【深度学习】Deep Learning Tutorial学习笔记(1)
目录
- 神经网络初步实现
-
- 导入库
- 导入数据集
- 数据预处理
-
- flatten数据集
- 神经网络搭建
-
- 不定义flatten层的简单搭建
-
- 绘图
- 添加隐藏层
- 也可以简化运算
- 直接利用flatten隐藏层
- 练习
-
- 在 Keras 中构建我们的第一个神经网络来解决图像分类问题
神经网络初步实现
导入库
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
%matplotlib inline
导入数据集
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
len(X_train)
# 60000
len(X_test)
# 10000
X_train[0].shape
# (28, 28)
X_train[0]
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3,
18, 18, 18, 126, 136, 175, 26, 166, 255, 247, 127, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 30, 36, 94, 154, 170,
253, 253, 253, 253, 253, 225, 172, 253, 242, 195, 64, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 49, 238, 253, 253, 253, 253,
253, 253, 253, 253, 251, 93, 82, 82, 56, 39, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 18, 219, 253, 253, 253, 253,
253, 198, 182, 247, 241, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 80, 156, 107, 253, 253,
205, 11, 0, 43, 154, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 14, 1, 154, 253,
90, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 139, 253,
190, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 11, 190,
253, 70, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 35,
241, 225, 160, 108, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
81, 240, 253, 253, 119, 25, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 45, 186, 253, 253, 150, 27, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 16, 93, 252, 253, 187, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 249, 253, 249, 64, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 46, 130, 183, 253, 253, 207, 2, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 39,
148, 229, 253, 253, 253, 250, 182, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 114, 221,
253, 253, 253, 253, 201, 78, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 23, 66, 213, 253, 253,
253, 253, 198, 81, 2, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 18, 171, 219, 253, 253, 253, 253,
195, 80, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 55, 172, 226, 253, 253, 253, 253, 244, 133,
11, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 136, 253, 253, 253, 212, 135, 132, 16, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], dtype=uint8)
plt.matshow(X_train[2])
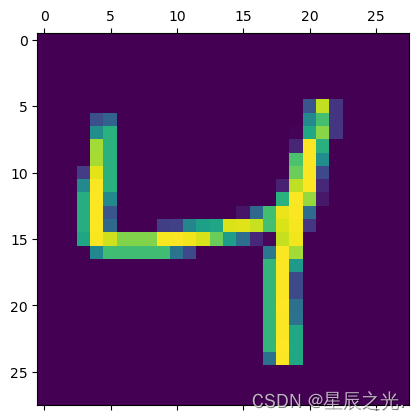
y_train[2]
# 4
y_train[:5]
# array([5, 0, 4, 1, 9], dtype=uint8)
X_train.shape
# (60000, 28, 28)
数据预处理
flatten数据集
X_train.reshape(len(X_train), 28 * 28)
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
X_train_flattened = X_train.reshape(len(X_train), 28 * 28)
X_train_flattened.shape
# (60000, 784)
X_test_flattened = X_test.reshape(len(X_test), 28 * 28)
X_test_flattened.shape
# (10000, 784)
X_train_flattened[0]
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 18, 18, 18,
126, 136, 175, 26, 166, 255, 247, 127, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 30, 36, 94, 154, 170, 253,
253, 253, 253, 253, 225, 172, 253, 242, 195, 64, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 49, 238, 253, 253, 253,
253, 253, 253, 253, 253, 251, 93, 82, 82, 56, 39, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 18, 219, 253,
253, 253, 253, 253, 198, 182, 247, 241, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
80, 156, 107, 253, 253, 205, 11, 0, 43, 154, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 14, 1, 154, 253, 90, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 139, 253, 190, 2, 0, 0,
...
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0], dtype=uint8)
神经网络搭建
不定义flatten层的简单搭建
model = keras.Sequential(
[keras.layers.Dense(10, input_shape=(784, ), activation='sigmoid')])
'''
1. Keras.Sequential([])
Sequential means having a stack of layers in my 神经网络,
因为它是一个stack,它将接受每一层作为一个element.
so the first element here is input
但是Keras有这个API: keras.layers.Dense
2. keras.layes.Dense(10 /*output_shape,输出的形状*/,
input_shape=(784,) /*shape of input,输入的形状*/,
activation='sigmoid' /*激活函数*/)
定义一个layer
dense means all the neurons here in one layer are connected
with erery other neuron in the second layer
'''
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
'''
compile 神经网络
model.compile(
optimizer = 'adam' /*optimizer,优化器*/,
loss = 'sparse_categorical_crossentropy' /*损失函数,稀疏分类交
叉熵,means our output class are categorical(分类的),类别基本上是0-9,输
出有10个类*/,
metrics = ['accuracy'] /*in the metrics(指标),goal:make
it more accurate*/
)
'''
model.fit(X_train_flattened, y_train, epochs=5)
# epochs:迭代次数
Epoch 1/5
1875/1875 [==============================] - 8s 3ms/step - loss: 0.4690 - accuracy: 0.8785
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.3035 - accuracy: 0.9160
Epoch 3/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2829 - accuracy: 0.9209
Epoch 4/5
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2730 - accuracy: 0.9242
Epoch 5/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2665 - accuracy: 0.9260
<keras.callbacks.History at 0x1e7d7998040>
model.evaluate(X_test_flattened, y_test)
# 评估测试集的准确性
# 313/313 [==============================] - 1s 3ms/step - loss: 0.2660 - accuracy: 0.9264
# [0.2659851908683777, 0.9264000058174133]
plt.matshow(X_test[1])
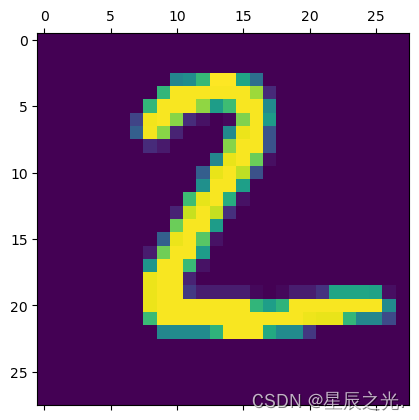
y_predicted = model.predict(X_test_flattened)
y_predicted[1]
313/313 [==============================] - 0s 524us/step
array([4.2747954e-01, 5.2588317e-03, 9.9945980e-01, 3.2661438e-01,
5.7969535e-10, 8.0700415e-01, 8.5705310e-01, 8.6088862e-13,
2.4246657e-01, 3.3684540e-09], dtype=float32)
np.argmax(y_predicted[1])
# 2
y_predicted_labels = [np.argmax(i) for i in y_predicted]
y_predicted_labels[:5]
# [7, 2, 1, 0, 4]
y_test[:5]
# array([7, 2, 1, 0, 4], dtype=uint8)
绘图
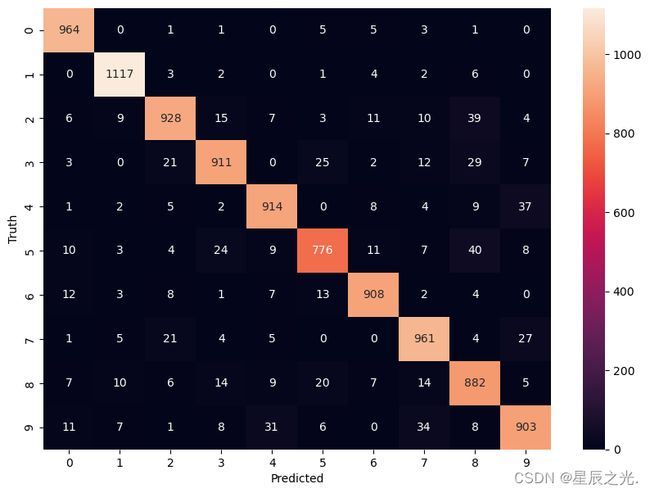
cm = tf.math.confusion_matrix(labels=y_test, predictions=y_predicted_labels)
cm
<tf.Tensor: shape=(10, 10), dtype=int32, numpy=
array([[ 964, 0, 1, 1, 0, 5, 5, 3, 1, 0],
[ 0, 1117, 3, 2, 0, 1, 4, 2, 6, 0],
[ 6, 9, 928, 15, 7, 3, 11, 10, 39, 4],
[ 3, 0, 21, 911, 0, 25, 2, 12, 29, 7],
[ 1, 2, 5, 2, 914, 0, 8, 4, 9, 37],
[ 10, 3, 4, 24, 9, 776, 11, 7, 40, 8],
[ 12, 3, 8, 1, 7, 13, 908, 2, 4, 0],
[ 1, 5, 21, 4, 5, 0, 0, 961, 4, 27],
[ 7, 10, 6, 14, 9, 20, 7, 14, 882, 5],
[ 11, 7, 1, 8, 31, 6, 0, 34, 8, 903]])>
import seaborn as sn
plt.figure(figsize=(10, 7))
sn.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Truth')
# Text(95.72222222222221, 0.5, 'Truth')
添加隐藏层
model = keras.Sequential([
keras.layers.Dense(100, input_shape=(784, ), activation='relu'),
keras.layers.Dense(10, activation='sigmoid')
])
# 添加隐藏层通常会提高性能,hidden_layer_shape< input_shape
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train_flattened, y_train, epochs=5)
Epoch 1/5
1875/1875 [==============================] - 2s 979us/step - loss: 0.2724 - accuracy: 0.9220
Epoch 2/5
1875/1875 [==============================] - 2s 995us/step - loss: 0.1236 - accuracy: 0.9638
Epoch 3/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0858 - accuracy: 0.9745
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0651 - accuracy: 0.9807
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0518 - accuracy: 0.9836
<keras.callbacks.History at 0x26cd73f41c0>
运行时间拉长了,效果好了一点
model.evaluate(X_test_flattened, y_test)
# 313/313 [==============================] - 0s 871us/step - loss: 0.0786 - accuracy: 0.9759
# [0.0786392092704773, 0.9758999943733215]
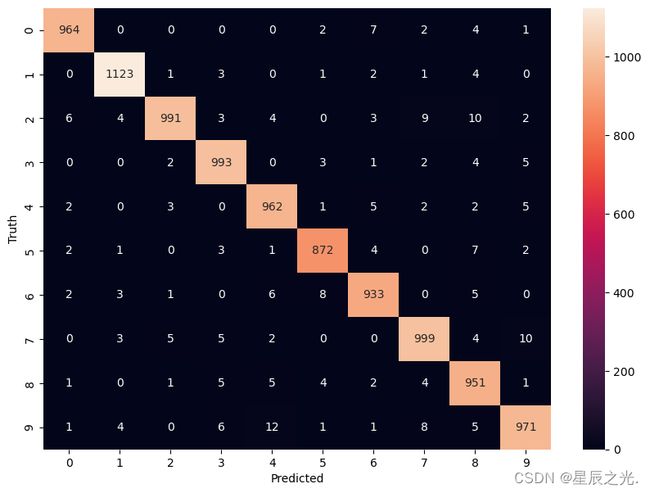
y_predicted = model.predict(X_test_flattened)
y_predicted_labels = [np.argmax(i) for i in y_predicted]
cm = tf.math.confusion_matrix(labels=y_test, predictions=y_predicted_labels)
plt.figure(figsize=(10, 7))
sn.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Truth')
# 313/313 [==============================] - 0s 750us/step
# Text(95.72222222222221, 0.5, 'Truth')
也可以简化运算
X_train = X_train / 250
X_test = X_test / 250
X_train_flattened = X_train.reshape(len(X_train), 28 * 28)
X_test_flattened = X_test.reshape(len(X_test), 28 * 28)
直接利用flatten隐藏层
# 如果不想create flatten array仅提供额外的环境,keras comes up with 一个名为flatten的空间层
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(100, input_shape=(784, ), activation='relu'),
keras.layers.Dense(10, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5)
Epoch 1/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.2749 - accuracy: 0.9219
Epoch 2/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.1225 - accuracy: 0.9635
Epoch 3/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0850 - accuracy: 0.9747
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0643 - accuracy: 0.9809
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0514 - accuracy: 0.9841
<keras.callbacks.History at 0x26cd8a2fe20>
练习
在 Keras 中构建我们的第一个神经网络来解决图像分类问题
我们将使用 keras fashion MNIST 数据集。 这包括 60000 张 28X28 像素图像和 10000 张测试图像,这些图像被分类为如下所示的 10 个类别之一
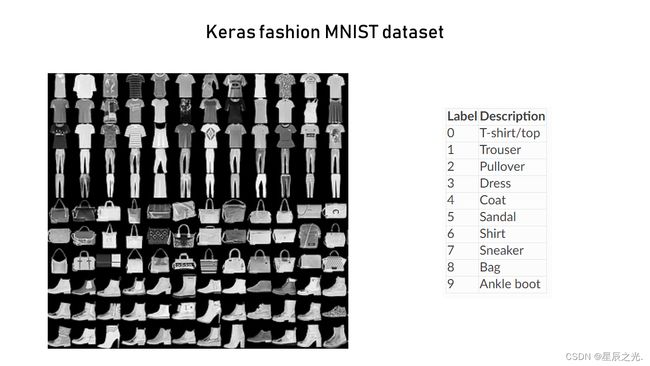
Each image is 28 x 28 pixel in dimension
使用来自 https://keras.io/datasets/ 的 keras mnist 数据集构建神经网络。 弄清楚,
- 可以为您提供最佳精度的隐藏层和每个隐藏层中的神经元的最佳数量
- 可选的精度分数