了解人机对话—聊天、问答、多轮对话和推荐
目录
一. 自然语言聊天
二. 任务驱动的多轮对话
三. 问答系统
四. 推荐
五. 中控决策模块(意图识别)
一. 自然语言聊天
顾名思义,就是不局限话题的聊天,即在用户的 query 没用明确的信息或服务获取需求(如 social dialogue)时系统做出的回应。自然语言聊天在现有的人机对话系统中,主要起到拉近距离,建立信任关系,情感陪伴,顺滑对话过程(例如在任务类对话无法满足用户需求时)和提高用户粘性的作用。
二. 任务驱动的多轮对话
用户带着明确的目的而来,希望得到满足特定限制条件的信息或服务,例如:订餐,订票,寻找音乐、电影或某种商品等。因为用户的需求可以比较复杂,可能需要分多轮进行陈述,用户也可能在对话过程中不断修改或完善自己的需求。此外,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。因此,任务驱动的多轮对话不是一个简单的自然语言理解加信息检索的过程,而是一个决策过程,需要机器在对话过程中不断根据当前的状态决策下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求,等等)从而最有效的辅助用户完成信息或服务获取的任务。
三. 问答系统
侧重于一问一答,即直接根据用户的问题给出精准的答案。问答更接近一个信息检索的过程,虽然也可能涉及简单的上下文处理,但通常是通过指代消解和 query 补全来完成的。问答系统和任务驱动的多轮对话最根本的区别在于系统是否需要维护一个用户目标状态的表示和是否需要一个决策过程来完成任务。由于人们使用语言的随意性和多样性,带来了问题理解的困难。给定一个问题,电脑要理解问题的类型(事实类,定义类,选择性,观点类等)和答案的类型(人、地点、机构、定义、电影名字,文字序列等等)。比如:
事实类问题:“谁是奥巴马的夫人?”
定义类问题:“什么是操作系统?”
YES-NO类问题:“萨达姆还活着吗?”
观点类问题:“多数美国人对枪支管制的看法是什么?”
比较类问题:“诺基业手机和苹果手机有什么区别?”
问答系统可以是针对某一个封闭领域的,也可以是无领域限定的, 而后者的难度更大。为了理解问题,计算机需要语义解析,把用户输入的问句转换为一个有结构的语义表达式,然后到相关数据和知识库中寻找答案。 很多时候,可能会有多个看似可行的答案候选,问答系统需要根据一个基于机器学习获得的排序系统进行优选。
问答系统的答案可以从结构化的知识库,或者非结构化的自然语言文档集合来获得,如web,社会关系网络,新闻等。知识库适合回答事实类的问题,而基于web的问答系统,也就是把问题丢给搜索引擎,在搜索结果里面直接抽取答案,适合于回答时效性很强的问题,如新闻类问题或很复杂的问题。社会关系网络适合回答主观类的问题,譬如“如何考入哈佛大学”,“怎样才能学好日语”等。由于这类问题在社区、社会关系网络里面有很多的讨论,经过信息抽取和问题匹配之后,可以用来回答相同或者相似的问题。除了以上三种智能体之外,还可以考虑众包智能,就是由系统把问题导引给该类问题的人(专家、附近的人、社会关系网络的好友)来完成。如能巧妙利用多智能架构,即可大幅度提升问答系统的精确度和覆盖面。
四. 推荐
前面的开放域聊天,任务驱动的多轮对话和问答系统本质上都是被动的响应用户的 query,而推荐系统则是根据当前的用户 query 和历史的用户画像主动推荐用户可能感兴趣的信息或者服务。
对话系统是个庞杂的系统模块,技术分解图如下:底层是依赖的基础技术系列,向上一层是利用基础技术构造的基础技术模块,中间是利用基础技术模块构造的子系统,上面两层是将子系统进行封装对外提供打包服务api应用层。
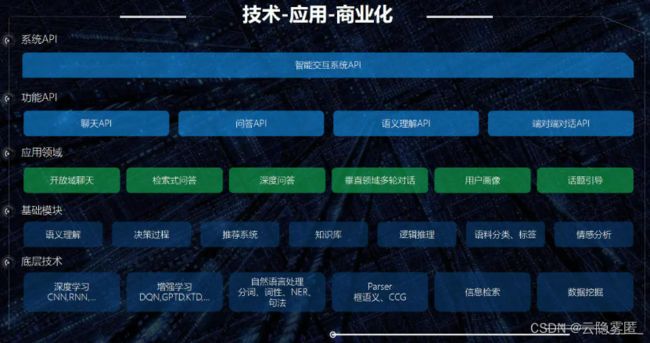
五. 中控决策模块(意图识别)
上述的四类系统各自要解决的问题不同,实现技术迥异,用一套系统实现所有功能是不现实的。通常要将上述功能整合在一个应用中,我们还需要一个中控决策模块。这个模块不仅负责需求和问题的分类,还包括任务之间的澄清、确认和跨领域的引导,所以最理想的技术实现也应该通过一个决策过程来完成。它相当于大脑,基于对用户对话的分析判断,发现并满足用户的直接和潜在需求,判断用哪个功能满足用户需求,同时在多次对话中,多维度建立用户画像,商业应用的人机对话系统根据应用的场景不同既可以是同时综合上述四类问题的复杂系统,也可以单纯解决其中一类问题。例如大家熟知的苹果 Siri、微软 Cortana、百度度秘等语音助手类产品就是集合上述四类问题综合系统(但是 Siri 和 Cortana 的聊天功能并不能算开放域,而是人工为高频的 query 编辑了对应的话术,当用户的聊天 query 不在预先配置的范围内时,系统则回复“我听不懂”之类的固定答案。而度秘的开放域聊天则是应用了更先进的基于海量数据的检索式聊天技术)目前的智能客服类系统则多以解决问答和推荐类问题为主;微软推出的“小冰”,包括后继推出的同类型产品日文版 Rinna、英文版 Zo 和 Ruuh,主打的就是开放域聊天;而许多订票,订酒店类的对话系统则是任务驱动的多轮对话的典型应用。
人们在交流过程中,聊天、多轮对话、问答的技能是穿插进行的。同时,为了体现多样性,答案所采用的句式,以及聊天的回复风格要根据场景和用户的特点发生变化。在微软小冰中,除了需要建立问答系统和聊天系统之外,还要根据用户输入的句子,决定是进入聊天还是进入问答。比如:
人: 你都不理我了。(聊天)
小冰: 我怎么不理你。(聊天)
人: 荣耀6plus多少钱? (问答)
小冰: 京东大哥说过是2,899元哦。(问答)
人: 你知道的真多呀。(聊天)
小冰: 我应该的呀。(聊天)
人: 你知道李敏镐吗 (问答)
小冰: 【一张李敏镐的图片】(问答)
而小冰的回复不仅仅要看当前的句子,还要看聊天的历史。比如另外一个例子:
人:请推荐一款手机。
小冰:你看看这款如何? 华为荣耀3X畅玩版,1099元。
人:我不要华为的,我要iPhone的。(系统需要知道产品类别没变,但是品牌变化)
小冰:那你看看这款iPhone如何呢?iPhone6, 5988元,64GB,金色。
人:我要能支持128G存储空间的。(系统要知道产品类别和品牌没有变化)
小冰:我看看。那你看看这款?iPhone6, 6488元,128GB。
人:算了,我还是要华为的吧。(系统需要知道产品类别没变,但是品牌变化)
小冰:那么这款华为P8,最新款,3800元。怎么样?
这就是系统需要对用户的输入进行理解以判断用户的意图。比如:“给我推荐一款性价比高的手机,要诺基亚的。”在对用户意图的理解基础上,要进行必要的对话,以便确认所有必要的信息,来决定接下来的动作,比如推荐,搜索,聊天还是问答。不过这个问题挑战也很大,它是目前自然语言理解的最核心的问题。我们需要耐心地循序渐进地推进研究。
[科普]任务驱动的多轮对话系统
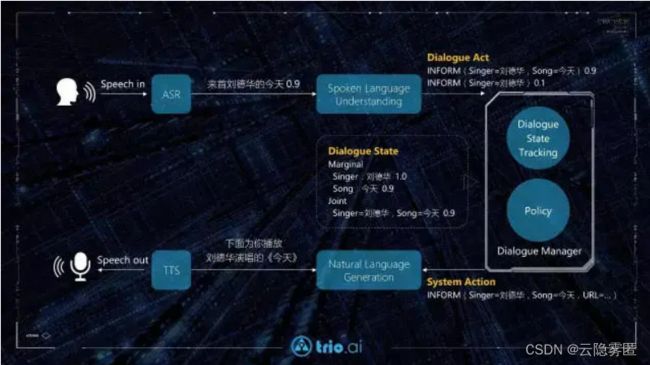
自然语言理解:将自然语言的 query 识别成结构化的语义表示。在对话系统中,这个结构化的语义表示通常被称作 dialogue act 由 communicative function 和 slot-value pairs 组成,其中 communicative function 表示 query 的类型(如:陈述需求,询问属性,否定,选择疑问,等等)而每个 slot-value pair 则表达一个限制条件(constraint),也可理解为用户目标的一个组成单元。
例如“我要西二旗附近的川菜”对应的 dialogue act 可以表示为 inform(foodtype=川菜,location=西二旗)。这里“inform”就是 communicative function,表示陈述需求,“foodtype=川菜”和“location=西二旗”是限制条件(slot-value pairs) 。常用的 communicative function 定义可以参考剑桥大学的对话系统中使用的集合[2],而语言学家 Harry Bunt 等人则总结出了一套 ISO-24617-2 标准包含56个 communicative function 的定义,以及它的扩展集 DIT++ 包含88种定义。但由于 ISO-24617-2 和 DIT++ 体系过于复杂,通常的任务驱动类对话系统只用到其中很小一个子集就足够满足需求了,不过感兴趣的读者可以参考 DIT++ 网站(1)。
由于对话系统更关注口语处理,而且通常是处理经过了语音识别后的口语,所以在这个领域,我们通常说 Spoken Language Understanding(SLU),以突出与广义的自然语言理解的不同,并蕴含了对非严谨语法和语音识别错误鲁棒的问题。
对话状态跟踪:英文中这个概念叫 Dialogue State Tracking(DST)。概括的说,对话状态跟踪就是根据多轮的对话来确定用户当前的目标(user goal)到底是什么的过程。为了更好的理解这个过程,我们先来看看什么是对话状态。一个对话状态中,最主要的信息是用户的目的,即 user goal。用户目的的表示形式是一组 slot-value pairs 的组合。
概率分布,称作置信状态(belief state或者belief),对话状态跟踪有时也称作置信状态跟踪(belief state tracking)。用户的目的在一个置信状态中的表示可以分为两部分:首先每个 slot 上都可以有多个可能的 value,每个 value 对应一个置信概率,这就形成了每个 slot 上的边缘置信状态(marginal belief);然后这些可能的 slot-value pairs 的组合的概率分布就形成的联合置信状态(joint be仍以图1中3-6行的对话为例,当对话进行到第3行时,用户的目的是“occasion=跑步”,到第5行时,这个目的就变成了“occasion=跑步,language=英文”。对话状态中还可以记录完成对话任务所需的其他额外信息,例如用户当前询问的属性(requested slots),用户的交互方式(communication method),和用户或系统的历史对话动作(dialogue history)等等。

此外,应注意到无论 ASR 或者 SLU 都是典型的分类问题,既然是分类就会有误差,于是这给任务驱动的对话系统引入了一个在不确定性环境下决策的问题(planning under uncertainty)。虽然最终的决策是由下面要介绍的对话策略完成的,但是对话状态需要为后面的决策提供依据,也就是如何刻画这个不确定性的问题。要解决这个问题,首先我们希望 ASR 或 SLU(或两者)在输出分类结果的同时输出一个置信度打分,最好还能给出多个候选结果(n-best list)以更好的保证召回。然后对话状态跟踪模块在上述置信度和 n-best list 的基础上,不仅需要维护一个对话状态,而是估计所有可能的对话状态的 belief),也就是用户完整目的的概率分布。通常对话系统的决策过程需要参考这两部分信息才能找到最优的对话策略。
对话策略:即 policy,是根据上面介绍的置信状态来决策的过程。对话策略的输出是一个系统动作(system action)。和用户的 dialogue act 类似,系统动作也是一个由 communicative function 和 slot-value pairs 组成的语义表示,表明系统要执行的动作的类型和操作参数。“每次决策的目标不是当前动作的对与错,而是当前动作的选择会使未来收益的预期(expected long-term reward)最大化”。
自然语言生成:natural language generation(NLG)的任务是将对话策略输出的语义表示转化成自然语言的句子,反馈给用户。