NLP | 注意力机制Attention Mechannism图文详解及代码
包含了RNN,LSTM的示例。
1.注意力机制
注意力机制是深度学习的最新进展之一,特别是对于机器翻译、图像字幕、对话生成等自然语言处理任务。它是一种旨在提高编码器解码器(seq2seq)RNN 模型性能的机制。注意力被提出作为编码器-解码器模型限制的解决方案,该模型将输入序列编码为一个固定长度的向量,在每个时间步从该向量解码输出。这个问题在解码长序列时被认为是一个问题,因为神经网络难以处理长句子,尤其是那些比训练语料库中的句子长的句子。
当模型预测下一个单词时,它会在源语句中搜索一组位置,其中最相关的信息集中在这些位置。然后,该模型根据与这些源位置和所有先前生成的目标词相关联的上下文向量来预测下一个词。
注意力模型不是将输入序列编码为单个固定的上下文向量,而是开发一个上下文向量,专门针对每个输出时间步进行过滤。
从广义上讲,注意力是网络架构的一个组成部分,负责管理和量化相互依赖:
- 输入和输出元素之间(General Attention)
- 在输入元素内(Self-Attention)
虽然 Attention 确实在计算机视觉等深度学习的其他领域有应用,但它的主要突破和成功来自其在自然语言处理 (NLP) 任务中的应用。这是因为引入了注意力来解决机器翻译中的长序列问题,这也是大多数其他 NLP 任务的问题。
2.注意力如何实现?
Attention 的基本思想是,每次模型试图预测一个输出词时,它只使用集中了最相关信息的部分输入,而不是整个句子,即它试图对少数输入词给予更多的重视。
编码器的工作方式类似于编码器-解码器模型,但解码器的解码方式不同。从图片中可以看出,解码器的隐藏状态是使用上下文向量、先前的输出和先前的隐藏状态计算的,并且它对于每个目标词都有单独的上下文向量 c_i。这些上下文向量被计算为前向和后向激活状态和 alpha 的加权和,这些 alpha 表示输入对生成输出词的关注程度。
3.序列到序列模型中的注意力
大多数关于注意力机制的文章都会使用序列到序列(seq2seq)模型的例子来解释它是如何工作的。这是因为 Attention 最初是作为解决围绕 seq2seq 模型的主要问题的解决方案引入的,并取得了巨大的成功。如果您不熟悉 seq2seq 模型,也称为编码器-解码器模型
标准的 seq2seq 模型通常无法准确处理长输入序列,因为只有编码器 RNN 的最后一个隐藏状态被用作解码器的上下文向量。另一方面,注意力机制直接解决了这个问题,因为它在解码过程中保留并利用了输入序列的所有隐藏状态。它通过在解码器输出的每个时间步长到所有编码器隐藏状态之间创建一个唯一的映射来做到这一点。这意味着对于解码器的每个输出,它都可以访问整个输入序列,并且可以有选择地从该序列中挑选出特定的元素来产生输出。
因此,该机制允许模型根据需要将更多的“注意力”集中在输入序列的相关部分上。
4.注意力的类型

这两种类型的 Attention 的基本原理相同,但它们的区别主要在于它们的架构和计算。
4.1.Bahdanau Attention

第一种注意力,通常称为附加注意力,旨在通过将解码器与相关输入句子对齐并实施注意力来改进机器翻译中的序列到序列模型。在 Bahdanau 的论文[3]中应用 Attention 的整个逐步过程如下:
-
- 产生编码器隐藏状态 - 编码器产生输入序列 中每个元素的隐藏状态
- Calculating Alignment Scores 计算前一个解码器隐藏状态和每个编码器的隐藏状态(注意:最后一个编码器隐藏状态可以作为解码器中的第一个隐藏状态)
- Softmaxing the Alignment Scores - 每个编码器隐藏状态的对齐分数被组合并表示在单个向量中,然后进行softmaxed
- 计算上下文向量- 将编码器隐藏状态及其各自的对齐分数相乘以形成上下文向量
- 解码输出- 上下文向量与前一个解码器输出连接,并与前一个解码器隐藏状态一起馈入该时间步长的解码器 RNN以产生新的输出
- 该过程(步骤 2-5)对解码器的每个时间步重复自身,直到生成令牌或输出超过指定的最大长度
4.2.Luong Attention
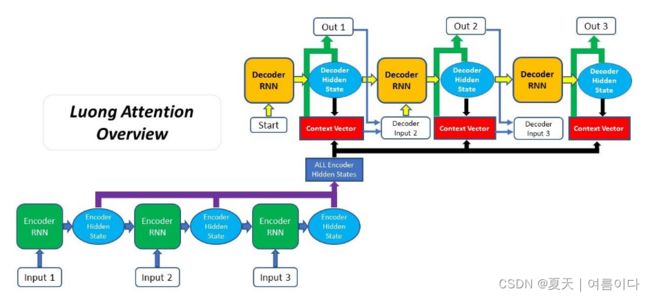
[4]论文中,被称为乘法注意力,建立在 Bahdanau 提出的注意力机制之上。Luong Attention 和 Bahdanau Attention 之间的两个主要区别是:
- 对齐分数的计算方式
- 在解码器中引入注意力机制的位置
与 Bahdanau 的一种相比,Luong 的论文提出了三种对齐评分函数。此外,Luong Attention 的 Attention Decoder 的一般结构不同,因为上下文向量仅在 RNN 为该时间步生成输出后使用。在完成 Luong Attention 过程如下:
- 产生编码器隐藏状态 - 编码器产生输入序列 中每个元素的隐藏状态
- 解码器RNN——之前的解码器隐藏状态和解码器输出通过解码器RNN为那个时间步 生成一个新的隐藏状态
- 计算对齐分数- 使用新的解码器隐藏状态和编码器隐藏状态,计算 对齐分数
- Softmaxing the Alignment Scores - 每个编码器隐藏状态的对齐分数被组合并表示在单个向量中,然后进行softmaxed
- 计算上下文向量- 将编码器隐藏状态及其各自的对齐分数相乘以形成上下文向量
- 产生最终输出——上下文向量与步骤 2 中生成的解码器隐藏状态连接起来,通过全连接层产生新的输出
- 该过程(步骤 2-6)对解码器的每个时间步重复自身,直到生成令牌或输出超过指定的最大长度
如上, Luong Attention 的步骤顺序与 Bahdanau Attention 不同。
5.点积注意力
注意力有很多种,其中,我们通过点积注意力来理解注意力,这在数学上是最容易理解的。在seq2seq用到的attention中,点积attention和其他attention的区别主要是中间公式的不同,机制本身也差不多。

上图展示了在解码器的第三个 LSTM 单元中预测输出词时注意力机制的使用。假设解码器的第一个和第二个 LSTM 单元已经经历了通过注意力机制预测 je 和 suis 的过程。在进入注意力机制的细节之前,我们先从上图中得到一个大致的概览。解码器的第三个 LSTM 单元尝试再次参考编码器所有输入字的信息来预测输出字。中间过程的解释暂时省略,这里重点介绍encoder的softmax函数。
softmax 函数的结果是一个数值,用于量化每个单词 I、am、a 和 student 在预测输出单词方面的帮助程度。上图中,Softmax函数的结果值的大小用红色矩形的大小来表示。矩形的大小越大,帮助量越大。当每个输入词对解码器预测的帮助程度被量化和测量后,它作为一条信息传输到解码器。在上图中,这是绿色三角形。结果,解码器更有可能更准确地预测输出单词。
![]() 1.获取注意力分数
1.获取注意力分数
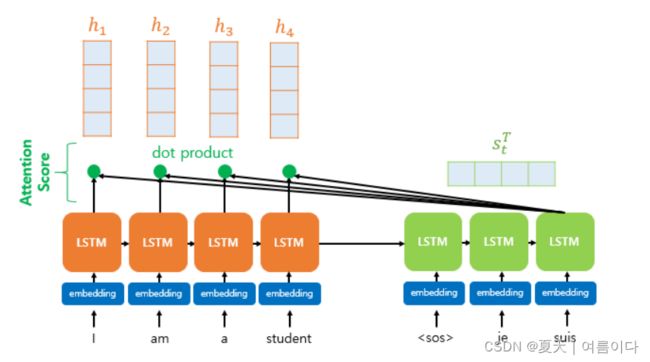
当编码器的时间步长分别为 1, 2, ... N 时,编码器的隐藏状态为H一,H2, ...Hñ比方说 解码器当前时间步 t 处解码器的隐藏状态s吨比方说 它还假设编码器的隐藏状态和解码器的隐藏状态具有相同的维度。在上图的情况下,编码器的隐藏状态和解码器的隐藏状态具有相同的维度,均为 4。
为了预测时间 t 的输出字,解码器的单元需要两个输入值:前一个时间 t-1 的隐藏状态和前一个时间 t-1 的输出字。
然而,注意力机制需要另一个值来预测输出词,这是一个称为注意力值的新值。预测第 t 个词的注意力值定义为a t .
在点积注意力中,要获得这个分数,s t 每个隐藏状态的转置和点积。即所有的注意力得分值都是标量。例如s t 编码器第i个隐藏状态的注意力分数的计算方法如下

分数函数的定义如下

s t 以及编码器所有隐藏状态的注意力分数的集合值。定义e t ,公式是:

![]() 2.通过softmax函数获得Attention Distribution
2.通过softmax函数获得Attention Distribution

e t 通过对 应用softmax函数,得到一个概率分布,其中所有值之和为1。这称为注意力分布,每个值称为注意力权重。例如,假设应用softmax函数得到的输出值I、am、a和student的注意力权重分别为0.1、0.4、0.1和0.4。他们的总和是 1。上图通过一个矩形的大小,可视化了每个编码器隐藏状态下注意力权重的大小。也就是说,注意力权重越大,矩形越大。
注意力分布,是解码器时刻 t 的注意力权重的集合α t 说的时候,α t 被定义为一个表达式:
3.通过对每个编码器的注意力权重和隐藏状态进行加权得到注意力值。

为了得到attention的最终结果,每个encoder的隐藏状态和attention权重值相乘,最后全部相加。总之,我们继续进行加权和。下面是Attention的最终结果。即attention value,即attention函数的输出值。一个 a t 显示表达式
这些注意值a t 也称为上下文向量,因为它通常包含编码器的上下文。在之前学习的最基本的 seq2seq 中,这与将编码器的最后一个隐藏状态称为上下文向量相反。
![]() 4. 连接t时刻的attention值和decoder的隐藏状态(Concatenate)
4. 连接t时刻的attention值和decoder的隐藏状态(Concatenate)
作为注意力函数最终值的注意力值a t已保存 其实当得到attention值的时候,attention机制就是at映射s t连接并生成一个向量。这个v t让我们定义 和这个v t 映射y^由于它被用作预测操作的输入,因此使用从编码器获得的信息y^可以更好地预测。这是注意力机制的核心。
5.成为输出层操作的输入s~t计算

与权重矩阵相乘后,经过双曲正切函数,是计算输出层的新向量。s~t得到 在不使用注意力机制的 seq2seq 中,输出层的输入在时间 t 处于隐藏状态。s吨另一方面,在注意力机制中,输出层的输入s~吨这意味着存在。
表示为表达式:WC是可学习的权重矩阵,bC是一种偏见。图中省略了偏置。
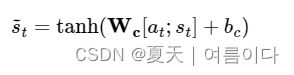
![]() 6.s~t用作输出层的输入
6.s~t用作输出层的输入
s~t用作输出层的输入以获得预测向量。

总结
Attention 机制彻底改变了创建 NLP 模型的方式,目前是大多数最先进的 NLP 模型中的标准装置。这是因为它使模型能够强调输入中的所有单词,并在制定响应时专注于特定单词。
参考文献
【1】https://medium.com/analytics-vidhya/https-medium-com-understanding-attention-mechanism-natural-language-processing-9744ab6aed6a
【2】https://blog.floydhub.com/attention-mechanism/
【3】https://arxiv.org/pdf/1409.0473.pdf
【4】https://arxiv.org/pdf/1508.04025.pdf