论文浅尝 | C3KG:中文常识对话知识图谱

笔记整理:张廉臣,东南大学硕士,研究方向为自然语言处理。
Citation: Li, D., Li, Y., Zhang, J., Li, K., Wei, C., Cui, J., & Wang, B. (2022). C3KG: A Chinese Commonsense Conversation Knowledge Graph. arXiv preprint arXiv:2204.02549.
动机
常识知识在机器与人类互动中至关重要。近年来,研究人员越来越着眼于推进关于常识知识的工作。其中,ATOMIC是一个包含很多推理知识的常识知识库,研究人员可以根据该知识库开发聊天机器人。但是在聊天机器人的应用上,目前存在着两大困难。一方面,对于一个事件关系对,ATOMIC含有多个配对结果,多个结果的存在会使聊天机器人对结果为何产生感到困惑。另一方面,ATOMIC中的知识元组是分离的,这些分离的元组会使聊天机器人很难推理应该用哪些知识的配对结果产生具有呈递性的连贯对话,例如,我们需要在对话中排除掉已经成为事件原因的配对结果。
为了解决这些问题,作者定义了四种新的对话流关系,即事件流、概念流、情感原因流和情感意图流,并依据此构建图谱C3KG。作者通过对收集到的大量日常对话信息进行注释,利用对话知识来增强ATOMIC。总的来看,基于ATOMIC的图谱构建工作有助于聊天机器人在ATOMIC中提取出有用的常识知识,并减少机器人对于对话结果的困惑。
贡献
文章的贡献有:
1.构建了一个新的汉语语料库,包含日常生活话题的多轮人类书面对话,这些语料具有丰富、高质量的注释;2.构建并将发布第一个大规模的中国常识对话知识图谱C3KG,其中包含4种独特的对话流边,用于存储从对话语料库中提取的对话知识;3.设计了一种图对话匹配方法,并基于常识对话图谱对两个典型任务进行了测试。
方法
⒈ 基于情景的多轮会话语料库构建
由于作者的目标是从真实对话中提取常见的对话信息,所以确保会话语料库的质量和提取方法的可靠性至关重要。作者使用的语料库并非基于杂乱的互联网数据,而是基于一个众包收集的多轮人类书面汉语对话数据。其具体构建方式如下:首先,研究团队雇佣了100名员工,并让这些员工随机配对,在给定的场景下用书面文字交流。每个场景都是一个描述给定对话的上下文的句子,通常涉及一些日常的事件。此外,这些被招募的员工还需要遵守某些规则,如“每句话的长度应超过6个汉字”,这对于确保收集对话的质量至关重要。经过培训以后,研究人员只保留了62名训练有素的工人,让他们完成产生数据的任务。随后,研究者们获得了三万两千次次高质量的一对一对话(总共65万条),涉及200个场景,15个日常话题。
获得数据后,研究人员雇佣一些专业人士对语料进行了情感标注,通过使用注释,作者提取到了对话知识,增强了对话图和基于图的对话建模。
⒉ 对ATOMIC的处理
由于收集到的会话信息是中文的,作者的目标也是建立一个中文会话知识图谱,从头构建知识图谱是比较费力的,所以作者采取的方法是以ATOMIC为基础,利用一种Pipeline方法将其翻译成中文,同时确保翻译产物适合会话方面的应用。具体来说,研究人员采用了规则替换和联合翻译的方法来提高翻译质量,翻译产物的名称被称为ATOMIC-zh。
⒊ 会话知识图谱的构建
由于开放域对话数据集中的数据包含大量口语表达和结构复杂的子句,研究人员开发了一个基于依赖解析的事件检测Pipeline方法来提取每个话语中的重要事件(ATOMIC-zh中的知识是基于事件的)。该方法的第一步是数据预处理,首先,每条数据被依照标点符号分割,然后在子文段层面上进行操作。经过过滤减少文本数据噪音,研究人员使用ltp41进行依赖句法分析和词性标注,并基于动词驱动和形容词驱动两种结构模式提取提及的事件。由于依照该方法产生的事件可能仍然包含多个动词和几个语义单位。在这种情况下,研究人员对数据进行了递归分解。为了做到这一点,事件中与词根相关的动词的数量被计算出来,以及这些动词相关的子树的深度。研究人员会根据计算结果确定是否需要使用阈值进行二次分解。如果需要,算法将递归地搜索原始依赖关系树中的动词,并用找到的动词替换关键动词。
在匹配方面,作者引入了Sentence-BERT(SBERT)对数据进行匹配。SBERT可以分别对两个给定的句子进行编码,并计算其表示之间的相似性,从而在大规模多对多匹配中高效地执行。同时,研究人员为了保证匹配性能,也同时对模型进行了微调处理。

图1 一个事件流Head-Head Edge构建示例
在图谱的边构建方面,研究人员提出了三种边来反映不同类型的对话流,并着重介绍了Head-Head Edge构建和Tail-Tail Edge的构建,一个事件流Head-Head Edge构建的图示如上图。下图展示了一个情感意向边(Emotion-Intent Edge)的构建过程。研究人员首先将“不舒服”的情绪与话语情感标签“悲伤”相匹配,随后发现在下一个文段中出现了吃药。因此,一个从“不舒服”到“吃药”的情感意向边被构建出来,并在边上添加了第二个话语“问”的意向标签,如下图所示

图2 一个情感意向边的构建示例
考虑到每一个话语中的情感和意图都可能是潜在的、不可预测的,研究人员还聘请了两名具有丰富心理学经验的专业人士,并请他们在情绪表达的高频场景(如失眠和学业压力)中标记情绪原因和意图。为了方便专业其工作,论文作者还构建了一个交互式注释工具,以便在我们的C3KG中更轻松地进行注释和探索。
实验
论文作者对图谱构建的过程和图谱进行了多次实验评估。在事件抽取和匹配方法层面,论文作者随机抽取了100个文段对其进行评估,Parsing为作者提出的方法, POS为使用基于词性标记的模板来提取事件的方法,而Simple为仅在匹配之前根据标点分割和过滤话语的方法。虽然这三种方法在没有微调的情况下具有相似的平均相似性,但Parsing在微调后与Simple和POS相比,性能都得到了较大提升,如图三所示:
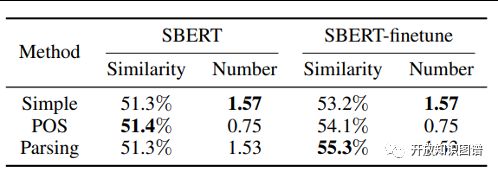
图3 匹配性能测试
为了验证新的对话流关系的质量和稳健性,研究人员使用了另一个开放域多轮中文对话数据集MOD,实验结果如下:

图4 MOD数据集测试结果
加入了ATOMIC-zh的对比结果显示出了该论文提出的事件流的有效性,其在文段匹配中显示出更高的连通性和更短的距离。此外,论文作者也提出了一些图谱任务,并将C3KG进行了任务测试。

图5 关于“生病”的图谱可视化
总结
本文提出并构建了一种中文常识对话知识图谱,从数据集的构建开始,作者采取多种方法,如定义新的对话流关系等将常识图谱构建完成,该工作有利于中文常识对话建模,为未来聊天机器人的发展做了铺垫。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。