Common sense Knowledge Aware Conversation Generation with Graph Attention阅读笔记
这篇文章是基于图注意力的对话生成,这篇文章的内容,简单概括来说就是一个concpetNet知识图谱(常识库),3个注意力,一个copy mechanism.将论文公式和论文的代码结合起来我觉得是一种很好的学习方法,所以下面我会这种方式介绍这篇论文。
备注:如有错误欢迎批评指证,欢迎评论转发
目录
1 背景
1.1 问题定义
1.2 知识图谱的引入
2 模型架构解释
2.1 overall architecture
2.2 KnowledgeInterpreter
2.3 KnowledgeAwareGenerator
3 three attention
3.1 attention 1——编码知识图
3.2 attention 2——解码器中挑选graph
3.3 attention 3——解码器中从graph挑选出实体
4 copy mechanism
1 背景
1.1 问题定义
input:{x1,x2,...,xn},output:{y1,y2,...,ym},其实就是一个single turn dialogue,就是一问一答。基本框架就是seq2seq其它的模型大都是在seq2seq的基础之上改进的。
1.2 知识图谱的引入
论文中使用的知识图谱是开源的concept Net,作者认为引入外部的常识库可以增强对input的理解,这样可以生成更加合理的回复。那么问题来了,怎么使用这个常识库,也就是很多个3元组的集合,由于这些3元组就是一些实体和关系,所以很自然的想到使用word embedding 对这些实体和实体关系进行encode,
2 模型架构解释
2.1 overall architecture

作者的整体框架还是seq2seq,然后在编码器的一端knowledge interpreter,这个就是使用atention机制从外部的知识库当中挑选我们需要的一些重要的知识,当然这首先有一个知识的构建和编码过程,在构建这个知识图的时候,作者使用input中的每一个token作为index从concpet net中进行检索,由于每一个实体可能与很多个实体产生关联,所以这里应该是检索一定的次数,检索所有的可能开销会很大,这里检索的应该是邻近的实体。对于知识图的编码在3.1中结合代码进行介绍。
2.2 KnowledgeInterpreter
 这个knowledge interpreter的意思是说,我们的input中的每一个token都可以从concept中构建多个知识图(有向图),但是我到底需要哪一个知识图,或者说我想更加关注哪一个知识图,这里就引入了一个interpreter的东西来对外部知识进行筛选、过滤。
这个knowledge interpreter的意思是说,我们的input中的每一个token都可以从concept中构建多个知识图(有向图),但是我到底需要哪一个知识图,或者说我想更加关注哪一个知识图,这里就引入了一个interpreter的东西来对外部知识进行筛选、过滤。
2.3 KnowledgeAwareGenerator

其实我觉得加了上面哪个interpreter就已经差不多了,然而作者在解码器的一端又加入了一个knowledge aware generator的东西,作者的意思大概是想既要在编码器的一端使用外部知识也要在解码器的一端使用外部知识。所以外部的信息重复使用了,这样重复使用可能还是有效果的。当然这个地方的外部知识的使用更加的精细,这里不但要挑选出更重要的知识图,还要挑选出更重要的实体,相比而言编码器的外部知识的使用就比较粗糙。
3 three attention
这里的每一个attention就是经典的attention机制,想必看过attention的一定不会陌生。下面待我一一详细说来。
3.1 attention 1——编码知识图
第一个attention是对知识图进行编码,得到每一个知识图向量graph vector(g_i)
论文公式:
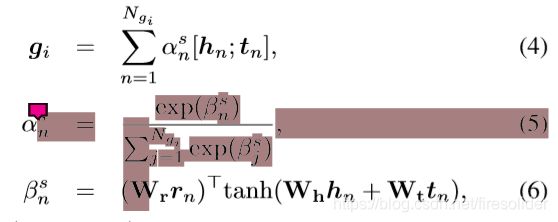
论文实现代码:
with tf.variable_scope('graph_attention'):
head_tail = tf.concat([head, tail], axis=3) # 将头实体和尾实体embedding进行拼接
head_tail_transformed = tf.layers.dense(head_tail, num_trans_units, activation=tf.tanh, name='head_tail_transform')
#拼接实体全连接,将嵌入映射到num_trans_units
# W_h·h_n
relation_transformed = tf.layers.dense(relation, num_trans_units, name='relation_transform') #关系嵌入的全连接层,将嵌入映射到num_trans_units
# W_t·t_n
e_weight = tf.reduce_sum(relation_transformed * head_tail_transformed, axis=3)
# (β_n)^s = W_r·r_n·tanh(W_h·h_n + W_t·t_n),经典的attention weight计算
alpha_weight = tf.nn.softmax(e_weight)
# (α_n)^s = softmax((β_n)^s) ,attention归一化
graph_embed = tf.reduce_sum(tf.expand_dims(alpha_weight, 3) * head_tail, axis=2)
# gi = sum((α_n)^s×[h_n,t_n]),attention vector/graph vector
3.2 attention 2——解码器中挑选graph
第二个attention是在t步的解码的时候挑选出更重要的graph
接下来的attention实现代码设计很长的函数,代码比较长就直接用论文公式了,其实实现和上面的差不多,就是rnn的解码比骄傲麻烦。

公式(9)中的g_i就是第一个attention计算出来的graph vector,st是解码GRU的状态,hidden_state,W_b和U_b是learnable parameters.上面的公式已经成为模板公式了,好像只要用到attention都要写上去。
算出来的attention vector (c_t)^g 可以衡量状态st和graph vector g_i的关系/对齐关系/aligment .
3.3 attention 3——解码器中从graph挑选出实体
第三个attention是在t步的解码的时候挑选出更重要的graph中,再次挑选出更重要的实体,
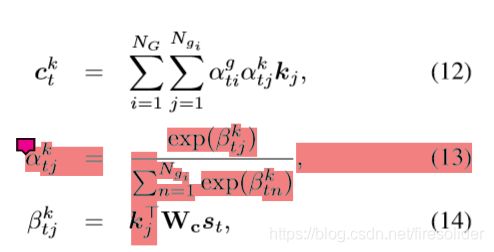
这个注意力机制和传统的注意力机制稍稍有所不同,这个ki是三元组嵌入,不同的地方在于最终的attention vector使用了两个attention weight,第一个attention weight (a_ti)^g是解码器状态s_t关注到的第i个graph的重要性,而(a_tj)^k是从状态s_t关注到的第j个三元组的重要性/权重。两者相乘就是先关注到特定的graph,然后从特点的graph中关注到特定的triple三元组。这里的设计就很有技巧性了。
4 copy mechanism
这里为了减少oov问题引入了一个叫做copy mechanism的东西。这里结合代码和公式进行解释。
论文公式:


论文实现代码:
def total_loss(outputs, targets, masks, alignments, triples_embedding, use_entities, entity_targets):
batch_size = tf.shape(outputs)[0]
local_masks = tf.reshape(masks, [-1])
logits = layers.linear(outputs, num_symbols, scope='decoder_rnn/%s' % name)
one_hot_targets = tf.one_hot(targets, num_symbols)
word_prob = tf.reduce_sum(tf.nn.softmax(logits) * one_hot_targets, axis=2)
# P_g(y_t=w_c) = softmax(W_o·a_t)
selector = tf.squeeze(tf.sigmoid(layers.linear(outputs, 1, scope='decoder_rnn/selector')))
# γ_t = sigmoid(V_o·a_t))
triple_prob = tf.reduce_sum(alignments * entity_targets, axis=[2, 3])
# P_e(y_t=w_e) = (α_ti)^g ·(α_tj)^k
# (α_ti)^g is the probability of choosing knowledge graph gi at step t
# 确定挑选哪个图
# (α_tj)^k is the probability of choosing triple τj from all triples in graph gi at step t.
# 确定挑选哪个三元组
ppx_prob = word_prob * (1 - use_entities) + triple_prob * use_entities
# P(y_t) = P_g(y_t=w_c)*(1-q_t) + P_e(y_t=w_e)* q_t
#上下两个分布的区别就是多了一个ues_entities
final_prob = word_prob * (1 - selector) * (1 - use_entities) + triple_prob * selector * use_entities
# P(y_t) = P_g(y_t=w_c)*(1-γ)*(1-q_t) + P_e(y_t=w_e)* γ_t* q_t
final_loss = tf.reduce_sum(tf.reshape( - tf.log(1e-12 + final_prob), [-1]) * local_masks)
ppx_loss = tf.reduce_sum(tf.reshape( - tf.log(1e-12 + ppx_prob), [-1]) * local_masks)
sentence_ppx = tf.reduce_sum(tf.reshape(tf.reshape( - tf.log(1e-12 + ppx_prob), [-1]) * local_masks, [batch_size, -1]), axis=1)
selector_loss = tf.reduce_sum(tf.reshape( - tf.log(1e-12 + selector * use_entities + (1 - selector) * (1 - use_entities)), [-1]) * local_masks)
# (20)的后面两项
# q_t* γ_t) + (1-q_t)*(1-γ_t)
loss = final_loss + selector_loss
total_size = tf.reduce_sum(local_masks)
total_size += 1e-12 # to avoid division by 0 for all-0 weights
return loss / total_size, ppx_loss / total_size, sentence_ppx / tf.reduce_sum(masks, axis=1)备注:
未完待续!