计算机视觉论文速递(十)ViT-LSLA:超越Swin的Light Self-Limited-Attention

Transformer在广泛的视觉任务中表现出了竞争性的表现,而全局自注意力的计算成本非常高。许多方法将注意力范围限制在局部窗口内,以降低计算复杂性。然而,他们的方法无法节省参数的数量;同时,自注意力和内部位置偏差(在softmax函数内部)导致每个query都集中在相似和接近的patch上。
因此,本文提出了一种Light Self-Limited-Attention(LSLA),它包括轻Light Self-Attention机制(LSA)以节省计算成本和参数数量,以及Self-Limited-Attention(SLA)以提高性能。
首先,LSA用X(原点输入)替换自注意力的K(key)和V(value)。将其应用于具有编码器结构和自注意力机制的视觉Transformer,可以简化计算。其次,SLA具有位置信息模块和有限关注模块。前者包含以调整自注意力分数的分布并增强位置信息。后者在softmax函数之后使用外部位置偏差来限制一些较大的注意力权重值。最后,提出了一种具有LSLA的分层视觉Transformer(ViT-LSLA)。
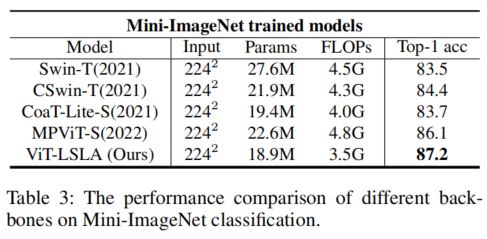
实验表明,ViT LSLA在IP102上达到了71.6%的Top-1精度(Swin-T的绝对改进2.4%);Mini-ImageNet上87.2%的Top-1准确率(Swin-T的绝对提高3.7%)。此外,它大大降低了FLOP(3.5GFLOP对Swin-T的4.5GFLOP)和参数(18.9M对276M Swin-TT)。
1、简介
Transformer的出现对自然语言处理(NLP)产生了深远影响。此外,视觉Transformer(ViT)与有线电视新闻网(CNN)相比表现出了良好的性能。受ViT的启发,提出了几种视觉Transformer。然而,对于各种视觉任务来说,采用原始的完全Self-Attention是不合适的,这导致了昂贵的计算成本(Self-Attention的计算复杂度与图像大小成二次方)。
为了解决这个问题,一方面,一种典型的方法是将全局Self-Attention的范围限制在局部地区。Swin Transformer 将自注意力的计算限制在局部窗口,并在两个连续块之间构建跨窗口连接。CSwin和Pale Transformer分别设计了十字形窗和Pale形窗。Shuffle Transformer提出了shuffle窗口。Axial DeepLab在高度轴和宽度轴上连续应用了两个轴向注意力层,改善了全局连接和高效计算。另一方面,最近的一些工作致力于Self-Attention的线性化。CoaT特别提出了一种分解注意力机制,其计算复杂度为通道的二次加权平均时间,而图像大小的线性加权平均时间。这些方法在一定程度上降低了计算成本;然而,它们不能保存参数的数量。
此外,许多以前的工作采用固定标度值来处理点积的大值。固定尺度可以防止softmax函数中的最小梯度,并将注意力分数的方差调整为1。由于它无法帮助Self-Attention掌握位置信息,在一些作品中,使用内部相对位置偏差来增强捕捉位置信息的能力。然而,注意力得分的值是每个向量与其他向量之间的相似性,这意味着相似向量具有较大的注意力得分。在将内部位置偏差添加到注意力得分之后,Self-Attention的计算可以被视为局部信息增强。这使得query倾向于关注相似且紧密的patch,而不是真正相关的patch。
本文提出了一种由LSA和SLA组成的LSLA。与自然语言处理(NLP)任务(例如机器翻译)中的编码器-解码器架构和交叉注意力机制不同,视觉Transformer在分类任务中具有仅编码器架构和自注意力机制。此外,机器翻译中有两种语言输入,但图像分类只需要处理图像输入。因此,LSA将Self-Attention计算从Q、K、V更改为Q、X、X,这可以显著降低Self-Attention的参数和计算成本。堆叠更多的Self-Attention块可能是有益的,这有助于Transformer更深入并获得更好的性能。
SLA进行如下:首先,与内部位置偏差配合的动态标度可以明确地指示位置信息(参见图3(a)中的蓝色斑块)。基于此,外部位置偏差可以有力地限制注意力权重的一些大值(参见图3(b)中的红色斑块),这有助于关注有意义的patch,而不是类似但不重要的patch。这些过程可以被视为局部信息集成,这有利于保留每个query patch的信息多样性。
通过LSLA,本文设计了一个具有ViT LSLA的分层视觉Transformer(如图1(a)所示),它比以前的方法实现了更好的性能,并显著降低了参数和计算成本。ViT LSLA(18.9M,3.5GFLOP)在IP102上实现了71.6%的Top-1分类准确率(Swin-T(27.6M,4.5GFLOPs)和MPViT-S(22.6M,4.8GFLOP)的2.4%和1.2%的绝对改进),在Mini-ImageNet上实现了87.2%的Top-2分类准确率,Swin-Tan和MPViT-S的3.7%和1.1%的绝对改善)。本文中的模型在两个特斯拉P100 GPU上进行了训练。
这项工作的贡献总结如下:
-
作为即插即用模块,提供了一个Light self-limited-attention mechanism(LSA)。Transformer通过在Self-Attention中应用LSA,可以方便地保存参数和FLOP的数量,而不会损失准确性。
-
引入了self-limited-attention mechanism(SLA)。基于位置信息,采用外部位置偏差来有效地限制大的注意力权重。因此,Transformer可以捕获真正有意义的信息,而不仅仅是具有高度相似性的信息。
-
使用上述组件建立简单的Transformer模型不仅可以显著降低计算成本和参数数量,而且可以显著提高性能。
2、Method
2.1、 Architecture
ViT LSLA的总体架构如图1(a)所示。接下来对于大小为H×W×3的输入图像,采用由2个3×3卷积层组成的stem块来获得大小为H/4×W/4×96的特征。整个模型由4个阶段组成。为了产生分层表示,使用patch merging layer来减少token的数量,并扩展两个相邻阶段之间的通道维度。
ViT LSLA块的粗略架构(见图1(b))遵循Swin Transformer块。Swin和ViT LSLA的块之间的区别在于,后者用LSLA取代了原来的自注意力机制。
如图1(c)所示,有LSLA模块的组件;本文的主要贡献是light self-attention mechanism(QXX)和由动态尺度(DS)和外部位置偏差(Bo)组成的self-limited-attention机制。以下各小节分别阐述了这些组成部分。

2.2、Light Self-Attention Mechanism
在引入light self-attention(LSA)之前,首先考虑了多层感知器(MLP)的FC(全连接层)。MLP必须在每层之后应用激活功能。否则,MLP将崩溃为线性模型:

其中, 是输入;H和O是隐变量和输出,两者之间没有非线性激活函数; , 是权重矩阵, , 是偏差。将等式(1)代入等式(2),可导出以下等式:

添加隐藏层需要模型跟踪和更新其他参数集,但这对提高性能没有好处。假设 ,。解推导为:
![]()
其中是权重矩阵,是偏差。它表明隐藏层和输出层可以折叠成一个单独的层。
受此启发,原来的自注意力机制也可以用同样的方式简化。
QX或QK:本部分首先阐述了K(key)如何容易地被X替换。为了简单起见,原始MSA的公式定义如下:
![]()
在等式(5)中,其中Q、K和分别是Query、Key和Value的矩阵;是窗口中的贴片数(本文中假设M为7),d是通道尺寸。此外,Q、K和V通过FC从X导出,为了简单起见,省略了FC的偏置:

其中 为原始输入, 、 、 是FC的权重矩阵。基于等式(5)和(6),可以数学公式化如下:

假设是,可以导出以下表达式:
![]()
设为,等式(7)简化为:
![]()
注意,也可以通过FC从X导出;和都可以在训练过程中被优化。总之,相当于;设为,则等式(5)可以改写为:
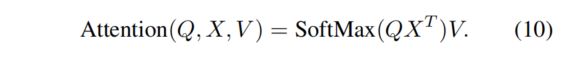
QXV或QXX:同样,QXV也可以以相同的方式还原为QXX。等式(10)简化为:

根据等式(6),可以导出以下等式:
![]()
用X代替V的Transformer性能较弱是合理的。
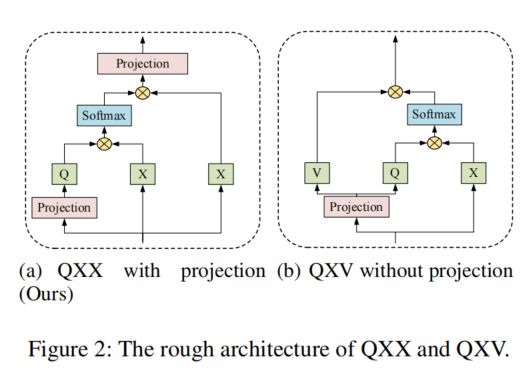
然而,在MSA模块的末端应用了一个线性投影(见图2(a)),这就是为什么可以用X替换V的原因。让这个线性投影的权重矩阵为。可导出以下方程:

假设是,可以表示为:
![]()
因此,可以合理地得出的线性投影等价于最后一个();即,如图2(a)和2(b)所示,它们中的任何一个都可以被丢弃。本文选择了第一种方法;因此,Light Self-Attention(LSA)机制被定义为:
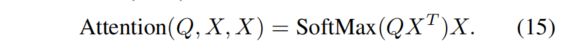
2.3、Self-Limited-Attention Mechanism
Self-Limited-Attention(SLA)具有位置信息模块和有限注意力模块。前者包含动态尺度和内部位置偏差,以增强位置信息,这可以标记需要限制的patch。基于此,后者在softmax函数之后采用外部位置偏差来限制之前token的注意力权重值。
位置信息模块:由于Transformer模型无法捕获位置信息,因此有必要为图像块应用一些相对或绝对位置。在计算相似性时,将相对位置偏差引入每个head。保持内部位置偏差(在softmax函数内)。固定标度(FS)的LSA公式为:
![]()
其中是查询维度;是内部位置偏差。
为了增强捕获位置信息的能力,设计了动态标度(DS)来代替固定标度。它与内部位置偏差一致,包含一组可学习的参数。具有DS的LSA可公式如下:
![]()
其中,表示query patch附近的patch具有较大的动态尺度和内部位置偏差值,如图3(a)和4(a)所示。这有助于query patch捕获每个图像块的位置信息。这可以被视为局部信息增强。
Limited-Attention模块:根据位置信息模块,LSA可以增强局部信息。然而,点积的值是每个向量与其他向量之间的相似性,这意味着相似向量具有很大的注意力权重。然而,这样的局部信息增强迫使自注意力集中在紧密且相似的patch上,包括patch本身。
为了保持每个query patch的信息多样性,使用了额外的外部位置偏差(softmax函数外),其结构与内部位置偏差相同。外部位置偏差与动态尺度和内部位置偏差相配合,可以极大地限制query patch附近的大注意力权重。

如图3(b)和4(b)所示,第8个patch是查询。外部位置偏差会严重限制其邻近的注意力权重,尤其是其自身。但其他patch的注意力权重被保留。最后,LSLA公式如下:

很容易理解外部位置偏差的合理性。在图3(b)中,查询patch位于猫的耳朵,而显著的patch(金色patch)位于猫眼。这个过程可以看作是一个局部信息整合,它有助于自注意力捕捉显著的信息,而不是接近和相似的信息。
LSLA的代码如算法1所示。

3、实验
3.1、Image Classification


3.2、Ablation Study



