏开发、网络爬虫、数据分析、机器学习等。 (更多内容,可参阅程序员在旅途)
在数据分析方面,python拥有Numpy、SciPy、Pandas、Matplotlib等功能强大的模块可供使用。随着这些模块的逐步完善,python在科学领域的地位越来越重要,这其中包括科学计算、数学建模、数据挖掘等。因此,掌握这些模块的基本使用方法至关重要,下面就逐一介绍下。
二、常用库的使用示例
2.1 NumPy 库:
NumPy(官网)提供了N维数组功能以及对数据进行快速处理的能力,弥补了Python本身没有提供数组功能的缺陷。其提供了两种基本的对象:ndarray和ufunc。ndarray是存储单一数据类型的多维数组,而ufunc是能够对数组进行处理的函数(ufunc(通用函数)是一种对ndarray中的数据执行元素级运算的函数)。它也是SciPy、Pandas、Matplotlib的基础依赖库。
ndarray:N维数组对象(矩阵),所有元素数据类型必须是相同的。
ndarray属性:ndim属性,表示维度的个数;shape属性,表示各维度得大小;dtype属性,表示数据类型。
创建ndarray数组的函数如下图:

代码示例:
import numpy as np
# 一维数组示例
a = np.array([3, 2, 1, 6, 5])
print('数组a: ', a) # 数组a: [3 2 1 6 5]
print(a[:3]) # [3 2 1]
print(a[2:]) # [1 6 5]
print('ufunc函数使用示例,求平方: ', np.square(a)) # ufunc函数使用示例,求平方: [ 9 4 1 36 25]
a.sort()
print('排序之后的数组a: ', a) # 排序之后的数组a: [1 2 3 5 6]
# 二维数组示例
b = np.array([[1, 2, 3], [6, 7, 8], [10, 11, 12]])
print('\n 二维数组b: ', b) # 二维数组b: [[ 1 2 3] [ 6 7 8] [10 11 12]]
print('矢量运算结果(所有元素 * 2): \n', 2 * b) # 矢量运算结果(所有元素 * 2): [[ 2 4 6] [12 14 16] [20 22 24]]
print(b.dtype) # int32
# arange([start,] stop[, step,], dtype=None) 四个参数,其中start,step,dtype可以省略,分别是起始点、步长、和返回类型。
c = np.arange(5) # 起始点0,结束点5,步长1,返回类型array,一维
print('\narrange函数生成的数组:', c) # arrange函数生成的数组: [0 1 2 3 4]
# zeros函数
d = np.zeros(5, dtype='int8')
print('zero函数生成的数组: ', d) # zero函数生成的数组: [0 0 0 0 0] 2.2 SciPy 库:
SciPy(官网)依赖于NumPy,其提供了矩阵支持以及大量基于矩阵运算的对象和函数。SciPy包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学和工程中常用的计算,这些功能是科学工程领域建模和数据挖掘中必须具备的。
| 模块名称 | scipy.integrate | scipy.linalg | scipy.optimize | scipy.signal | scipy.sparse | scipy.stats | scipy.weave | scipy.special |
| 应用说明 | 数值积分例程和微分方程求解器 | 扩展了由 numpy.linalg 提供的线性代数例程和矩阵分解功能 | 函数优化器(最小化器)以及根查找算法 | 信号处理工具 | 稀疏矩阵和稀疏线性系统求解器 | 检验连续和离散概率分布、各种统计检验方法,以及更好的描述统计法 | 利用内联 C++代码加速数组计算的工具 | SPECFUN(这是一个实现了许多常用数学函数的 Fortran 库)的包装器 |
代码示例:
import numpy as np
from scipy import integrate
from scipy.optimize import fsolve
# 求解积分
def f(x):
return x
val, abserr = integrate.quad(f, 0, 1) # 积分结果和误差
print(val, abserr) # 0.5 5.551115123125783e-15
# 求解方程组 2x1 - x^2 = 1, x1^2 -x2 = 2
def g(x):
x1 = x[0]
x2 = x[1]
return np.array([2 * x1 - x2 ** 2 - 1, x1 ** 2 - x2 - 2])
result = fsolve(g, [1, 1]) # 输入初始值,并进行求解
print(result) # [1.91963957 1.68501606]
2.3 Pandas 库:
Pandas(官网)是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。pandas最初作为金融分析工具被开发,2008年问世,2009年底开源。
Pandas的基本数据结构是Series和DataFrame,Series是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
2.3.1 Series和DataFrame对象的创建,元素的选取:
import pandas as pd
from pandas import Series, DataFrame
a = pd.Series([1, 2, 3, 4]) # 默认的索引
b = Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) # 显示的添加index
print('Series A : \n', a)
print('Series B : \n', b)
c = pd.DataFrame({'categorical': pd.Categorical(['d', 'e', 'f', 'm']), 'test': [4, 6, 9, 3], 'numeric': [1, 2, 3, 6],
'object': ['a', 'b', 'c', 'd']})
print('输出C:\n', c)
print('简要统计结果: \n', c.describe()) # 统计结果
print('输出前两行:\n', c.head(2)) # 输出前两行
print('C 的转置:\n', c.T) # C 的转置
print('输出 2-3行:\n', c[2:4]) # 输出2-3行
print('loc,选取 categorical、test 这两列的前三行行数据: \n', c.loc[:2, ('categorical', 'test')])
print('iloc,选择某行某列的值:\n', c.iloc[2,2]) # iloc[]方法的参数,必须是数值。
print('iloc,选择前两行,前两列的数据:\n', c.iloc[:2, 0:2])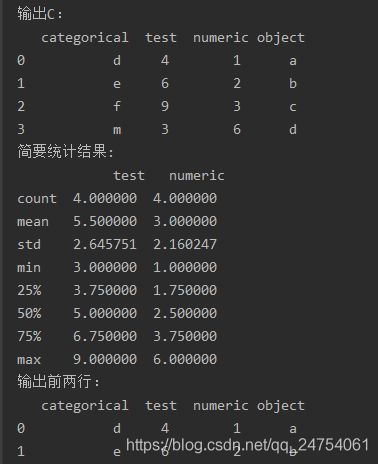

2.3.2 Pandas处理文件读写:
# pandas处理文件读写非常的简单
pd.read_csv('C:\\Users\\itour\\Desktop\\credit_card.csv', encoding='utf-8')
pd.to_csv('C:\\Users\\itour\\Desktop\\credit_card.csv', encoding='utf-8')
pd.read_excel('C:\\Users\\itour\\Desktop\\credit_card.xlsx','Sheet1')
pd.to_excel('C:\\Users\\itour\\Desktop\\credit_card.xlsx',sheet_name='Sheet1') 2.4 Matplotlib 库:
不管是数据挖掘还是数学建模,最终结果的可视化展示都是需要面对的一个问题,Matplotlib(官网)是Python中最为成熟的绘图库,主要用于绘制2D图形,可以很方便的绘制直方图、散点图、条形图、饼状图、折线图等等。同时,还可以绘制一些界面可交互的图形。
首先绘图需要导入matplotlib.pyplot,其中pyplot是matplotlib的绘图框架。
代码示例如下(要注意中文的显示问题):
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
x = np.linspace(0, 2 * np.pi, 50)
y = np.sin(x)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
plt.figure(figsize=(8,4))
plt.plot(x, y, 'bp--')
plt.xlabel('自变量x') # x轴标签
plt.ylabel('sin(x)') # y轴标签
plt.title('y = sin(x) x∈[0,2*pi]') # 标题
plt.legend() #图例
plt.show() #显示图像
2.5 scikit-learn 库:
scikit-learn是Python下强大的机器学习包,提供了完善的机器学习工具集,包括有数据预处理、分类、回归、聚类、预测、模型分析等。训练模型的具体方法,会在后面的博客中陆续的写出来。
三、总结
以上几个库,是提升Python作为数据分析生产力工具的基础,因此,如果想用Python做这类工作,这些库是必须要熟练掌握的。
用Python进行数据分析,得益于这些扩展包的存在,实现起来高效便捷。有时候一些科研人员并不是专门从事编程领域工作的,如果为了实现某一个数据分析任务,需要专门学习一种语言,那Python是当之无愧的首选,真的很简单的一门编程语言,上手容易,语法灵活,不用关注太多语法细节,只需要专心科研任务本身即可。虽然其他的编程语言也可以实现相同的功能,但是操作起来较为复杂,会花费很多不必要的精力在非核心工作上面。