吴恩达机器学习课程笔记+代码实现(18)Python实现正则化的线性回归和偏差/方差(Programming Exercise 5)
Programming Exercise 5:Regularized Linear Regression and Bias v.s.Variance
Python版本3.6
编译环境:anaconda Jupyter Notebook
链接:实验数据和实验指导书
提取码:i7co
本章课程笔记部分见:应用机器学习的建议(Advice for Applying Machine Learning)
在本练习中,我们要实现正则化的线性回归,并且使用它来学习在不同的方差和偏差性能的模型
%matplotlib inline
#IPython的内置magic函数,可以省掉plt.show(),在其他IDE中是不会支持的
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid",color_codes=True)
import scipy.io as sio
import scipy.optimize as opt
from sklearn.metrics import classification_report#这个包是评价报告
加载数据集和可视化
data = sio.loadmat('ex5data1.mat')
data
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Fri Nov 4 22:27:26 2011',
'__version__': '1.0',
'__globals__': [],
'X': array([[-15.93675813],
[-29.15297922],
[ 36.18954863],
[ 37.49218733],
[-48.05882945],
[ -8.94145794],
[ 15.30779289],
[-34.70626581],
[ 1.38915437],
[-44.38375985],
[ 7.01350208],
[ 22.76274892]]),
'y': array([[ 2.13431051],
[ 1.17325668],
[34.35910918],
[36.83795516],
[ 2.80896507],
[ 2.12107248],
[14.71026831],
[ 2.61418439],
[ 3.74017167],
[ 3.73169131],
[ 7.62765885],
[22.7524283 ]]),
'Xtest': array([[-33.31800399],
[-37.91216403],
[-51.20693795],
[ -6.13259585],
[ 21.26118327],
[-40.31952949],
[-14.54153167],
[ 32.55976024],
[ 13.39343255],
[ 44.20988595],
[ -1.14267768],
[-12.76686065],
[ 34.05450539],
[ 39.22350028],
[ 1.97449674],
[ 29.6217551 ],
[-23.66962971],
[ -9.01180139],
[-55.94057091],
[-35.70859752],
[ 9.51020533]]),
'ytest': array([[ 3.31688953],
[ 5.39768952],
[ 0.13042984],
[ 6.1925982 ],
[17.08848712],
[ 0.79950805],
[ 2.82479183],
[28.62123334],
[17.04639081],
[55.38437334],
[ 4.07936733],
[ 8.27039793],
[31.32355102],
[39.15906103],
[ 8.08727989],
[24.11134389],
[ 2.4773548 ],
[ 6.56606472],
[ 6.0380888 ],
[ 4.69273956],
[10.83004606]]),
'Xval': array([[-16.74653578],
[-14.57747075],
[ 34.51575866],
[-47.01007574],
[ 36.97511905],
[-40.68611002],
[ -4.47201098],
[ 26.53363489],
[-42.7976831 ],
[ 25.37409938],
[-31.10955398],
[ 27.31176864],
[ -3.26386201],
[ -1.81827649],
[-40.7196624 ],
[-50.01324365],
[-17.41177155],
[ 3.5881937 ],
[ 7.08548026],
[ 46.28236902],
[ 14.61228909]]),
'yval': array([[ 4.17020201e+00],
[ 4.06726280e+00],
[ 3.18730676e+01],
[ 1.06236562e+01],
[ 3.18360213e+01],
[ 4.95936972e+00],
[ 4.45159880e+00],
[ 2.22763185e+01],
[-4.38738274e-05],
[ 2.05038016e+01],
[ 3.85834476e+00],
[ 1.93650529e+01],
[ 4.88376281e+00],
[ 1.10971588e+01],
[ 7.46170827e+00],
[ 1.47693464e+00],
[ 2.71916388e+00],
[ 1.09269007e+01],
[ 8.34871235e+00],
[ 5.27819280e+01],
[ 1.33573396e+01]])}
def load_data():
"""for ex5
d['X'] shape = (12, 1)
pandas has trouble taking this 2d ndarray to construct a dataframe, so I ravel
the results
"""
d = sio.loadmat('ex5data1.mat')
return map(np.ravel, [d['X'], d['y'], d['Xval'], d['yval'], d['Xtest'], d['ytest']])
X, y, Xval, yval, Xtest, ytest = load_data()
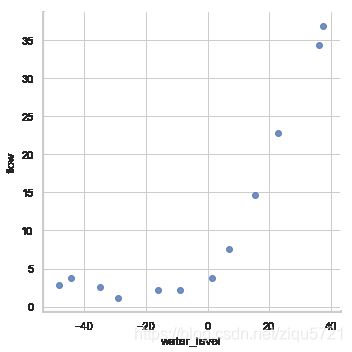
df = pd.DataFrame({'water_level':X, 'flow':y})
sns.lmplot('water_level', 'flow', data=df, fit_reg =False, size=5)
X, Xval, Xtest = [np.insert(x.reshape(x.shape[0], 1), 0, np.ones(x.shape[0]), axis=1) for x in (X, Xval, Xtest)]
代价函数

def cost(theta, X, y):
"""
X: R(m*n), m records, n features
y: R(m)
theta : R(n), linear regression parameters
"""
m = X.shape[0]
inner = X @ theta - y # R(m*1)
# 1*m @ m*1 = 1*1 in matrix multiplication
# but you know numpy didn't do transpose in 1d array, so here is just a
# vector inner product to itselves
square_sum = inner.T @ inner
cost = square_sum / (2 * m)
return cost
def regularized_cost(theta, X, y, l=1):
m = X.shape[0]
regularized_term = (l / (2 * m)) * np.power(theta[1:], 2).sum()
return cost(theta, X, y) + regularized_term
theta = np.ones(X.shape[1])
cost(theta, X, y)
303.9515255535976
regularized_cost(theta, X, y)
303.9931922202643
梯度

def gradient(theta, X, y):
m = X.shape[0]
inner = X.T @ (X @ theta - y) # (m,n).T @ (m, 1) -> (n, 1)
return inner / m
gradient(theta, X, y)
array([-15.30301567, 598.16741084])
正则化梯度
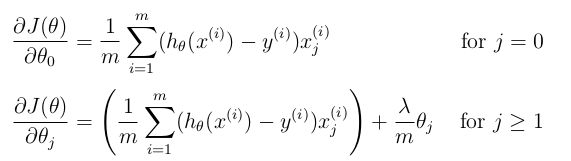
def regularized_gradient(theta, X, y, l=1):
m = X.shape[0]
regularized_term = theta.copy() # same shape as theta
regularized_term[0] = 0 # don't regularize intercept theta
regularized_term = (l / m) * regularized_term
return gradient(theta, X, y) + regularized_term
regularized_gradient(theta, X, y)
array([-15.30301567, 598.25074417])
拟合数据
正则化项 λ = 0 \lambda=0 λ=0
def linear_regression_np(X, y, l=1):
"""linear regression
args:
X: feature matrix, (m, n+1) # with incercept x0=1
y: target vector, (m, )
l: lambda constant for regularization
return: trained parameters
"""
# init theta
theta = np.ones(X.shape[1])
# train it
res = opt.minimize(fun=regularized_cost,
x0=theta,
args=(X, y, l),
method='TNC',
jac=regularized_gradient,
options={'disp': True})
return res
theta = np.ones(X.shape[0])
final_theta = linear_regression_np(X, y, l=0).get('x')
b = final_theta[0] # intercept
m = final_theta[1] # slope
plt.scatter(X[:,1], y, label="Training data")
plt.plot(X[:, 1], X[:, 1]*m + b, label="Prediction")
plt.legend(loc=2)
plt.show()

training_cost, cv_cost = [], []
1.使用训练集的子集来拟合应模型
2.在计算训练代价和交叉验证代价时,没有用正则化
3.记住使用相同的训练集子集来计算训练代价
m = X.shape[0]
for i in range(1, m+1):
# print('i={}'.format(i))
res = linear_regression_np(X[:i, :], y[:i], l=0)
tc = regularized_cost(res.x, X[:i, :], y[:i], l=0)
cv = regularized_cost(res.x, Xval, yval, l=0)
#print('tc={}, cv={}'.format(tc, cv))
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(np.arange(1, m+1), training_cost, label='training cost')
plt.plot(np.arange(1, m+1), cv_cost, label='cv cost')
plt.legend(loc=1)

特征数太少,欠拟合
创建多项式特征
def prepare_poly_data(*args, power):
"""
args: keep feeding in X, Xval, or Xtest
will return in the same order
"""
def prepare(x):
# expand feature
df = poly_features(x, power=power)
# normalization
ndarr = normalize_feature(df).as_matrix()
# add intercept term
return np.insert(ndarr, 0, np.ones(ndarr.shape[0]), axis=1)
return [prepare(x) for x in args]
def poly_features(x, power, as_ndarray=False):
data = {'f{}'.format(i): np.power(x, i) for i in range(1, power + 1)}
df = pd.DataFrame(data)
return df.as_matrix() if as_ndarray else df
X, y, Xval, yval, Xtest, ytest = load_data()
poly_features(X, power=3)
| f1 | f2 | f3 | |
|---|---|---|---|
| 0 | -15.936758 | 253.980260 | -4047.621971 |
| 1 | -29.152979 | 849.896197 | -24777.006175 |
| 2 | 36.189549 | 1309.683430 | 47396.852168 |
| 3 | 37.492187 | 1405.664111 | 52701.422173 |
| 4 | -48.058829 | 2309.651088 | -110999.127750 |
| 5 | -8.941458 | 79.949670 | -714.866612 |
| 6 | 15.307793 | 234.328523 | 3587.052500 |
| 7 | -34.706266 | 1204.524887 | -41804.560890 |
| 8 | 1.389154 | 1.929750 | 2.680720 |
| 9 | -44.383760 | 1969.918139 | -87432.373590 |
| 10 | 7.013502 | 49.189211 | 344.988637 |
| 11 | 22.762749 | 518.142738 | 11794.353058 |
准备多项式回归数据
- 扩展特征到 8阶,或者你需要的阶数
- 使用 归一化 来合并 x n x^n xn
- don’t forget intercept term
def normalize_feature(df):
"""Applies function along input axis(default 0) of DataFrame."""
return df.apply(lambda column: (column - column.mean()) / column.std())
X_poly, Xval_poly, Xtest_poly= prepare_poly_data(X, Xval, Xtest, power=8)
X_poly[:3, :]
array([[ 1.00000000e+00, -3.62140776e-01, -7.55086688e-01,
1.82225876e-01, -7.06189908e-01, 3.06617917e-01,
-5.90877673e-01, 3.44515797e-01, -5.08481165e-01],
[ 1.00000000e+00, -8.03204845e-01, 1.25825266e-03,
-2.47936991e-01, -3.27023420e-01, 9.33963187e-02,
-4.35817606e-01, 2.55416116e-01, -4.48912493e-01],
[ 1.00000000e+00, 1.37746700e+00, 5.84826715e-01,
1.24976856e+00, 2.45311974e-01, 9.78359696e-01,
-1.21556976e-02, 7.56568484e-01, -1.70352114e-01]])
画出学习曲线
首先,我们没有使用正则化,所以 λ = 0 \lambda=0 λ=0
def plot_learning_curve(X, y, Xval, yval, l=0):
training_cost, cv_cost = [], []
m = X.shape[0]
for i in range(1, m + 1):
# regularization applies here for fitting parameters
res = linear_regression_np(X[:i, :], y[:i], l=l)
# remember, when you compute the cost here, you are computing
# non-regularized cost. Regularization is used to fit parameters only
tc = cost(res.x, X[:i, :], y[:i])
cv = cost(res.x, Xval, yval)
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(np.arange(1, m + 1), training_cost, label='training cost')
plt.plot(np.arange(1, m + 1), cv_cost, label='cv cost')
plt.legend(loc=1)
plot_learning_curve(X_poly, y, Xval_poly, yval, l=0)

过拟合
try λ = 1 \lambda=1 λ=1
plot_learning_curve(X_poly, y, Xval_poly, yval, l=1)
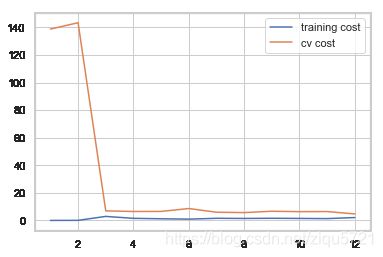
try λ = 100 \lambda=100 λ=100
plot_learning_curve(X_poly, y, Xval_poly, yval, l=100)

欠拟合
找到最佳的 λ \lambda λ
l_candidate = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
training_cost, cv_cost = [], []
for l in l_candidate:
res = linear_regression_np(X_poly, y, l)
tc = cost(res.x, X_poly, y)
cv = cost(res.x, Xval_poly, yval)
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(l_candidate, training_cost, label='training')
plt.plot(l_candidate, cv_cost, label='cross validation')
plt.legend(loc=2)
plt.xlabel('lambda')
plt.ylabel('cost')
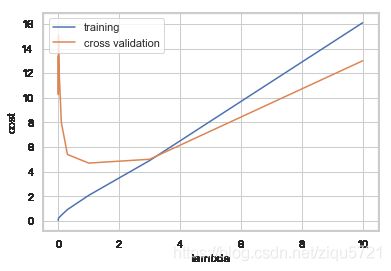
Text(0, 0.5, 'cost')
# best cv I got from all those candidates
l_candidate[np.argmin(cv_cost)]
1
# use test data to compute the cost
for l in l_candidate:
theta = linear_regression_np(X_poly, y, l).x
print('test cost(l={}) = {}'.format(l, cost(theta, Xtest_poly, ytest)))
test cost(l=0) = 10.122298845834932
test cost(l=0.001) = 10.989357236615056
test cost(l=0.003) = 11.26731092609127
test cost(l=0.01) = 10.881623900868235
test cost(l=0.03) = 10.02232745596236
test cost(l=0.1) = 8.632062332318977
test cost(l=0.3) = 7.336513212074589
test cost(l=1) = 7.466265914249742
test cost(l=3) = 11.643931713037912
test cost(l=10) = 27.7150802906621
调参后, λ = 0.3 \lambda = 0.3 λ=0.3 是最优选择,测试代价最小