【Python学习003】高效数据结构-列表
【Python学习003】高效数据结构-列表
我们的公众号是【朝阳三只大明白】,满满全是干货,分享近期的学习知识以及个人总结(包括读研和IT),希望大家一起努力,一起加油!求关注!!
简介
【列表 (List) 】是 Python 中最基本的数据类型之一,列表中的每个元素均会分配一个数字,用以记录位置,我们称之为 索引 ,索引值从 0 开始,依次往后计数。
列表使用中括号【[]】包裹,元素之间使用逗号【,】 分隔,其元素可以是数字、字符串、列表等其他任何数据类型。
列表同样支持索引、更新、删除、嵌套、拼接、成员检查、截取、追加、扩展、排序等相关操作。
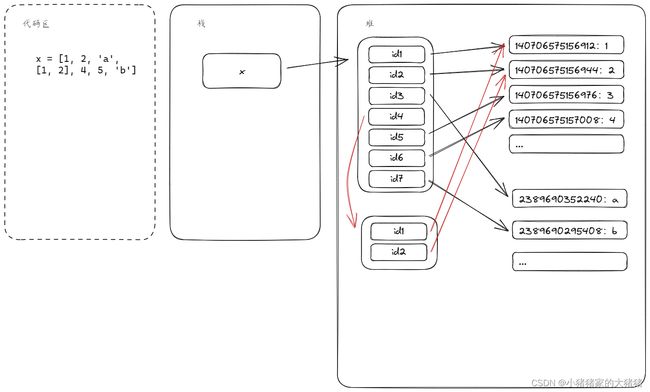
列表的每一个元素实质上存储的是一个指针,而不是数据本身。以下面一段做示例:
# 创建一个列表
x = [1, 2, 'a', [1, 2], 3, 4, 'b']
N = len(x)
for i in range(N):
print(id(x[i]))
print(id(x[3][0]))
print(id(x[3][1]))
----------------- 第一次运行 ---------------------
140706575156912
140706575156944
2389690352240
# 2389798127680
140706575156976
140706575157008
2389690295408
140706575156912
140706575156944
----------------- 第二次运行 ---------------------
140706575156912
140706575156944
2389690352240
# 2389798169600
140706575156976
140706575157008
2389690295408
140706575156912
140706575156944
由上面的示例可以看出针对数字、常见字符串,在Python启动的时候就已经分配好内存了,示例中的x,它在内存中的分布如下:
列表常见操作
常见列表操作
添加元素
append(self, __object: _T) -> None
append方法在列表末尾添加一个元素,相当于a[len(a):] = [x],示例如下:
nums = [1, 2, 3]
nums.append(4)
nums -> [1, 2, 3, 4]
扩展列表
extend(self, __iterable: Iterable[_T]) -> None
extend方法用可迭代对象的元素扩展列表。调用该方法相当于a[len(a):] = iterable,具体示例如下:
nums = [1, 2, 3]
nums_extend = [4, 5, 6]
nums.extend(nums_extend)
nums -> [1, 2, 3, 4, 5, 6]
插入元素
insert(self, __index: SupportsIndex, __object: _T) -> None
insert方法用来在指定位置插入元素。第一个参数是插入元素的索引,因此,a.insert(0, x) 在列表开头插入元素, a.insert(len(a), x) 等同于 a.append(x) ,具体示例如下:
nums = [1, 2, 3]
nums.insert(0, 5)
nums -> [5, 1, 2, 3]
按元素值删除
remove(self, __value: _T) -> None
remove方法用来从从列表中删除第一个值为 x 的元素。未找到指定元素时,触发 ValueError 异常,示例如下:
x = [1, 2, 3, 1]
x.remove(1)
x -> [2, 3, 1]
调用该方法会从左向右寻找相等的元素,底层是调用传入对象的__eq__方法对列表中的所有对象进行比较,如果该方法返回True,则会删除该元素,示例如下:
class TestClass:
def __init__(self, name: str, age: int):
self.name = name
self.age = age
def __eq__(self, other):
print(f"{self}调用eq方法")
return self.name == other.name and self.age == other.age
def __str__(self):
return f"name:{self.name}, age:{self.age} "\
a1 = TestClass("a", 1)
a2 = TestClass("b", 2)
x = [a1, a2]
a3 = TestClass("b", 2)
x.remove(a3)
x
------------------------------
name:a, age:1 调用eq方法
name:b, age:2 调用eq方法
[<__main__.TestClass at 0x2dce1df8b80>]
当使用remove方法删除元素的时候需要注意当一个列表包含多个类型的元素的时候很容易出错,传入对象的__eq__方法写的不好会产生很多问题,具体示例如下:
a1 = TestClass("a", 1)
a2 = TestClass("b", 2)
x = [1, a1, a2]
a3 = TestClass("b", 2)
x.remove(a3)
x -> AttributeError: 'int' object has no attribute 'name'
按位置进行删除
pop(self, __index: SupportsIndex = ...) -> _T
调用pop方法删除列表中指定位置的元素,并返回被删除的元素。未指定位置时,a.pop() 删除并返回列表的最后一个元素,具体示例如下:
x = [1, 2, 3]
x.pop()
x -> [1, 2]
x = [1, 2, 3]
x.pop(0)
x -> [2, 3]
清除列表元素
clear(self) -> None
调用clear方法会删除列表里的所有元素,相当于 del a[:] ,具体示例如下:
x = [1, 2, 3]
x.clear()
x -> []
按索引返回元素
index(self, __value: _T, __start: SupportsIndex = ..., __stop: SupportsIndex = ...) -> int
调用index方法返回列表中第一个值为 x 的元素的零基索引。未找到指定元素时,触发 ValueError 异常。
可选参数 start 和 end 是切片符号,用于将搜索限制为列表的特定子序列。返回的索引是相对于整个序列的开始计算的,而不是基于start 参数,具体示例如下:
x = [1, 2, 3]
x.index(2) -> 1
统计元素出现次数
count(self, __value: _T) -> int
调用count方法会返回列表中元素 x 出现的次数,具体示例如下:
x = [1, 2, 3, 1]
x.count(1) -> 2
元素原地排序
sort(self, *, key: Callable[[_T], SupportsRichComparison], reverse: bool = ...) -> None
调用sort方法就地排序列表中的元素,具体示例如下:
x = [1, 2, 3, 1]
x.sort(reverse=True)
x -> [3, 2, 1, 1]
翻转列表元素
reverse(self) -> None
调用reverse方法会翻转列表中的元素,具体示例如下:
x = [1, 2, 3]
x.reverse()
x -> [3, 2, 1]
浅拷贝
copy(self) -> list[_T]
调用copy方法返回列表的浅拷贝,相当于 a[:] ,关于浅拷贝和深拷贝,详情见【Python】python深拷贝和浅拷贝(一)。浅拷贝示例如下:
x = [1, [2, 3], 4]
y = x.copy()
y -> [1, [2, 3], 4]
y[1].append(5)
x -> [1, [2, 3, 5], 4]
符号操作
| 符号 | 说明 |
|---|---|
| + | 列表拼接 |
| * | 重复元素 |
| in / not in | 成员判断 |
| [] | 索引取值 |
x[start_index: end_index] |
列表切片 |
具体示例如下:
# 列表拼接
x1 = [1, 2, 3]
x2 = [4, 5, 6]
x1 + x2 -> [1, 2, 3, 4, 5, 6]
# 重复元素,注意重复元素类似于浅拷贝之后再拼接
x = [1, 2, 3]
x * 3 -> [1, 2, 3, 1, 2, 3, 1, 2, 3]
x = [1, [2, 3], 4]
y = x * 3
y[1].append('other')
y -> [1, [2, 3, 'other'], 4, 1, [2, 3, 'other'], 4, 1, [2, 3, 'other'], 4]
# 成员判断
x = [1, 2, 3]
1 in x -> True
4 not in x -> True
# 列表切片,注意左闭右开
x = [1, 2, 3, 4, 5, 6]
x[1:4] -> [2, 3, 4]
列表的高阶实现
列表实现队列
队列的特点是先进先出,使用列表可以调用append方法添加元素,调用pop方法取出元素,示例如下:
x = []
x.append(1)
x.append(2)
x.append(3)
print(x.pop(0)) -> 1
print(x.pop(0)) -> 2
列表实现栈
栈的特点是后进先出,同样也可调用append方法和pop方法实现栈, 具体示例如下:
x = []
x.append(1)
x.append(2)
x.append(3)
print(x.pop()) -> 3
print(x.pop()) -> 2
但是列表作为队列的效率很低。因为在列表末尾添加和删除元素非常快,但在列表开头插入或移除元素却很慢(因为所有其他元素都必须移动一位)。最好使用 【collections.deque】来实现队列,deque可以快速从两端添加或删除元素。
del语句
del 语句按索引,而不是值从列表中移除元素。与返回删除值的 pop() 方法不同, del 语句也可以从列表中移除切片,或清空整个列表,具体示例如下:
x = [1, 2, 3, 4, 5, 6]
del x[0]
x -> [2, 3, 4, 5, 6]
# 删除切片的时候注意左闭右开问题
x = [1, 2, 3, 4, 5, 6]
del x[1:3]
x -> [1, 4, 5, 6]
高效列表
使用列表推导式
列表推导式是一种生成列表的方式,相比与传统的列表生成在底层进行了优化,具有了更高的性能,列表推导式的具体优势如下:
-
拥有更高的性能,先分配的内存再添加数据;
-
使用列表推导式语义上更加直观;
-
适用于类型转换、数据过滤;
传统方法
# 1亿数据
data = range(100000000)
%%timeit tmp = 0
some_list = list()
for i in data:
some_list.append(i)
4.75 s ± 59.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
使用列表推导式
# 1亿数据
data = range(100000000)
%%timeit tmp = 0
some_list = [i for i in data]
3.26 s ± 29.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
从上面的例子可以看出列表推导式节约了30%的运行时间,提升幅度已经很大了,随着数据量的提升,列表推导式的性能提升还会更显著。
嵌套列表推导式
x = [[i for i in range(3)] for j in range(3)]
x -> [[0, 1, 2], [0, 1, 2], [0, 1, 2]]
列表推导式除了可以更快地构建列表,还可以执行一些简单的过滤,示例如下:
# 传统方法
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
odd_numbers = filter(lambda x: x%2 != 0, nums)
list(odd_numbers) ->[1, 3, 5, 7, 9]
# Pythonic方法
odd_numbers = [i for i in nums if i % 2 != 0]
odd_numbers -> [1, 3, 5, 7, 9]
使用all或any
-
当对象为空列表的时候,
all方法的判断结果仍是True。 -
当对象为空列表的时候,
any方法的判断结果是False。
all方法在数据量很大的情况下有一定的性能提升,对比示例如下:
def check(l: List[int]) -> bool:
for i in l:
if not i:
return False
return True
# 准备数据
data = range(100000000)
%%timeit tmp = 0
check(data) -> 67.3 ns ± 0.628 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
%%timeit tmp = 0
all(data) -> 43 ns ± 0.998 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
总结
- 列表作为 Python 最基本的数据类型之一,在工作中十分常用,一般与其他数据类型搭配使用,用于构建数据结构;
- 定义列表可直接使用
[], 也可选择list()方法,如果从一个可迭代对象创建列表尽量使用列表推导式; - 列表可以实现队列,但是性能欠佳,最好使用【deque】来实现;
- 判断列表元素的时候可以考虑调用
any或者all,而不是自己的实现; - 文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,列表相关的知识点也可进行分享。
往期回顾
- 【Python学习002】函数参数
- 【Python学习001】内置类型
- 【Python】python深拷贝和浅拷贝(二)
- 【Python】python深拷贝和浅拷贝(一)